
一种噪声环境下语音命令识别控制器的设计和实现
2009-06-04
作者:张歆奕 张有为
摘 要: 提出了一种新颖的噪声环境下语音命令识别控制器,它是利用非空气传导语音传感器来获得语音信号,然后进行语音识别的系统。这种语音识别系统有很好的抗噪声抗干扰性能和很高的识别率。给出了该系统的硬件和软件的具体实现。
关键词: 非空气传导语音识别 语音信号处理
目前现有的技术中,利用语音识别技术实现人的自然语言与机器对话,即人机对话,使机器能听懂人的语音指令并且去执行人所发出的指令,已有相当的进展。语音识别的重要指标是人的语音的正确识别率。由于在相当多的使用环境中除了人发出的语音之外,还有环境噪声,这种噪声混杂于指令发出人的语音之中,使正确识别率大大降低,甚至出现错误识别。特别是象在车间、工地和公共场所等存在强噪声的环境,一般的语音识别系统更难正常工作。这就限制了利用语音识别技术正确产生控制指令,实现人机对话,在许多实际场所的应用。
本文给出一种在噪声环境(包括强噪声环境)下实现语音命令的识别并可对外部进行控制的语音命令识别控制器(后简称语音控制器)的设计和实现。本语音控制器的特点是:采用非空气传导的喉头送话器作为语音传感器;采用美国AD公司的数字信号处理(DSP)芯片ADSP2181作为语音识别算法和压缩算法实现的硬件平台;采用动态时间弯折(DTW)算法作为语音识别算法,采用自适应差分脉冲编码调制ADPCM算法作为语音压缩算法;通用性强, 留有通用的命令输出控制接口。
1 喉头送话器及其特性
喉头送话器不同于一般的利用空气传导的声音传感器(如麦克风),它必须紧贴发命令者的喉部,说话时声带发生振动,喉头送话器中的碳膜发生形变,使其电阻值发生变化,从而使其两端的电压发生变化,于是振动信号转化为电信号,即语音信号。空气中传导的声波无法使喉头送话器中的碳膜发生形变,所以喉头送话器感受不到空气传导的声音,具有很强的抗干扰能力,可在强噪声环境下获取命令发出者的语音信号。但是,喉头送话器获得的语音信号与空气传导的传感器获得的语音信号相比,丧失了较多的频率分量,特别是高频分量。经过大量试验,我们发现喉音器的带宽大致在2.5kHz左右,高于此频率的信号成分很少[1];因此采用喉头送话器作为语音传感器,可以提高系统的抗噪声的能力,但却给语音的正确识别增加了困难。本语音控制器针对这个特点,在硬件和软件上采取了相关措施,保证了系统仍有高的识别率。
2 语音控制器的硬件设计和实现
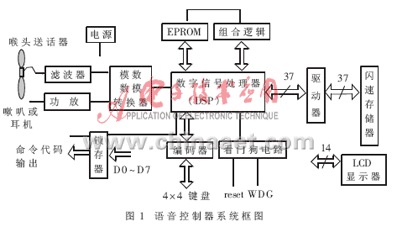
语音控制器的系统框图如图1所示。由图1可见,语音控制器由以下部分组成:数字信号处理器(DSP)、EPROM、闪速存储器、模数数模转换器、看门狗电路、组合逻辑、编码器、LCD显示器(用16X2点阵显示模块)滤波器、驱动电路(采用74HC245和74F245)。
2.1 信号处理核心电路
本控制器中信号处理核心电路由数字信号处理器、EPROM和闪速存储器构成。其中DSP芯片采用美国Analog Devices Inc.的ADSP2181,其外部时钟16.67MHz,内部工作时钟为33MHz,一个指令周期为30ns,内部含16K 字数据存储器和16K 字程序存储器,其主要特点是运算速度快、片内内存空间大、与内部外部的存储器的数据交换速度快和输入输出资源丰富,因此用于算法的实现和接口的控制;闪速存储器采用ATMEL公司的AT29C020,用于存储压缩了的语音和语音命令特征参数;EPROM采用LATTICE公司的27C020,用于存储程序代码和初始化数据。
