
XML数据流基于组着色的XPath查询模型
2009-07-28
作者:刘景超,刘先锋
摘 要: 提出了一种新的XML数据流XPath查询模型GBRender,该模型通过组着色序列来直接处理元素,具有较高的处理效率与较强的适应性。
关键词: XML数据流;组着色;XPath查询
由于XML已经成为Web上数据交换的标准,用于各种应用和信息源之间的数据交换,而许多应用的特征是数据以快速、实时的数据流形式持续到达,适宜用数据流建模。因此,处理XML流数据的理论和技术目前成为流数据研究领域中的一个热点。XML流数据处理系统通常运行在Web上,用户查询通常用XPath[1]语言表示。由于一个用户可以提交若干查询,使查询的数量十分巨大。XML流数据处理研究的一个关键问题是如何同时有效处理大量来自用户的查询并及时将结果返回给用户。
根据数据流环境的特点,对XML数据流和处理通常有以下要求:每一个XML元素节点最多只能访问1次;使用有限和最少的内存空间存储临时数据,处理算法具有尽可能小的空间复杂度;对每个节点的处理必须有很高的效率,以满足实时处理的需要。
目前针对XML流处理系统所采用的主要方法是基于自动机的方法。其他方法有:基于索引的方法[2]、基于Bloom-Filter[3]的方法、Fist[4]方法等[5]。基于自动机的方法是将1个或1组XPath表达式表示为某种形式的自动机,通过状态转换来达到查询所需信息的目的。基于索引的方法是在数据传送之前加入索引信息或接收端引入某种索引机制来提高查询效率。以上方法处理XPath的方式都是通过对XPath本身形成处理器,即处理的过程主要集中在XPath本身,而且基于索引或通过DTD的优化或多或少都依赖于对XML结构信息的了解。而由XML数据流的应用环境决定了很多应用是在结构未知的情形下的数据序列查询。基于现有的研究及上述问题,本文提出了一种新的XML数据流XPath查询模型,以适合在结构未知的情况下的XPath查询,同时有效地减少流查询过程中对XPath的依赖程度。
1 背景及相关问题
由于流数据处理的广泛应用以及XML已经成为Web上数据交换的标准,流数据处理的研究已引起广泛的兴趣。
很多研究都采用自动机方法处理XML数据流。自动机技术用于XML文件查询的主要思想是:将1个或1组XPath表达式表示为某种形式的自动机,在要查询的XML文件上运行自动机,自动机根据当前状态及读入文档的节点判断下一步的行动,运行结束根据自动机是否处于接收状态来判断文件是否符合给定的XPath的查询条件。自动机查询模型如图1所示。

XFilter首次利用基于有限状态自动机FSM(Finite State Machine)的方法来过滤XML文档,它对每一个路径查询使用一个单独的FSM,并在文档处理的过程中,同时运行所有的FSM。YFilter在XFilter的基础上进行了改进,它将所有的XPath查询合并成一个单独的非确定有限自动机NFA(Non-deterministic Finite Automaton)[6],并共享所有查询的公共前缀,YFilter主要考虑了谓词中的AND谓词查询,采用后置处理的方式,这种方式产生大量中间结果影响系统性能。
XEBT(XPath Evaluation Based on Tree automata)[7]利用树自动机技术作为查询处理器,它基于表达能力丰富的树自动机,无须附加中间状态或保存中间结果,就能处理支持{[]}操作符的XPath,所以能较高效地处理XPath查询。在优化策略上,主要包括基于DTD的XPath查询自动机的构造、在空间代价有限增加的情况下采用局部确定化减少并发执行的状态、采用自上而下和自下而上相结合的查询处理策略等。
其他处理XML流的方法主要有基于索引(Index-Filter)的方法[2]、基于Bloom Filter[3]的方法以及FiST[5]方法。Index-Filter[2]采用基于索引的技术处理XML流数据,利用XML文档流的文档标记动态地建立XML文档的索引,从而避免处理一部分文档。在Index-Filter的方法中,建立索引要花费一定的时间,而且不能单遍处理XML文档。基于Bloom Filter的XML包过滤器具一种近似查询方法,利用Bloom Filter方法,将XPath表达式作为字符串,将XPath与XML包之间的匹配转换为字符串之间的匹配,从而提高查询性能,但它只是用来处理简单的XPath表达式且有一定的失误率。FiST方法针对Twig Pattern提出的一种有别于YFilter的方法,将一组Twig Pattern转换为prufer序列,并对一组Twig Pattern与XML流数据进行整体性匹配。
2 GBRender模型
2.1 GBRender相关定义
当XML以流的形式进行处理时,在逻辑上实际是以先序遍历的形式对XML树中的结点进行访问,通常采用基于事件的SAX模型来进行解析。这样,在对XML结构未知的情况下,可以根据接收的元素信息来分析其结构,并根据得到的结构信息为后续服务。
为了用来更好地描述GBRender查询模型,下面介绍几个定义:
定义1(组):XML的任何一个元素都有一个从根开始的标签路径,但很多元素都会有相同标签路径,即1个标签路径可以表示1组对应的元素。这里把XML文档中每一个不同的标签路径称为组。如图2所示,root/person/name即为一个组。
