高速可配置RSA密码协处理器的ASIC设计
2009-05-06
作者:曹 威
摘 要: 提出了一种基于嵌入式系统的高速、可配置RSA密码协处理器的ASIC设计方案,可实现256 bit到2 048 bit的RSA加密运算。为了提高运算速度,采用改进的高基模乘算法和流水线结构;为了消除协处理器与内存之间的通信速度瓶颈,使用DMA直接访问方式;同时,数据输入输出都使用双口存储体,形成加解密数据流,本文将该加解密协处理器简称为SPU(Streaming Processing Unit)。
关键词: RSA;模乘算法;蒙哥马利乘法;专用集成电路;加解密协处理器
公钥密码系统,也称为非对称密码系统,是密码学的一种形式。它有一对密钥:公钥和私钥。它们在数学上有一定的关系,但是很难从公钥得到私钥。公钥密码学的两个主要分支:
公钥加密:任何人都可以将消息(明文)加密成密文,但只有接收者才能生成有意义的密文。这样确保了数据的安全性,用于可靠性方面。
数字签名:发送者通过私钥加密的消息(明文),可以被任何人通过公钥解密。因此证明了这条消息是发送者签名并且没被人修改过。这种方法用于数字签名与认证方面。
公钥制密码学中,目前应用最为广泛的是RSA公钥制密码算法[1]。RSA算法通过模幂运算实现,模幂运算是整个RSA算法的核心。在操作数较小的情况下,模幂运算比较简单,可以直接计算。但是为了保证必要的安全等级,一般采用512 bit或1 024 bit的密钥长度,在银行等需要更高安全等级的系统中,会采用更长位宽的密钥,模幂的难度随之成指数级增长。RSA算法安全性的保证和需要就像一把双刃剑,在给攻击者带来计算难度的同时也提高了运算的复杂度。
本文提出一种基于ASIC设计的高速、可配置的RSA密码协处理器体系结构,可实现256 bit到2 048 bit的RSA加密运算。该方案综合考虑RSA模幂和模乘算法的特点和瓶颈,采用改进的高基模乘算法和流水线结构,提高运算速度;采用DMA直接访问方式,消除协处理器与内存之间的通信速度瓶颈;数据输入输出都使用双口存储体,形成加解密数据流。
1 公钥密码算法RSA
1.1 RSA算法
RSA加密算法是目前在理论和实际应用中较为成功的公钥密码体制,它的安全性是基于数论中大整数分解为素数因子的困难性,这一困难在目前仍是一个NP问题。要建立一个RSA密码系统,首先任选两个大素数p、q,使:
N=p×q
并得到Euler函数:
Ψ(n)=(p-1)×(q-1)
然后任选一个与Ψ(n)互素的整数e作为密钥,再根据e求出解密密钥d,d满足:
d×e=1modΨ(n)
事实上,加密密钥e和解密密钥d是完全可互换的,因此在求e或d时,不论先假设哪一个,再由它去求另一个都是一样的。对某个明文分组M和密文分组C,加密和解密的过程如下:
加密过程:
C=MemodN
而解密过程是:
M=CdmodN
RSA加解密就是做模幂运算的过程,而模幂运算是通过一系列的模乘运算得到的。模幂算法根据幂指数扫描顺序不同可以分为两种:从左往右的L-R算法和从右往左的R-L算法。
算法一:R-L模幂算法
式中n为指数e的位数,P为中间变量
输入:M,e,N;
输出:C=Me modN;
(1)P=M;C=1;
(2)for i=0 to n-2;
(3)if e[i]=1 then C=C×P mod N;
(4)P=P×P mod N;
(5)next i;
(6)if e[n-1]=1 then C=C×P mod N;
(7)return C;
算法二:L-R模幂算法
输入:M,e,N;
输出:C=Me modN;
(1)if e[n-1]=1 then C=M,else C=1;
(2)for i=n-2 to 1;
(3)C=C×C mod N;
(4)if e[i]=1 then C=C×M mod N;
(5)next i;
(6)return C;
从以上两种算法可以看出,一次模幂运算需要进行N次平方模运算和平均N/2次乘法模运算;但在从右往左的扫描中,乘法和平方是相互独立的,可以并行。因此可以增加一个N位的乘法器,一个做乘法,一个做平方,这可以显著提高一次模幂运算的速度。本文面向高速应用场合,因此采用R-L模幂算法。
在RSA算法中,不论是加密过程还是解密过程,都有一个共同的模乘运算(ABmod N),这个看似简单的运算,需要做一次乘法和一次除法,最后取余数。但由于M,e,C,d,N等参数的长度通常是1 024个二进制位或更高,使得模幂运算量巨大,很难在一般的协处理器上或处理器上运行,直到1985年由Montgomery提出了一种免除法的模乘算法[2],才使RSA算法在硬件和软件中得以实现。
1.2 Montgomery模乘算法
