
文献标识码: A
文章编号: 0258-7998(2011)05-0110-04
一个典型的说话人识别系统提取的说话人特征通常为时变特性参数如梅尔倒谱系数MFCC(Mel-Frequency Cepstrum Coefficients)[1]、感知线性预测系数PLP(Perceptual Linear Prediction)[2]或韵律特征[3]。然而,实际使用时由于受到噪音干扰,或者训练与识别传输通道不匹配,识别系统通常不能表现良好[4]。目前解决这一问题的手段主要集中在特征域、模型域和得分域。现有特征域鲁棒性处理方法主要有:RASTA滤波[5]、倒谱均值归一化(CMN)[6]、直方图均衡[7]和倒谱规整[8-11]等。这些算法通常以在识别前增加额外的运算来换取鲁棒性的提高,如统计概率密度分布及计算各阶矩等。
本文算法主要从特征域入手,旨在减少识别阶段运算时间的同时提高识别系统的鲁棒性。参考文献[12]采用了观察值的各阶矩和中心矩作为段级特征,并与模型结合,在不显著影响识别率的情况下提高了识别速度。其缺点是,采用段级特征与采用帧级特征相比较识别率较低。参考文献[13]提出了一种改进的PCA方法用于掌纹识别,通过提取更有利于分类的基向量,提高了降维后特征的鲁棒性。本文结合了两者的优点,提出了一种基于PCA的段级特征PCAULF(PCA based Utterance Level Feature)提取算法。该算法特点如下:
(1)以段级特征代替帧级特征,可减少识别过程中模板匹配的次数,通过减少运算量来提高识别速度;
(2)在段级特征降维时引入改进的PCA算法,一方面实现了数据的降维,既抑制了噪声对识别系统的影响,又提高了识别的速度;另一方面,选择更利于分类的特征向量组成变换矩阵,提高识别系统的鲁棒性。
实验结果表明,在三种不同噪声背景下进行测试比对,段级特征获得了较高的识别率和较快的识别速度。
1 段级特征提取算法
1.1 段级特征的定义
由于语音的短时平稳特性,可以考虑在一段语音中提取特征,这样就使得同样的语音长度用更少的语音特征去描述,该特征被称为段级特征。它是和传统的按帧提取语音特征相对应的一个概念。段级特征的一般表示形式是: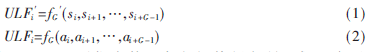
其中,ULFi、ULFi′代表第i个段级特征矢量,式(1)表示ULFi′从连续的G帧语音信号s中直接提取,式(2)表示ULFi从连续的G个帧级特征矢量a中提取。使用段级特征的关键在于段长G的选取和函数fG(·)的选取。首先讨论函数的选取,段级特征是观察值的函数。本文中,fG(·)主要包括以下两个步骤:
(1)以G为段长、Ginc为段移,将G个帧级特征矢量组合成超矢量。组成超矢量的操作类似于对数据的取帧操作,如图1所示。
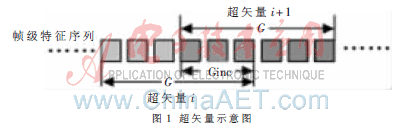
(2)采用改进的主成分分析方法对超矢量进行降维,得到段级特征。
1.2 PCA方法
主成分分析PCA(Principal Component Analysis)是一种掌握事物主要矛盾的统计分析方法,它可以从多元事物中解析出主要影响因素,简化复杂的问题。PCA假定具有大变化的方向的数据比有很少变化的方向上的数据携带有更多的信息,因而它寻找具有最大方差的那些称之为主轴的方向来表征原始数据。计算主成分的目的是在最小均方误差意义下将高维数据投影到较低维空间。
的形式有效表示X。其中,通过K-L变换(Karhunen-Loeve Transform)计算相互正交的一组基向量,可以得到P。
具体的PCA分析步骤如下:

