
序言
无线技术的持续演进发展、全球无线用户的激增,以及市场对更强大数据承载能力的需求,全面催生了各种新标准的不断涌现,如宽带码分多址 - 高速分组接入 (WCDMA-HSPA)、WCDMA-HSPA+ 以及长期演进技术 (LTE) 等。基于无线服务网络的数据使用呈指数级增长,从而进一步推动了异构网络的出现 —— 支持宏蜂窝title="基站" target="_blank">基站和小型蜂窝基站的分层网络部署方案。
随着 LTE 部署成为现实,运营商纷纷热衷于采用可持续降低网络成本、同时还能维持并提升服务质量的“片上系统”(SoC) 架构。要支持向 LTE 的成功过渡,需要在数字信号处理器 (DSP) 的设计方面实现一系列技术创新。德州仪器 (TI) 名为“KeyStone”的多内核 SoC 架构不仅功能强大而且极富创新性,能够有效支持 WCDMA 与 LTE,进而降低成本。KeyStone 多内核架构可实现具有专用 WCDMA与 LTE加速器的、名符其实的多标准(LET、WCDMA)解决方案。本白皮书全面阐述了 TI KeyStone 多内核架构如何在 LTE 基站上实现第二层网络和传输处理。
随着全球无线用户数量的激增,无线技术也在持续实现演进发展。移动数据使用量的新近增长、层出不穷的新应用以及互通互连的生活方式,都需要移动网络提供强大的支持。对无线宽带服务不断增长的需求促使 3GPP 定义可同时为运营商和终端用户带来诸多优势的 LTE 技术解决方案,,如不仅能提高容量、降低网络复杂性、降低开发与运营成本,而且最终还能显著提升用户体验。
名为演进型 UMTS 陆地无线电广播接入网络 (E-UTRAN) 的 LTE 无线电广播接入网络支持基于共享分组通道的移动宽带服务。这种方案不仅能够提高频谱效率和区段容量,同时还能缩短用户层的时延。以演进型分组内核 (EPC) 著称的LTE 核心网络,采用平坦型纯 IP 架构演进支持 E-UTRAN。借助平坦型 IP 架构,运营商不但能够减少资本支出的网络组件数,同时还能缩短系统时延以支持最新应用,并演进支持无线电广播接入与核心网络。
LTE 可支持灵活的通道带宽 (1.2-20 MHz) 以及频分双工 (FDD) 与时分双工 (TDD) ,以实现 LTE 系统的灵活部署。LTE 可为每一个 20 MHz 频谱提供 100Mbps 的下行和 50Mbps 的上行速率。通过采用多天线信号处理技术,LTE 能够提供甚至更高的数据传输速率——下行高达 326.4 Mbps。
根据 Dell'Oro Group 调查显示,全球移动用户数有望从 2009 年的 48 亿增至 2014 年的 72 亿。这些用户将进一步推动对更高数据速率的需求,从而导致数据流量的激增。集频谱效率高、通道带宽灵活性高与资本节约更显著(因其采用平坦型纯 IP 架构)等数大优势于一身的 LTE 将推进运营商部署 LTE 网络。
2009 年到 2010 年间,对 LTE 的大规模试用与部署在全球范围内广泛展开。有 25 家顶级运营商承诺部署 LTE 系统,LTE 将呈现迅猛增长态势。北美地区的主要运营商将在 2010年 - 2011 年期间开始 LTE E-UTRAN NodeB (eNodeB) 的部署,但是 LTE 的市场增长将在 2012 年迎来新的转折点,到时候欧洲和中国的运营商也将开始部署 LTE。根据 Dell'O Group 的预测,到 2014 年年底,这一增长将使全球范围内的 LTE 用户数量突破 1 亿大关。
2.