Montgomery算法的基本思想是把一个大整数转换为一个模R(R通常取2r)的余数表示形式,用转换后的余数进行一系列模乘运算,最后再转换为正常的表达形式。将计算A*B mod N时的mod N的除法运算转化为简单的移位运算,能够有效地提高模乘运算的速度。
算法三:Montgomery算法
设N为模数,R是2的整数幂,且R>N,并令R-1和N′满足0
输入:A,B,R,N;
输出:c=M(A,B)=A*B*R-1 modN
(1)T=A*B;
(2)m=(Tmod R)*N′ mod R;
(3)c=(T+mN)/R;
(4)if c>=N return c-N;
(5)else return m;
该算法不能直接实现RSA算法,需要进行相应的预处理才能消除R-1带来的影响(见算法五)。该算法仍然包含大整数的乘法,因此需要对其进行改进,使用高基模乘算法(见算法四),细化为小整数的乘法,以便于硬件实现。另外,该算法最后需要判断m是否大于N,如果大于N,必须再做减法,这在硬件设计上会增加额外的芯片面积。本文通过在模乘循环过程中增加一次循环,就可以免去最后的减法(见算法五)。
1.3 高基Montgomery算法
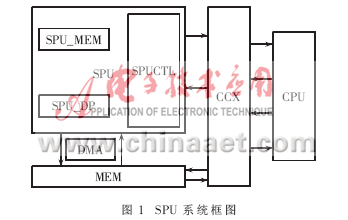
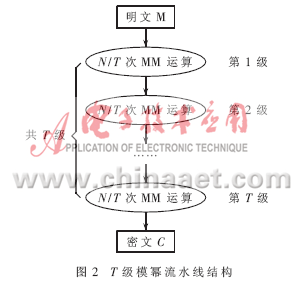
把n位大整数A,B,N分别表示成s位r进制整数,即A=(as-1 as-2…a0),B=(bs-1bs-2…b0)r,N=(ns-1ns-2…n0)r,且R=rs,s=n/r,则有N 算法四:高基Montgomery算法 Function M(A,B) S:=0;m=0; (1)计算中间结果m[i]: for i=0 to s-1 {for j=0 to i {s:=s+a[j]*b[i-j]+m[j]*n[i-j];} m[i]:=s*n′[i] mod r; s:=s+m[i]n[i] s:=s/r;} (2)计算最终结果并存于m[i]中: for i=s to 2s-1 {for j=i-s+1 to s-1 {s=s+a[j]b[I-j]+m[j]n[I-j]} m[i-s]:=s mod r s:=s/r} 算法五:从右往左扫描的免减高基模乘算法 (1)预处理: R2=R*R mod N;(事先计算出来,可消除R-1带来的影响) P=M(M,R2); C=1; (2)中处理: for i=0 to n-2 if e[i]=1 then C=M(C,P); P=M(P,P); next i; if e[n-1]=1 then C=M(C,P); return C;(计算C=M(Me)) (3)后处理: C=M(C,1);(免去了montgomery算法每次的减法运算)。 2 协处理器体系结构 2.1 SPU整体结构与模块划分 SPU与CPU通过CROSSBAR[3]交叉通信开关进行通信,而SPU与MEM之间则采取DMA方式直接通信,这样可以消除数据存取的速度瓶颈。同时,当SPU进行加解密工作时,CPU可以并行执行其他指令(只要不发生数据相关)。 SPU划分为控制模块,数据通道和存储单元。其中控制单元主要用于密钥移位控制,控制密钥的降幂,并根据密钥产生乘或平方控制信号。另外,控制单元还包括一个状态控制器,用于对前处理、中处理和后处理各个运算环节的控制。 数据通道部分则由Montgomery模乘单元和平方单元构成,两个单元并行,根据控制单元产生的控制信号来进行相应的操作,产生部分积和中间结果。 存储单元大小为8 Kbit,分为两部分。一部分是4 KB的RAM,用于加解密过程中暂存数据,以便形成流水线;另一部分是4 KB的ROM,用于存放公钥和密钥,掉电可以保存数据。 系统框图如图1所示。 2.2 流水线设计 为了实现高速、可配置的RSA密码协处理器,采用了按字读入的高基模乘算法,同时对模幂单元采用流水线结构:这样一方面可以增加数据吞吐率,加快数据运算速度;另一方面可以通过增减流水线的级数来增强可配置性。 从按字读入的高基模乘算法(算法五)中可以看出,每次密钥长度为N bit的RSA加解密过程是一次幂指数为N的模幂运算,而一次这样的模幂运算则是N次模乘运算。因此通过设计模幂流水线结构,可以大大增加RSA加解密的速度。 流水线结构的模幂运算如图2所示。明文M经过T级流水线数据通路,最后输出密文C;对于一个N位的RSA加密系统来说,如果采用T级流水线,则每一级流水线需要循环做N/T次MM运算。RSA的运算速度取决于一级流水线的速度。 