2 实验配置及结果分析
采用PCAULF作为特征参数的说话人识别模型如图2所示。语音数据经过预处理和特征提取两个步骤,得到帧级特征矢量集。训练时,由PCA对所有语音的段级特征求取降维变换矩阵,之后通过训练得到模板参数;识别时,首先使用训练时得到的变换矩阵对待测语音的段级特征进行降维,之后再通过模板匹配得到识别结果。
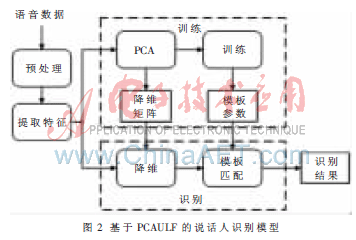
语音数据采用TIMIT语音数据库,随机选取50人,每人共10条语音,每条语音长4~6 s,其中8条用于训练,2条用于识别,保证了训练与识别语音的不一致。噪声库采用NoiseX-92专业噪声库中的三种常见噪声,分别为平稳高斯白噪声、粉噪声和Babble噪声。基线系统声学特征采用能量和12阶MFCC特征以及衍生的ΔMFCC,共26维,之后进行了倒谱提升和RASTA滤波;模型采用训练和识别较为快速的矢量量化(VQ),码本大小取32。语音采样频率为8 kHz,帧长为32 ms,帧移为12.5 ms。
本节主要开展了以下三个实验:
实验一:对纯净的语音进行训练,以段长分别为G=1,2,…,8,段移分别为Ginc=1,2,…,G求取段级特征,设累积贡献率门限为1,得到变换矩阵(该变换矩阵并没有实现降维);在识别阶段,先对G帧语音特征组成的超矢量进行变换,再测试其识别率。该实验主要用于分析合适的段长和段移。
实验二:在纯净语音基础上,以信噪比SNR(Signal Noise Ratio)为20 dB、10 dB、5 dB分别混叠了NoiseX-92专业噪声库中的平稳高斯白噪声(White)、粉噪声(Pink)和Babble噪声(Babble),取实验一分析得出的段长和段移,采用不同的PCA降维参数,对帧级特征和段级特征进行变换,测试识别率,并对各种噪声和SNR条件下的识别率求平均,得到不同PCA参数所对应的识别率。该实验主要用于分析降维参数对识别率的影响。
实验三:根据实验一、二得到的段长、段移和降维参数,采用实验二的加噪方法对纯净语音进行加噪,对段级特征、经过PCA降维处理的帧级特征以及基线系统的帧级特征的识别性能进行了测试。该实验主要用于对本文提出的算法的识别精度和速度进行测试。
2.1 段长与段移分析
实验一结果如表1所示。

由表1可见,当以帧级特征作为训练和识别的特征时,其识别率明显低于经PCA方法变换后的段级特征的识别率。总体来说,当G固定时,随着Ginc的增加,识别率逐渐降低;当Ginc固定时,随着G的增加,识别率也逐渐降低。当G≥8时,段级特征识别率不如帧级特征。当G=1,Ginc=1时,等效为直接用PCA方法对帧级特征进行变换。由于帧级特征(能量+MFCC+ΔMFCC)中计算一阶差分时引入了冗余,PCA方法正是为了去除各个主成分之间的冗余,故经PCA变换后的帧级特征(G=1,Ginc=1)拥有更好的识别性能。但当语音信号为带噪数据时,该特征识别性能不如段级特征(见2.3节)。
由于当G和Ginc均较大时,模板匹配次数减小,识别速度会得到明显提高,因此,为了兼顾识别速度和精度,结合表1的结果,本文选取G=6,Ginc=4。
2.2 PCA降维参数分析
实验二结果如图3(a)、(b)所示。其中,PCA参数主要指的是设定的累积贡献率门限,即选用累积贡献率不小于累积贡献率门限的多个特征矢量组成降维变换矩阵。

由图3(a)可见,对于帧级特征,当训练语音和待测语音较纯净时,累积贡献率门限值越大,识别率越高。图3(b)表明,对于段级特征,累积贡献率门限值位于94%附近时,识别效果较好。门限太大易造成噪声参与识别,影响识别精度;门限太小,易造成降维后的特征包含语音信息不充分,虽然能提高识别速度,但却降低了识别精度。因此,本文在进行PCA降维时,选用累积贡献率不小于94%的特征向量组成降维变换矩阵。
2.3 带噪环境下基于PCAULF的说话人识别系统性能分析
实验三结果如图4~图6所示。