图 1 展示了包含名为 eNodeBs 基站的 E-UTRAN 架构。eNodeBs 可提供针对用户设备(UE,移动)的用户层与控制层协议终端 (Uu) ,以及针对核心网络的传输终端 (Iu)。
eNodeBs 不仅可通过 X2 接口相互连接,而且也可通过 S1 接口连接至核心网络 EPC,更确切地说还可通过 S1-MME 与移动管理实体 (MME) 连接,以及通过 S1-U 接口与服务网关 (S-GW) 连接。
LTE 协议架构
eNodeB 协议结构包含两个主要层:无线电广播网络层与传输网络层。在无线电广播网络层可以实现无线电广播接口功能,而在传输网络层则可实现标准的传输功能(例如以太网)。可在如下三个协议层中实施无线电广播接口:物理层(L1,PHY);数据链路层 (L2);以及网络层 (L3),以向 UE 提供用户层与控制层协议终端(Uu)。传输接口可提供针对核心网络的隧道协议终端 (Iu)。
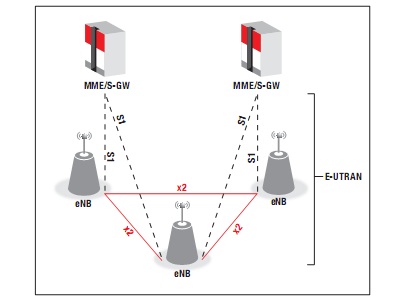
图. 1 – E-UTRAN 架构
3. L2 处理
L2 又被进一步细分为媒体接入控制 (MAC)、无线电广播链接控制 (RLC) 以及分组数据汇聚协议 (PDCP) 三个子层。图 2 与图 3 对 L2 子层的服务与功能进行了描述。
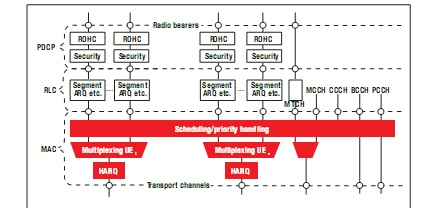
图 2 – L2 架构(下行)
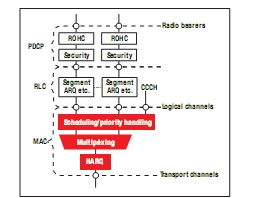
图 3 – L2 架构(上行)
MAC 子层负责将同一传输通道上的多个逻辑通道(无线电广播承载)多路复用至一个或多个逻辑通道,并将传输通道上 PHY (L1) 中的MAC 服务数据单元 (SDU) 解多路复用至一个或多个逻辑通道。此外 MAC 子层还负责动态调度活动,包括在某个 UE 的逻辑通道之间以及在 UE 之间进行优先处理。
4
MAC 子层的其他功能包括,通过混合自动中继请求 (HARQ) 进行纠错、传输格式选择以及填充等功能。L3 的无线电广播资源控制 (RRC) 子层可控制 MAC 子层的配置。
RLC 子层的功能包括协议数据单元 (PDU) 传输、通过 ARQ 纠错、RLC SDU 的级联/分段/重组、重复检测以及协议错误检测等。L3 的 RRC子层可控制 RLC 子层的配置。配置后的 RLC 实体能够以下列三种模式之一来执行数据传输:透明模式 (TM)、非确认模式 (UM) 以及确认模式 (AM)。
PDCP 子层的功能包括:通过性能稳定的报头压缩 (RoHC) 进行报头压缩/解压缩,用户层与控制层数据传输,用户层和控制层数据的加密与解密,控制层数据的完整性保护与完整性验证。
传输/回程处理
eNodeB 上的传输/回程协议栈可实现与核心网络的通信。eNodeB 可提供与EPC(MME 与 S-GW)接口相连的 S1 接口,以及与另一 eNodeB 接口相连的 X2 接口。图 4 和图 5 对 S1 用户层与 S1 控制层的协议栈进行了概括性描述。
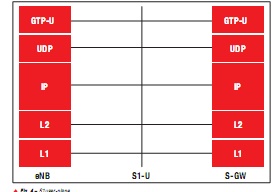
图 4 – S1 用户层
5
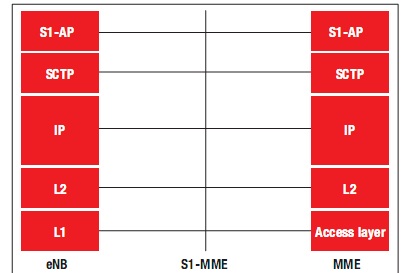
图 5 – 控制层
传输协议栈能够为回程(IPSec 隧道)的用户层数据提供安全终端 (GTP-U),同时为回程(SCTP) 的控制层数据提供 S1-AP/X2-AP 终端。
TI KeyStone架构
向 LTE 的升级给基站厂商及其供应商带来了全新的挑战,他们需要在基站中实现更高的吞吐量、更高的性能及更大灵活性。同样,LTE 也给基站厂商及供应商带来了观念上的转变,实现高频谱效率需要更为复杂的数据处理与调度。
数据层处理要求低时延和高吞吐量,同时调度还需具备动态与通道感知功能。支持 LTE 需要在基站的系统设计方面实现大量技术创新。运营商也纷纷对可持续降低其网络成本的 SoC 架构青睐有加。