在本设计中ADSP2181资源的使用情况如下:16K字的程序存储器全部定义为内存,使MMAP引脚接地,PMOVLAY=0;16K字的数据存储器全部定义为内存,设置DMOVLAY=0;2048个I/O地址中,只用3个地址(0x400,0x401和0x402)用于LCD控制,再用一个地址作为命令代码输出缓存器的地址;4M位的Byte Memory中,2M(00000~3FFFF)作为程序代码空间,2M(40000~7FFFF)作为数据存储空间,用D23~D16,A13~A0实现4M位的寻址;程序的加载采用BDMA方式,置BMODE=0;8个通用可编程输入输出中,用4个(PF4~PF7)用于输入键盘编码,一个(PF3)用于指示灯控制,另外FL0用于AD/DA转换器的软复位;串行口0与AD/DA连接,接收语音数据,并进行A律压扩;串口1只用于输出AD/DA所需的工作时钟。
EPROM的大小为2M位,安排在BDMA的00000~3FFFF,用于存储程序代码,每次复位时被加载到ADSP2181内的PM;闪速存储器的大小为2M位,安排在BDMA的40000~7FFFF,共2048块,每块128字节,用于存储语音样本和语音数据;由于闪存的删除必须整块操作,所以我们定义语音样本和数据的存储基本单元为128字节,同时把串行口0的自动缓冲区的大小也定义为128字节,以便于数据往闪存的读写。
2.2 语音的输入输出电路
语音输入通路由喉头送话器、滤波器和模数数模转换器中的A/D转换器组成。滤波器由运算放大器和RC低通滤波器构成,其中RC滤波器的3dB带宽由1/(2πRC)决定。若采用频率为8kHz,则滤波器的带宽应为4kHz,一来防止频率混叠,二来限制了高频噪声。运算放大器的增益定为1,主要起阻抗匹配作用。语音输入通路元件的参数要仔细调好,防止语音基线不稳和信号截顶[2]。语音输出通路由D/A转换器、小功率放大器和喇叭组成,其中小功率放大器采用MC34119。
2.3 命令代码输出电路及时序
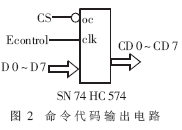
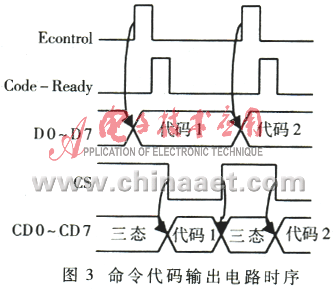
命令代码输出电路主要由锁存器SN74HC574构成,系统通过它输出命令代码,供外部电路译码控制用。语音命令正确识别后,系统通过Econtrol信号把语音命令对应的代码写入锁存器,同时发出Code-Ready信号,通知外部电路来取代码。代码由信号CS控制,只要CS为低,代码即可输出到CD0~CD7,如图2所示。它们的时序如图3所示。
2.4 组合逻辑、看门狗电路及键盘编码电路
组合逻辑用GAL16V8实现,通过对数据和地址及其他ADSP2181的输出信号译码产生控制信号;看门狗电路:采用MAX705,除为ADSP2181产生上电复位信号外,还可监视2181的运行,当出现故障时,WDG信号为低,可用于产生复位信号;编码器用MC14419实现16-4编码器,对16个键进行编码(4位码)。
3 语音控制器的软件设计和实现
3.1功能设计和软件结构
语音控制器的主要功能为:语音命令的识别及其相应代码的输出、系统词的录入、语音命令的训练、确认词(正确/不对)的训练、格式化闪速存储器、删除、查询及有关数据显示等。语音控制器接有4×4键盘,用于用户输入命令,完成上述功能。
语音控制器软件的主要功能模块如图4所示。
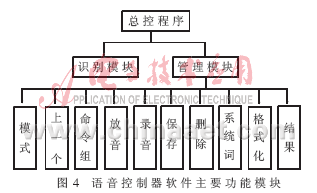
软件采用层次化结构,而且考虑到软件的高效性和灵活性,采用两种语言来编写,即算法和接口部分用ASP2181的汇编语言编写,而主控程序和管理模块等用C语言编写,这样兼有汇编语言的高效性和C语言的灵活性,加快了开发周期。下面是部分主控程序main.c:
/*==========Main routine========*/
void main()
{ char ch; init2181(); lcd_init();
...