由图4~6可以看出:(1)总体来说,在三种常见噪声环境下,段级特征与经PCA降维后的帧级特征识别率相近,均高于直接采用帧级特征时的识别率。(2)由于段级特征引入了长时特征,且PCA降维在一定程度上抑制了噪声对识别的影响,因此,在SNR较低时(SNR<20 dB时)具有更好的鲁棒性。
以上实验的PC配置为:Intel Core(TM)2 Duo CPU E7500 @2.93 GHz,1.96 GB内存。三种特征在所有语音的识别阶段的平均运算时延如表2所示。

可见,由于识别时,模板匹配的运算时延远大于对数据进行降维的运算时延,而段级特征的引入带来了模板匹配次数的减小,因此,段级特征在识别阶段的运算速度明显大于帧级特征,约为帧级特征的2.8倍,更加适用于实时说话人识别系统。
本文以现有的帧级语音特征为基础,结合语音的长时特性和改进PCA方法,提出了一种适用于说话人识别的段级语音特征,并分析了算法中的参数对识别性能的影响。实验结果表明,该算法在提高语音特征鲁棒性的同时,提高了识别速度,适用于实时说话人识别系统。
参考文献
[1] FURUI S. Digital speech processing, synthesis, and recognition[M]. New York: Marcel Dekker, 2001.
[2] GISH H, SCHMIDT M. Text independent speaker identification[J]. IEEE Signal Proc, 1994,11(4):18-32.
[3] REYNOLDS D A. The super SID project: Exploiting high level information for high accuracy speaker recognition[A]. In IEEE International Conference on Acoustics, Speech and Signal Processing[C]. Hong Kong, China, 2003:784-787.
[4] DRYGAJLO A,MALIKI M E. Speaker verification in noisy environments with combined spectral subtraction and missing feature theory[A]. In IEEE International Conference on Acoustics, Speech and Signal Processing[C]. Seattle, USA, 1998,1:121-124.
[5] HERMANSKY H, MORGAN N. Rasta processing of speech[J]. IEEE Trans on Speech and Audio Processing. 1994,2(4):578-589.
[6] WANG L ,KITAOKA N,NAKAGAWA S. Analysis of effect of compensation parameter estimation for CMN on speech/speaker recognition[A]. In 9th International Symposium on Signal Processing and Its Applications(ICASSP’07)[C]. Sharjah, 2007:1-4.
[7] TORRE A, SEGURA J C,BENITEZ C. Non-linear transformations of the feature space for robust speech recognition[A]. In IEEE Proc. Of ICASSP[C]. Orlando, USA, 2002:401-404.
[8] VIIKKI O, LAURILA K. Cepstral domain segmental feature vector normalization for noise robust speech recognition[J]. Speech Communication, 1998, 25(1):133-147.
[9] HSU C W, LEE L S. High order cestral moment normalization(HOCMN) for robust speech recognition[A]. In IEEE Proc of ICASSP[C]. Montreal, Canada, 2004:197-200.
[10] LIU B, DAI L R,LI J Y. Double gaussian based feature normalization for robust speech recognition[A]. In Proc of ISCSLP[C]. Hong Kong, 2004:253-256.
[11] DU J, Wang Renhua. Cepstral shape normalization(CSN) for robust speech recognition[A]. In Proc of ICASSP[C]. Las Vegas, USA, 2008: 4389-4392.
[12] 王波, 徐毅琼, 李弼程. 基于段级特征的对话环境下说话人分段算法[J]. 计算机工程与应用, 2007, 28(10):2401-2416.
[13] 任苏亚, 基于改进的PCA和ICA算法的掌纹识别研究[D]. 北京: 北京交通大学, 2007:35-39.
[14] NALIN P S, MAYUR D J, PRAKASH C,et al. Palm print recognition: two level structure matching[A]. In Proc. of IJCNN [C]. Vancouver, Canada, 2006: 664-669.