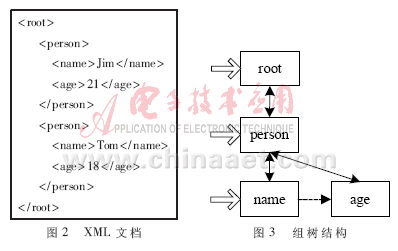
定义2(组树):组树是在处理XML数据流过程中,记录组、组之间关系的树形结构。其组织结构如图3所示。组树中,各组有指向其子组的链接,每个组有指向父组的链接,同时,同一层的组串接起来以便于处理时的需要。
定义3(终结元素):XPath表达式对应的最后一个路径元素,称为终结元素,它表示XPath请求所需的结果。如//A/B//C,C即终结元素。
定义4(着色):寻找每一个组的标签路径处于XPath表达式中的哪个位置,即当前XML元素的路径与XPath路径的关系并标记该组,这个过程称为着色过程。例如,组root/person/name对应XPath表达式//name的终结元素name,则可以标记该组为该XPath的终结组。
2.2 GBRender结构模型
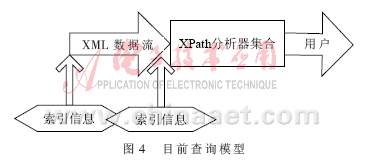
目前的XML数据流XPath查询处理,基本结构模型如图4所示,以XML数据流作为XPath分析器的输入,分析器可能有多个,也可能合并为1个。对XPath查询包含的索引信息有2种:一是传输之前的索引信息;二是接收端进行处理形成的索引信息。
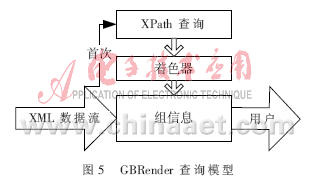
GBRender查询模型如图5所示,采用基于着色的方式来处理查询,当某个组首次出现时,通过着色器对其与XPath的关系进行着色。着色之后,再次遇到该组时不再依赖于XPath而只依赖其记录的组着色信息,尤其在单枝查询的情况下,可以直接对查询进行回应。在GBRender模型中,组着色的过程,实际上相当于XPath确定化的过程。例如,对于图2的文档进行//name查询,当首次出现name时,其组标签路径为root/person/name,即是对//祖孙关系在此文档上进行的确认化,而且当name出现在另一组时,会再一次进行确认化且不会相互影响。而常采用的DTD优化策略通常也是完成确认化的工作,当遇到2个不同组均存在name标签时,//就需要特殊处理了。
为了同时响应多个XPath查询,本文引入了着色序列的定义。
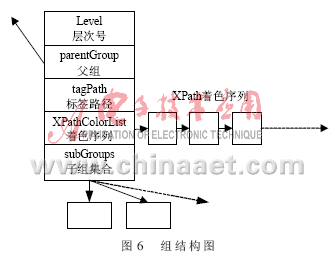
定义5(着色序列):根据XPath请求序列,对同一组生成对应的着色信息序列,此序列即称为着色序列。因为不同的XPath有不同的着色信息,因此也称XPath着色序列。
每组均有着色序列,其组树中组的结构如图6所示。
2.3 GBRender处理模型
基于组树的动态建立与组着色机制,GBRender的任意组,仅当首次出现时进行XPath着色处理,之后则根据着色情况进行处理。
GBRender的查询处理,其数据输入是XML的SAX解析事件流,包括startDocument、endDocument、startElement、endElement和Text事件,这里只给出GBRender处理模型在每一类事件的响应动作,而不讨论数据缓存处理。
startDocument: initiate the GroupTree GT and context //初始化组树GT
StartElement(element) // element为新接收元素
If(not existsGroup(element))InsertGroupAndDrawXpathColor(element);
//如果不存在该组,则生成该组并进行着色产生着色序列
setCurrentElement(element); //置element为当前元素
Text (value) // 当前元素的值
Add value into currentElement.currentValue;
// 增加到当前元素值
EndElement(element)
ProcessXPathColor(element); // 根据当前元素的着色序列信息进行处理
setCurrentElement(element.parentGroup); //
EndDocument
cleanUp( ); // 处理全部结束,清理
2.4 GBRender查询模型的主要特征
GBRender查询模型处理的操作方向与目前主要的查询处理不同,分析器并不是与XPath绑定,而是绑定到XML文档结构上,它对XPath只在组首次出现时进行着色的处理,之后则根据着色情况来进行处理。这种模型具有较强的灵活性,主要特点如下:
(1)对XML文档结构无需任何考虑。因为以接收的流数据为依据来动态建立组树。根据XML流数据的顺序性与元素之间关系的局部性,组树的访问总是发生在相邻元素之间,因此效率很高。
(2)无需依赖XPath分析器。一旦着色,相当于就对该组进行了确定化。同时,对于简单的XPath表达式在当前组即可直接判定作出处理。
(3)可以方便地利用现有的其他XPath查询处理机制,如自动机模型。因为在某种程度上,着色类似确定化XPath,当处理复杂谓词时,其着色信息处理可以方便地吸收自动机模型的思想。
(4)非常容易扩展XPath查询数目,着色序列长度的增加对效率影响很小。
(5)方便进行类似关键词查询的流数据处理。如不考虑数据来源的结构,用户只关心信息中的author或name的信息。本文模型可以很容易且高效的去完成处理,仅需传入//author、//name的XPath表达式串,就可以应用于任意的XML流数据源。