TI 名为“KeyStone”的多内核 SoC 架构不仅功能强大而且极富创新性,从而使基站厂商能够从 LTE 等最新技术中显著受益。该架构具备的众多关键组件不仅可支持新的 LTE 功能,同时也可用于提升 WCDMA 等现有无线技术的性价比。图 6 对 KeyStone 架构进行了说明。
6
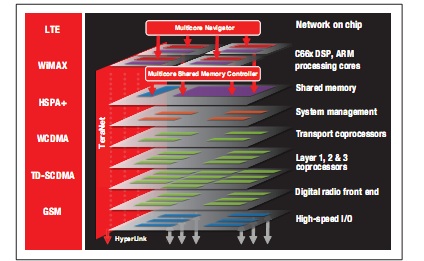
图 6 – KeyStone 多内核架构
TI KeyStone多内核架构拥有高度的灵活性,可同时集成定点与浮点运算、定向协处理与硬件加速,以及优化的内核间/组件间通信。此架构包括多个 C66x DSP 内核,能够支持高达 256 GMAC 的定点运算性能以及 128GFLOP 的浮点运算性能。另外,此架构还包括综合而全面的连接功能层:TeraNet2 能够与各种处理组件无缝互连;多内核共享内存控制器能直接接入片上共享存储器与外部第三代双倍数据速率 (DDR3) 存储器;多内核导航器可助于管理整个 SoC 架构的通信;以及 HyperLink 50 可与额外的协处理器或其他 TI SoC 等同伴器件实现互通互连。部分此类关键处理组件可在 TI SoC 上实现 LTE L2 与传输处理。
网络协处理器
网络协处理器是一款硬件加速器,能够减轻 DSP 内核处理往返于核心网络的以太网分组的工作量。网络协处理器包含 6 个微精简指令集计算 (?RISC) 内核,可加速自主的分组对分组处理。网络协处理器中的硬件模块 —— 分组加速器与安全加速器可在传输网络层以及深层无线电广播网络层实现快速通道处理。
网络协处理器在 LTE 传输/回程侧的功能特性包括:以太网/IP/包络安全有效负载 (ESP)/用户数据报协议 (UDP) 报头处理;循环冗余校验 (CRC) 验证与生成;IPSec 检测、认证、加密与解密;通用路由包络 (GRE) 隧道;基于 IPv4/6、传输控制协议 (TCP)/UDP、SCTP 端口或 GTP-U 隧道数据包的分类与路由;以及,基于 GTP-U 的服务质量。
7
在无线电广播端,网络协处理器可支持基于特定配置文件匹配(例如根据【RFC】4995 批注请求的未压缩大型数据包)与 3GPP 空中加密与解密的 RoHC。网络协处理器支持每秒 150 万个数据包(1Gbps 以太网线速)的处理速度,带相关安全上下文高速缓存的 64 条独立 IPSec 隧道,安全上下文在主存储器中的 8,192 条IPSec 隧道,以及 8,192 个 GTP-U 隧道 ID 查询条目。
多内核导航器
多内核导航器使用一套队列管理器子系统与数据包直接存储器存取 (DMA) 子系统来控制与实施设备内的高速数据包移动,从而能够显著降低设备 DSP 的传统内部通信负载,进而提高整体系统性能。多内核导航器采用零复制方案在所有层进行数据处理优化。多内核导航器还支持分类与排序、多内核访问存储、存储器管理、分段与重组以及跨多个内核或器件进行交付。
队列管理器子系统包含 8,192 个硬件队列,负责加速数据包队列的管理。在队列管理器模块的特定存储器映射位置中写入 32 位描述符地址,即可将数据包添加至数据包队列。可通过读取特定队列相同地址来解除队列。
数据包 DMA 子系统包含 6 个数据包DMA,能够在 Serial RapidIO ? (SRIO)、第二代空中接口 (AIF2) 以及数据包加速器等器件中为管理数据包缓冲器的基础局端提供其它子系统。数据包 DMA是一个其数据目的地由一个目的地与自由描述符队列索引(而非绝对存储器地址)来决定的DMA。
快速通道处理与零复制方案
本部分探讨了如何使用 TI KeyStone 架构的关键处理组件来加速 LTE L2 网络与传输处理。上面介绍过的关键处理组件与 LTE L2 网络及传输处理功能相关。这些组件实现的快速通道处理与零复制方案对于使用 LTE 实现低时延与高吞吐量性能非常重要。
