
文献标识码: A
文章编号: 0258-7998(2011)10-0123-03
超高、超长、大跨度的复杂建筑工程设计涉及大量的复杂计算,对高性能计算技术有着重大的需求。目前,传统的建筑工程设计的高性能有限元分析软件工具主要基于并行计算技术。高性能并行计算以MPI标准为代表[1],其中最为著名且被广泛使用的是由美国Argonne 国家实验室完成的MPICH,它广泛应用于各种建筑结构计算软件(如ANSYS、FLUENT、PATRAN)中。然而,MPI进行数据处理主要方式是将作业分配给集群,由集群访问以存储区域网络为管理基础的共享文件系统,在大量数据的情况下网络带宽将限制这种处理方式[2],而新出现的云计算技术能够有效地解决这个问题。云计算是IT界新近提出的以Hadoop技术为代表的分布式计算模式,Hadoop的MapReduce模式具有计算节点本地存储数据的特性,能够有效地避免MPI的网络带宽限制问题。相对于MPI赋予程序员的可控性,MapReduce则是在更高的层面上完成任务。
本文阐述了建筑结构并行计算(MPI)的云计算的应用方法和思想,利用Google的MR_MIP库(Library)结合相应程序接口,发挥两种计算方法各自的优势,实现了云计算与MPI相互融合。既利用了传统的基于并行计算技术的建筑计算软件的丰富资源,又使用云计算技术解决了现有方法存在的问题。
1 云计算与Hadoop
云计算(Cloud Computing)是网格计算、分布式处理和并行处理的发展[3],是计算机科学概念的商业实现。其基本原理是把计算分配到大量的分布式计算机,而不是分配到本地计算机或远程的服务器上,使企业数据中心的运行类似于互联网。企业能够将有限的资源转移到需要的应用上,并根据自身需求访问计算机及存储系统,降低了企业的成本。
云计算是一种革命性的举措,即把力量联合起来给其中的某一个成员使用,计算机的计算能力能像商品一样费用低廉取用方便。云计算最大的特点是通过互联网提供服务,只需要一台笔记本或者一个网络终端,而不需要用户端安装任何应用程序实现需要的一切,甚至包括超级计算等服务。
IBM于2007年底推出了“蓝云(Blue Cloud)”计划,同时推出许多云计算产品。通过构建一个类似分布式的资源结构,把计算从本地机器和远程服务器转移到类似于互联网的数据中心运行。Hadoop是基于Google Map-Reduce计算模型的开源分布式并行编程框架[4],根据Google GFS设计了自己的HDFS分布式文件系统[5],使Hadoop成为一个分布式的计算平台。同时还提供了基于Java的MapReduce框架,能够将分布式应用部署到大型廉价集群上。
Hadoop主要由分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce两部分构成。HDFS 有着高容错性的特点,并且设计用来部署在低廉的硬件上。它提供高传输率来访问应用程序的数据,适合那些有着超大数据集的应用程序。MapReduce依赖于HDFS实现,通常MapReduce会在集群中数据的宿主机上进行最便捷的计算。
2 MPI标准
消息传递接口MPI(Message Passing Interface)是支持在异构计算机上进行计算任务的并行平台[6],它是一种编程接口标准,而不是一种具体的编程语言。该标准是由消息传递接口论坛MPIF(Message Passing Interface Form)发起讨论并进行规范化。该标准的主要目的是提高并行程序的可移植性和使用的方便性。MPI并行计算环境下的应用软件库以及软件工具都可以透明地移植,是目前最重要的并行编程工具。MPI的最大优点是其高性能,具有丰富的点到点通信函数模型、可操作数据类型及更大的群组通信函数库。
MPI标准定义了一组具有可移植性的编程接口。设计了应用程序并行算法,调用这些接口,链接相应平台上的MPI库,就可以实现基于消息传递的并行计算。正是由于MPI提供了统一的接口,该标准受到各种并行平台上的广泛支持,这也使得MPI程序具有良好的移植性。目前MPI支持多种编程语言,包括Fortran 77、Fortran 90以及C/C++;同时,MPI支持多种操作系统,包括大多数的类UNIX系统以及Windows系统等;同时还支持多核、对称多处理机、集群等各种硬件平台。
2.1 MPI的通信模式
(1)标准通信模式(StandardMode)。在MPI采用标准通信模式时,是否对发送的数据进行缓存是由MPI自身决定的,而不是由程序来控制。如果MPI决定缓存将要发出的数据,发送操作不管接收操作是否执行都可以进行,而且发送操作可以正确返回而不要求接收操作收到发送的数据。
(2)缓存通信模式(BufferedMode)。缓存通信模式若需要直接对通信缓冲区进行控制,可采用缓存通信模式。在这种模式下由用户直接对通信缓冲区进行申请、使用和释放,因此缓存模式下对通信缓冲区的合理与正确使用是由程序设计人员自己保证。采用缓存通信模式时,消息发送能否进行及能否正确返回,不依赖于接收进程,而是完全依赖于是否有足够的通信缓冲区可用,当缓存发送返回后,并不意味者该缓冲区可以自由使用,只有当缓冲区中的消息发送出去后才可以释放该缓冲区。