manage_mode: /*Manage Mode*/
mode='M';
lcd_refresh();
ch=getkey();
switch(ch)
{ case KEY_NEXT:
phone_next_item();
N=voice_read(user,index); /*load voice */
break;
case KEY_RECORD:
if (phone_buf[index]==1)
{ lcd_clr(); lcd_puts(″Not empty!″); delay(300);
/*prompt(PROMPT_FULL);*/
break;
}
prompt(PROMPT_SAY_NAME);
lcd_clr(); lcd_puts(″Say command...″);
getword();
speakout(user_voice,N);
break;
……
上面的主控程序首先对调用了ADSP2181的初试化程序init2181()和液晶显示器初试化程序lcd_init()。程序显示了管理模块中“下一个”和“录音”两个子模块,其中录音模块调用了字符显示汇编程序lcd_puts()。下面是底层汇编程序hardware.dsp的部分程序:
#include
#include
.MODULE/RAM HardWare;
.CONST PORT_LCD_CMD = 0x400;
{ command port for write}
.CONST PORT_LCD_STATUS = 0x402;
{ status port }
entry lcd_puts_;
。。。
lcd_puts_:
function_entry;
save_reg;
dm(temp)=ar;
CALL WAIT_DIS;
{wait for LCD being idle}
ax0=dm(temp);
CALL WLcdDataWrite; {display it }
ax0=dm(cursor);
ay0=1;
ar=ax0+ay0;
ax0=ar;
ay0=0x88;
ar=ax0-ay0;
if ne jump disp_ok;
AX0=0XC0; { 0xC0 == 0x80+0x40}
。。。
上面程序中有字符显示子程序lcd_puts在头文件中声明后,即可由C程序调用。子程序中的CONST语句定义了液晶显示器的硬件口地址。
3.2 采用的算法
在孤立词语音识别中,最为有效的方法是DTW算法。该算法基于动态规划(DP)的思想,解决了发音长短不一的匹配问题。用于孤立词识别,DTW算法与HMM算法在相同的前提下,DTW的识别效果一般都高于HMM,而且HMM算法要复杂的多,还要有冗长的训练过程,在定点DSP上尤其难以实现。所以在孤立词语音识别中,DTW算法仍得到广泛的应用,语音控制器采用DTW算法。
语音的特征参数目前比较好的有Mel尺度频率倒谱参数MFCC参数和线性预测倒谱(LPCC)参数。经过试验[1]我们采用12阶LPCC参数外加帧能量和帧过零率构成14维语音特征矢量。
语音压缩和解压缩采用自适应差分脉冲编码调制ADPCM算法。对语音进行压缩是为了实现语音的回放。
3.3 识别门限及采样频率
识别过程中门限的确定无法在理论上进行精确的预测,只能通过试验确定。根据我们的算法和大量测试经验,确定了两种识别方式下的门限。在无需确认的方案下,系统只有一个门限:正确或错误门限。为了降低误识率同时尽可能地保持高的识别率,这个门限不能过低也不能过高。过于严格,识别正确的结果也不能通过确认,相反过于宽松的门限可能会使错误的识别结果被确认,造成较大的损失。可经过试验确定此门限。小于此门限识别结果被认为是有效的。在需要确认的方案下,系统设有3个门限:无需确认直接通过的确认门限,需要提问确认的门限,以及拒绝门限。由于有确认,错误的识别结果可以被拒绝,因此这种方案比较可靠,确认门限也可以适当严格些。可经过试验确定该三个门限。
试验中曾经试验过采样频率为8kHz、16kHz两种情况的比较,发现在定点DSP系统中采样频率的提高对识别率没有明显的提高,反而有所下降。而在微机上的试验表明,16kHz的采样频率只对识别率略有提高,但是并不明显。我们经过分析认为,这仍然是受到系统字长影响的结果。信号的实际有效带宽很低,采样率过高使得每个采样帧内的信号周期性不明显,从而降低了相关系数的计算精度,并最终增大了LPCC参数的计算误差。而在微机上的由于采用浮点算法,因此计算精度不受影响。经过试验,我们确定采用6kHz作为系统的采样频率,每80个采样(13.3ms)计算一帧,每帧仍取240点,交迭160点。得到了比较好的识别效果。
总之,语音控制器调试完毕后,对50个命令进行了测试,结果如下:训练完后当天进行识别,一次正确识别率几乎达到100%;训练完一周后进行识别,一次正确识别率大于97%。因此本语音识别控制器可在噪声环境下进行正确识别,具有实用价值。
参考文献
1 张歆奕,何强等,非空气传导语音的分析及识别,信号处理,1999;(10)
2 张歆奕,卢敦陆等.AD73311的特性及其在语音处理中的应用.电子技术应用,1999;24(8)
3 Tohkura Y,A Weighted Cepstral Distance Measure for Speech Recognition,IEEE Transactions on ASSP,1987;
(35(10): October 1987, pp.1415-1422。
4 Analog Devices Inc.,ADSP-2181 Data Sheet,1996
5 Analog Inc, Digital Signal Processing applications, Prentice Hall, 1990