传输层处理
图 7 说明了如何使用网络协处理器来加速 LTE 传输层的处理。

图 7 – 传输层处理的加速
8
在核心网络端,数据包既可以通过具有内置串行千兆介质独立接口 (SGMII) 的千兆以太网接口也可以通过 SRIO 接口进入网络协处理器。数据包报头首先经过检验和验证(例如以太网 MAC 地址),然后被传输至 IPSec 终端。经过 IPSec 终端后,网络协处理器可检验内部报头是否与 GTP-U/UDP/IP 相匹配。随即执行 32 位 GTP-U ID 值的查找,并使用关联的 QoS 与无线电广播承载队列 (RBQ) 对进入的数据包进行分类。
RoHC 硬件可寻找描述匹配。可将数据包路由至软件RoHC处理(例如支持 RTP/UDP/IP报头压缩的 VoIP 数据包),或在经过 RoHC 硬件模块(例如根据 RFC4995 规定的未压缩大型数据包)执行最基本的“全硬件”处理后直接对 3GPP 进行加密。如果需要进行软件 RoHC 处理,在报头压缩后,RoHC SW 模块将数据包返回至网络协处理器进行 3GPP 空中加密。加密后,数据包被路由至相关的无线广播承载硬件队列,并在其中根据用于相似 QoS 数据包的算法来进行调度。向 RLC/MAC 模块交付调度授权后,其根据需要从 RBQ 弹出的数据包可将这些授权传递至 RLC/MAC 协议栈,并根据所授权的长度创建 MAC PDU。
总之,网络协处理器可创建全加速的自主快速通道处理,在大多数情况下可完全终止 S1-U/X2 用户层处理并为软件运行交付已分类的 RLC SDU。
L2 数据层处理
多内核导航器可为 LTE L2 数据(用户)层处理提供数据包基础局端。数据包基础局端可减轻从DSP 分类的工作量,从而为零复制操作提供硬件,并为分段与重组提供硬件辅助。二者结合起来即可大幅加速 LTE L2 数据层的处理,以获得低时延、高吞吐量性能。
借助多内核导航器,系统中的所有数据包都能够满足数据包DMA 接口规范要求。数据包通常以图 8 中的主机类型数据包格式表示,其可实现灵活的存储器使用模式。在这种格式下,数据包通过链路缓冲器描述符 (BD) 来表述。我们将第一个 BD被称为数据包描述符 (PD)。BD 具有指向储存数据包有效负载的数据包缓冲器指针。队列管理器可与 PD 协同工作。
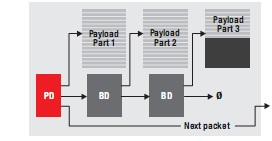
图 8 –主机类型的数据包格式
9
队列管理器可在其内部随机访问存储器 (RAM) 中维护数据包链路信息,从而为实现超高效率的数据包压入与弹出提供简单的软件应用编程接口 (API)。此外,其还可以确保队列所有访问的多核原子性,从而将多核软件从门控与保护逻辑中释放出来。为了实现基于演进数据包系统 (EPS) QoS 的无线电广播承载服务架构目标,相似服务等级的无线电广播承载都要以硬件队列集的形式出现。
零复制 RLC/MAC概念充分利用数据有效负载无需在 PHY 编码器/解码器的 PDCP 加密(解密)与 CRC 生成(或校验)之间进行处理的这一原理。RLC 与 MAC 子层需要对数据包进行汇聚/解汇聚、分段/解分段、多路复用/解多路复用,并需添加/移除控制信息与报头。想要在无需触及有效负载数据(零复制)的情况下实现这一点可节约多达 90-95% 的处理周期时间。因此,有效负载数据驻留在 DDR 中,而且 L2 DSP 核心软件是不可触及的。

图 9 – 下行数据流示例
10
例如,在下行方向,网络协处理器数据包 DMA 进程负责对数据包进行接收、分段与分配。RLC/MAC 软件可在数据包描述符上运行且无需访问数据包有效负载。其构建的 MAC PDU 可被 SRIO 数据包 DMA 发出并反向重组成相邻的存储器。