3 GBRender的主要算法
以单枝查询为例简要介绍GBRender查询模型中的着色算法与处理算法。
在单一分枝的查询中,由于XPath表达式中仅有//与/关系,组标签对于XPath路径中的元素只存在3种关系,即无、中间元素或终结元素,而本文关心的正是那些终结元素且此处暂不需考虑缓存,为了便于描述,用Color.Empty、Color.Mid以及Color.End来表示2种着色状态。
(1)单一分枝下的组着色算法:
GroupRendering(G, XPaths)
输入:组G是当前元素所在组,表达式串XPaths是XPath表达式集合
{
Foreach(xpath in XPaths)
{
If(G.tagPath not satisfy part xpath) //未发现匹配,e.tagPath为标签路径
G.XPathColorList.add(Color.Empty);
If(G.tagPath satisfy part xpath) //有匹配
If(G.tagPath is 终结元素) //是终结元素
G.XPathColorList.add(Color.End);
else //不是终结匹配但匹配中间元素
G.XPathColorList.add(Color.Mid);
}
}
(2)endElement时根据组着色情况对元素进行处理的算法:
ProcessXPathColor (G)
输入:组G是当前元素所在组
{
Foreach(color in G.XPathColorList)
{ //单枝查询情况下只需要对Color.End元素进行处理
Costomeri ++; // XPath逐个对应
If(color is Color.End)
{
ToCustomer(Customeri,G.currentElement.Value); // 输出结果
}
}
}
4 实验
本文实现了GBRender查询模型并应用在单枝查询上,软件环境是Windows xp+eclipse3.3+jdk1.5。硬件环境是:联想旭日410M笔记本电脑,配置为:CPU双核T2080,内存1 GB,硬盘120 GB。
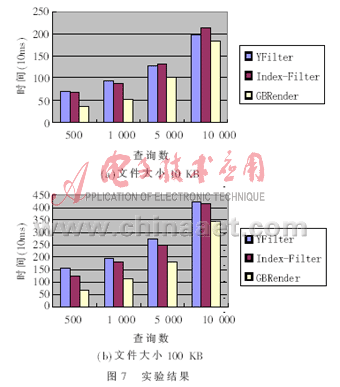
在实验中,综合了文档大小与查询数目的多少并与YFilter和Index-Filter作比较,结果发现,当文档相对较大时查询数量无论多少,GBRender都显得非常有效;当文档相对较小而查询数量较大时,GBRender与YFilter较为有效。实验结果如图7所示。
本文提出了一种新的XML数据流XPath查询模型GBRender,给出了该模型的结构特征、处理机制以及单枝查询下的多XPath查询算法和组着色的概念。通过大量的实验,证明了GBRender模型对XML任意数据流查询的有效性及其适用性强的优点。
GBRender模型具有较强的适应性与灵活性,对某些结构简单的XPath查询极其有效。但在根据着色信息进行处理机制上有待进一步的研究。今后主要的工作是如何有效地在组着色机制中利用已有的好的查询机制或新的有效的处理机制进行复杂XPath查询处理,进一步完善系统。
参考文献
[1] BERGLUND A, BOAG S, CHAMBERLIN D, et al. XML path language(XPath)2.0 W3C working draft 16. Technical Report,WD-xpath20-20020816,World Wide Web Consortium,2002.http://www.w3.org/TR/2002/WD-xpath2002-08-06.
[2] BRUNO N, GRAVANO L, KOUDAS N, et al. Navigation-vs. index-based XML multi-query processing.In: Dayal U, Ramaritham K, Vijayaraman TM, eds.Proc of the 19th Int’l Conf. on Data Engineering(ICDE 2003). Bangalore: IEEE Computer Society, 2003:139-150.
[3] ZWON J, RAO P, MOON B, et al. FiST:scalable XML document filtering by sequencing twig patterns.Proc. of the 31st Int'l Conf on Very Large Data Bases (VLDB 2005).Trondheim:VLDB Endowment, 2005. 217-228.
[4] 杨卫东,王清明,施伯乐.针对XML流数据的复杂Twig Pattern查询处理.软件学报,2007,18(4):893-904.http://www.jos.org.cn/1000-9825/18/893.htm
[5] DIAO Y, FISCHER P. YFilter: efficient and scalable filtering of XML documents. In: Proc of the 18th Int'l Conf. on Data Engineering, 2002:341-345.