
英特尔IDF2011在风和日丽的13日终于落下帷幕。本届IDF以“智无界,芯跨越”(Compute Continuum and Beyond)为主题,将进一步展示英特尔如何通过从硬件、平台到软件和服务全面的计算解决方案,推进个性化互联网发展;同时面向中国市场如何支持本地合作伙伴创新,助力新一代信息技术等战略性新兴产业发展。而回顾本次IDF,依然有很多情景让我们觉得身临其境,再先进的技术最后也只有一个用处,那就是应用在改变大家的生活当中。

在此次的IDF上,借助内容丰富的主题演讲、技术课程和技术展示将Intel在技术与研发方面的最新成果加以诠释,推动用户走在科技发展的最前沿。其中,作为英特尔在2011年的创新---第二代英特尔® 酷睿™处理器,代号 Sandy Bridge的相关主题讲座将成为此次IDF的重头之一。
尽管SandyBridge平台早在年初就已发布,但对于多数用户而言英特尔仅提升了概念性认识。至于在实际应用细节方面的实现并没有明确的透露。而在此次IDF 2011论款上包括Intel首席高级工程师Opher Kahn,首席多媒体工程师Hong Jiang博士等多位资深专家在现为广大的与会者就Sandy Bridge平台的微架构、图形处理单元、多媒体优化以及高清图形处理方面的设计思路和性能体验进行了全面的解读。
英特尔继续履行其坚定的承诺,籍由下一代微架构代号Sandy Bridge 来推动处理器能力和指令集的发展。这一革命性的微架构构建于32 纳米制程技术之上,在提高能效的同时,具有更卓越的性能和能力。整合显示核心是Sandy Bridge处理器的一大改进。

Sandy Bridge微构架采用了可扩展的环形互连架构,将内核、最后一集高速缓存LLC和系统代理互连在一起,并且通过环上的数据存取总是选择最短路径,这样可以最小化延迟。另外,环形的互连架构让Sandy Bridge具有更高的可扩展性,可以支持大量的处理器。Sandy Bridge架构的优势集中在:能效,性能优化,联合CPU进行了优化,增强的固有优势和媒体性能。

其前端微架构的处理顺序为:32K一级缓存>预译码>指令队列>译码器>分支预测单元。其中一级缓存为32KB的8路相连指令高速缓存,译码器部分包含4个译码器,每个时钟周期可处理器4条指令,指令队列处理方式包括微融合和宏融合,可将多条指令时间打包为一条“微操作”或将多对指令融合为一条复杂的“位操作”,译码流水线支持每个时钟周期16个字节。

此外,在前端微架构处理器单元中还增加了一个译码微操作高速缓存,称之为0级(L0)指令高速缓存,代替了指令字节,对于大多数应用高达80%的命中率,此外,新架构还带来了更高的指令带宽和更低的延迟。译码高速缓存可以在每个时钟周期递送32字节,更多时钟周期可以保持每个周期4条指令,并能够缝合控制流程间的分支,从而达到更高的效能。
整合显示核心可说是是Sandy Bridge处理器的又一改进。与Westmere处理器所使用的MXM技术不同,Sandy Bridge处理器率先实现了将显示模块完全集成于芯片内部,并允许其通过Ring Bus(环形总线)与处理器模块共享三级缓存,以提升整体性能。

全新的Sandy Bridge图形核心采取了统一的显卡-CPU电源管理,可在CPU和显卡之间的资源分配上达到最优决策,从而提升效能,在显卡中使用了CPU登记的电源管理技术。独立的显卡和CPU电源控制允许电源按工作量需求进行分配,其电压和时序都是独立于CPU的。

固定的模块计算能达到最优平衡,在3D管道中每个点都有外在的固定功能模块,从而达到低延时、高吞吐量、简单的驱动编程模型,同时释放着色器,令其专注于渲染工作。
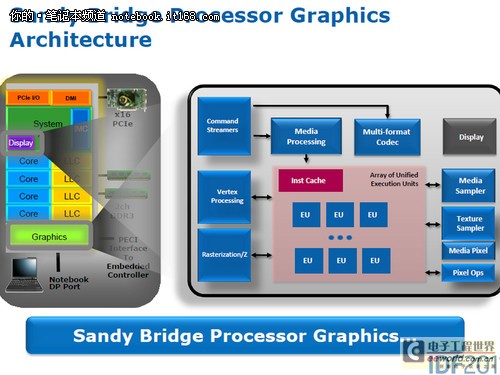
特别是新一代的EU拥有更大的寄存器文件以提高并行度和复杂着色器的执行效率,对深度嵌套条件也能有效优化,数学计算能力提高了4~20倍,新的指令集与API、ISA一一对应,从而在同频率下达到更高效率。固定模块的设计去掉了正交状态,与上代产品相比,驱动运行时间大幅降低,释放了CPU负载,将能量更多分配到显卡上。