RLC/MAC 软件使用数据包 API 库在数据包内运行。该软件可在数据包链中移除/插入描述符,而且还能执行数据包合并/分离操作。在需要额外报头时才用得上新的描述符。图 9 以在网络协处理器中执行 PDCP (RoHC) 等所有快速通道处理为假定条件,对下行数据流进行了总结。
我们将所有指向预分配固定容量数据缓冲器的 BD 链接在一起,并将其放置在下行 (DL) 自由队列中。有多个自由队列,每一个队列都对应一个固定容量的缓冲器。当来自网络协处理器的数据包到达后,网络协处理器中的数据包 DMA 即从 DL 自由队列中拉取 BD,然后根据 GTP-U ID/RBQ ID 映射对其进行初始化和构建 PD,并将 PD 压入 RBQ。DL 调度程序制定分配决策,并向 RLC/MAC 进程发布分配授权。
RLC 与 MAC 根据需要弹出授权的 RBQ,然后将 PD 路由至 RLC 与MAC 队列。可能对数据包分段,之后统一进行多路复用并为其添加报头。数据包被保留在 RLC AM 重传队列中,同时对这些数据包克隆的复制版本(新的 PD 指向同一缓冲器)会向下流至可创建 MAC PDU 的协议栈。当传输就绪时,数据包(用于已分配 UE 的 MAC PDU)在硬件 DL PHY 队列中排队。SRIO 中的数据包 DMA 从 DL PHY 队列获取数据包,然后将它们传输至 LTE PHY 设备。传输开始后,数据包进入 HARQ 重传队列,并且在成功交付后返回到 DL 自由队列中。
调度层
对于调度层,制定无线电广播资源的分配时需将瞬时通道条件、流量条件以及 QoS 等要求纳入考虑范围。因为通道与流量条件因时间和频率的不同会有很大差异,因此能否实现高效的带宽利用率很大程度上取决于调度程序选择最佳可能用户(单个用户或用户对)的能力。
典型的调度算法可为单个或多个用户模式构建一组调度假定方案。调度程序然后根据链路的自适应性为每种假定计算中标率。最终,调度程序选出最佳假定方案并用以指导通道分配。
调度算法的复杂性是由单个调度假定的计算成本以及需检查的假定数目来决定的。信号处理密度型调度是一种高效率的动态的通道感知型调度。上行端的 FDD/TDD 调度程序需要计算足够大的一套假定方案才能维持单个或多个用户模式的调度增益;同时,带下行链路波束成形 (downlink beam foaming) 的 TDD 调度程序要求的假定方案可假定定向传输与特征值分解 (EVD) 计算。KeyStone 架构中的 C66x DSP 内核可支持专业的定点与浮点指令,可实现高效的 EVD 计算,如矩阵相乘、矩阵求逆以及大量用户(数以百计甚至数以千计)的高效搜索与筛选。图 10 提供了由 TI 仿真工具生成的调度程序可视化示例。此例使用 100 个无线电广播资源模块,每个传输时间间隔(TTI,1 毫秒)可生成 20 个分配授权。频谱的较低位部分可用于半持续性语音流量,而较高位部分则用于特定的数据流量。
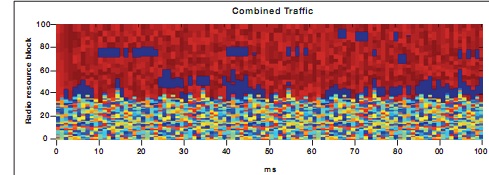
图 10 – 调度程序可视化示例
结论
TI KeyStone 多内核 SoC 架构可提供一个低时延、高吞吐量的低成本高效率平台,可支持适用于宏与小型蜂窝 eNodeB 系统的真正多标准 (LTE、WCDMA)解决方案。高吞吐量硬件加速器与数据包基础局端加速可实现灵活且可扩展的 LTE 部署,同时还能最大限度地缩短 LTE 系统所需的时延。在同一 DSP 中集成定点与浮点技术可实现优化的矩阵处理最,以满足 LTE要求的调度效率。
根据对宏 LTE 系统的解决方案分析,由于采用KeyStone 多内核架构实现快速通道与零复制处理,可以将 20 MHz、2x2 多重输入多重输出 (MIMO) 以及 105 Mbps 下行与 52Mbps 上行数据率- L2 数据-以及传输层系统开销降低10 到 15 倍。借助针对 LTE 调度程序运行而优化的 C66x DSP 定点与浮点指令,还可以使用更多高级调度算法,从而将频谱利用率提高 20%。