2.3 DMA通道的工作过程 SPU向DMA控制器发出DMA请求,DMA控制器在接到SPU发出的DMA请求后,向CPU发出总线请求,请求CPU脱离对总线的控制,而由DMA控制器接管对系统总线的控制;CPU在执行完当前指令的当前总线周期后,向DMA控制器发出总线响应信号,CPU脱离对系统总线的控制,处于等待状态(但一直监视DMAC);DMA控制器接管对系统总线的控制;DMA控制器向SPU发出DMA应答信号,DMA控制器把存储器与SPU之间进行数据传送所需要的有关地址送到总线,通过控制总线向存储器和SPU发出读或写信号,从而完成一个字节的传送;当设定的字节数据传送完毕后(DMA控制器自动计数),DMA控制器将总线请求信号变成无效,同时脱离对总线的控制;CPU检测到总线请求信号变成无效后(CPU一直监视着),也将总线响应信号变成无效,CPU恢复对系统总线的控制,继续执行被DMA控制器中断的当前指令的当前总线周期。 2.4 存储体结构设计 SPU内部共设计两部分RAM,都使用双口存储体,主要用作数据输入、输出缓存。双口RAM分A和B两部分,每部分的深度32,宽度64,即32×64的存储空间;一块RAM可以存储2 KB的数据,输入输出各需要一块作为缓存,也就是说片内共设计4 KB的RAM。双口RAM的两部分是对称的,但是对每部分的读写都是独立的,当需要加密或解密时,数据先输入到A部分,当A部分输入满2 KB数据时,数据继续输入到B中,此时运算模块读取A中的数据计算,当B部分数据输入满时,运算模块已经计算完A中的数据,然后读取B中的数据,输出则是相反的过程,如此形成加解密数据流,运算流程如图3所示。 本文基于改进的按字输入的从右往左扫描的高基Montgomery模乘算法,提出了一种高速、可配置的RSA加解密协处理器的ASIC设计方案。该方案很好地解决了模幂和模乘运算的瓶颈问题,提高了算法并行性和运算效率。基于该方案可以方便地设计出各种速度和密钥长度的RSA密码协处理器,尤其对高速RSA市场具有很广阔的应用前景。 参考文献 [1] RIVEST R L,SHAMIR A,ADELMAN L M.A method for obtaining digital signatures and public key cryptosystems. Communications of the ACM,1978,21(2):120-160. [2] MONTGOMERY P L.Modular multiplication without trial division[J].Mathematics of Comptutation,1985,44(170):519-521. [3] OpenSPARC T1 Microarchitecture Specification.http://www.sun.com/hwdocs/feedback. [4] Kong Fan Yu,Yu Jia,Li Da Xing.An improved fast montgomery multiplication algorithm.Computer Engineering,2005,31(8):1-4. [5] Fan Yi Bo,Zeng Xiao Yang,Yu Yu.VLSI design of a High-speed RSA Crypto-Coprocessor with reconfigurable architecture.Journal of Computer Research and Development.2006,43(6):1076-1082. [6] Wang Long,Zhao Hui,Bai Guo Qiang.A cost-efficient implementation of pubilc-key cryptography on embedded systems.IEEE,I-4244-1098-3/07,2007:194-197. [7] BLUM T,PAAR C.Brief contributions:high-radix Montgomery modular exponentiation on reconfigurable hardware.IEEE Transactions on Computers,2001,50(7):759-764. [8] PIEPRZYK J,HARDJONO T,SEBERRY J.Fundamentals of computer security.Spring-Verlag,2003. [9] 吴行军,白立晨,孙怡乐,等.一种适用于多种公钥密码算法的模运算处理器.微电子学,2005,35(5):549-552. [10] 朱海峰.RSA关键运算的分析优化与硬件实现研究.南通大学学报,2006,5(4):97-100.