比如在高清视频解码方面,英特尔所采用的支持多格式编解码器---MFX则是一种专用并行引擎。该引擎除了支持MPEG2、VC1以及AVC等常见编码格式还提供了对立体3D(MVC)的支持。而凭借MFX引擎的有力支持,CPU本身的负载也得到了进一步优化。

与上一代睿频加速1.0技术相比,睿频加速2.0技术的设计方向更多的针对多线程应用,不仅能够提供更高的多线程加速频率,而且调节机制更具弹性。当启动一个运行程序后,处理器会自动加速到合适的频率,而原来的运行速度会提升 10%—20% 以保证程序流畅运行;应对复杂应用时,处理器可自动提高运行主频以提速,轻松进行对性能要求更高的多任务处理;当进行工作任务切换时,如果只有内存和硬盘在进行主要的工作,处理器会立刻处于节电状态。这样既保证了能源的有效利用,又使程序速度大幅提升。

而值得注意的是,虽然设计在同一个芯片上,但是Sandy Bridge的CPU和GPU使用分别的电压和频率,共同分担芯片的整体功耗,通过功耗预算,CPU和GPU之间的调整使得在不同应用中始终保持最佳的分配,当CPU负载重时,GPU的能耗则相应降低,反之亦然。
关键字:英特尔 IDF2011 SandyBridge平台
在多媒体指令集方面,Sandy Bridge增加了Intel AVX指令集,使用了新的执行群集、存储器群集,可以扩展SSE浮点指令集到256bit的操作数,采用新的无损源语法和矢量运算,是面向低功耗的架构,矢量对于许多应用语言都是自然的数据类型,更宽的矢量和无损源语可用更少的指令详细描述更多的工作,使得现有工作得到有效扩展。Sandy Bridge的浮点运算能力大幅增加。AVX指令集可以利用2组128bit执行栈,令执行群集重新使用现有数据路径达到双重使用的目的。

在渲染的时候,光线跟踪也好,光能传递也好都需要大量的计算,这些工作都是由CPU提供的。而核内显卡在3D管道中每个点都有外在的固定功能模块,从而达到低延时、高吞吐量、简单的驱动编程模型,同时释放着色器,令其专注于渲染工作。

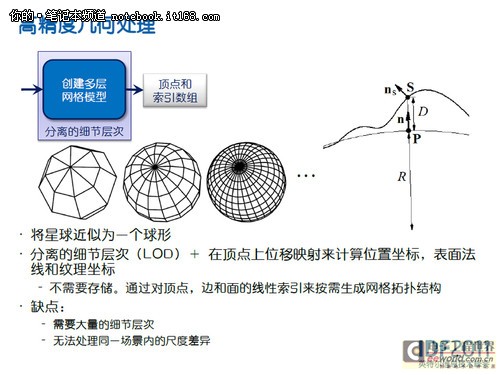
高精度星球浏览器的现场演示
除了核心显示在设计上的优势,英特尔的技术人员特别演示了“高精度星球浏览器”的应用案例。无论是在第二代英特尔酷睿i5还是i7处理器中,其内建的核心显卡均可以在高负荷的应用下完成星球整体以及地表的图形建模与高精度实时渲染。在高符合的渲染过程中,第二代酷睿处理器所采用双精度英特尔 高级矢量扩展指令集(AVX)则是凭借四线程、64位的优化能力大大提升了整个过程的执行速度,而这一优势是上一代产品所不具备的。
英特尔早在今年第一季度正式发布基于Sandy Bridge架构设计的处理器产品,事实上早在去年9月底的IDF 2009旧金山站上,英特尔的高管StephenSmith就已经拿出了桌面和移动版本的Sandy Bridge处理器实物,要知道那个时候甚至就连现在的32nm Westmere还没有正式发布呢,英特尔也借此表达了充分贯彻Tick-Tock策略的决心。

而时至今日,在新一代SNB平台已经全面捕货的同时时候,我们看到作为Nehalem的继任者,在实际应用方面,代号为Sandy Bridge的处理器在硬件特性方面还有着更多成长空间。凭借全新的处理架构,更加智能的睿频技术,全新的AVX指令集,SNB可在家庭娱乐、日常办公甚至服务器市场有着更多值得惊喜的表现,特别是其核内显卡在图形以及并行处理应用的改善让我们对这一架构发展有着更多的期待。