(3)同步通信模式(Synehronous-mode)。同步通信模式的开始不依赖于接收进程相应的接收操作是否己经启动,但是同步发送却必须等到相应的接收进程开始后才可以正确返回。因此同步发送返回后意味着发送缓冲区中的数据已经全部被系统缓冲区缓存,并且己经开始发送,这样当同步发送返回后,发送缓冲区可以被释放或重新使用。
(4)就绪通信模式(Ready-mode)。在就绪通信模式中,只有当接收进程的接收操作已经启动时才可以在发送进程启动发送操作,否则当发送操作启动而相应的接收还没有启动时发送操作将出错。就绪通信模式的特殊之处在于它要求接收操作先于发送操作而被启动,因此在一个正确的程序中,一个就绪发送能被一个标准发送替代。该模式对程序的语义没有影响,而对程序的性能有影响。
2.2 MPI调用的参数说明
对于有参数的MPI调用,MPI首先给出一种独立于具体语言的说明。对各个参数的性质进行介绍,然后在给出它相对于FORTRAN和C的原型说明。在MPI-2中还给出了C++形式的说明,MPI对参数说明的方式有IN、OUT和INOUT三种。它们的含义分别是: IN为输入调用部分传递给MPI的参数,MPI除了使用该参数外不允许对这一参数做任何修改;OUT为输出MPI返回给调用部分的结果参数,该参数的初始值对MPI没有任何意义;INOUT为输入输出调用部分,首先将该参数传递给MPI,MPI对这一参数引用、修改后,将结果返回给外部调用。该参数的初始值和返回结果都有意义。
如果某一个参数在调用前后没有改变,例如某个隐含对象的句柄,但是该句柄指向的对象被修改了,则这一参数仍然被说明为OUT或INOUT。MPI的定义在最大范围内避免了INOUT参数的使用,因为这些使用易于出错,特别是对标量参数的使用。
还有一种情况是MPI函数的一个参数被一些并行执行的进程用作IN,而被另一些同时执行的进程用作OUT。虽然在语义上它不是同一个调用的输入和输出,这样的参数语法上也记为INOUT。
当一个MPI参数仅对一些并行执行的进程有意义,而对其他的进程没有意义时,不关心该参数取值的进程可以将任意的值传递给该参数。如图1所示。

3 建筑并行云计算架构
3.1 ANSYS分布式并行计算
ANSYS软件是最常用的建筑结构有限元求解软件之一,其核心是一系列面向各个领域应用的高级求解器。ANSYS支持在异种、异构平台上的网络浮动,其强大的并行计算功能支持共享内存(share memory)和分布式内存(distributed memory)两种并行方式。共享内存式并行计算,是指单机多CPU的并行计算、分布内存式并行计算及多机多CPU的并行计算;分布式内存并行往往比共享内存并行有更好的并行效能,ANSYS分布式求解技术核心是基于MPI的编制的计算程序。近几年,随着CPU多核,高速互联等技术的发展,低成本高效率的Linux集群系统成为高性能计算平台的主流。
3.2 Hadoop的MapReduce 模式计算流程
Hadoop的MapReduce计算架构实现了由Google工程师提出的MapReduce编程模型。它将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了Map和 Reduce两个函数, 待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。MapReduce的计算流程如图2所示。
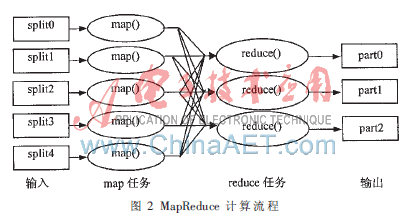
(1)数据划分。首先将数量众多的文件进行划分,分成大小不一的若干小块数据。通常数据块大小可以由用户根据需要自行控制,然后将这些数据块备份分配到各个机器集群中存储。
(2)读取数据并在本地进行归并。被指定执行映射任务的工作站节点读取要处理的数据块,然后从原始数据块中将数据解析成键/值的形式,通过用户定义的映射函数处理得到中间键/值对,存入本地内存缓冲区。缓冲区中的数据集合被划分函数分配到各个区域,然后写入本机磁盘。返回管理机本地磁盘中数据的存放位置信息,管理机随后将这些数据位置信息告诉执行规约任务的相关工作站节点。
(3)指派映射/规约任务。在这些数据块备份中有一个管理机主程序,其余的均为工作站节点程序,由管理机指派任务给各工作站。主程序将指派处于空闲状态的工作站来执行规约任务或映射任务。
(4)远程读取。在通知执行归并任务的工作站数据的存储位置信息后,reduce工作站通过远程方式读取执行map任务工作站中的缓存数据。reduce工作站取得所有需要的中间数据后,按照关键字对中间数据键/值对进行排序,把相同关键字的数据划分到同一类中去。不同的关键字映射后都要进行相同的规约操作,所以对中间数据进行排序非常必要。假如产生的中间数据集的数量非常大无法存入内存,可以利用外部存储器存储。
(5)写入输出文件。最后的reduce工作站对每个归并操作的中间数据按中间关键字进行排列,传送中间键/值对数据给用户定义的归约函数。归约函数的最终输出结果将被追加到输出结果文件中。在所有的映射任务和归约任务完成之后,管理机唤醒用户程序以继续之前的程序执行,完成下一阶段的任务。
3.3 建筑结构并行云计算方法
建筑结构有限元求解软件ANSYS支持MPI并行编程模式,如何利用其高效的性能并结合云计算技术是一个新出现的研究问题。使用Google提供的MR_MIP库(Library)能够解决这个问题。MR-MPI提供了云计算的MPI库,结合相应程序接口可以实现并行计算与云计算的结合。图3给出了两种先进的计算技术结合的高效能计算过程。

在建筑结构并行云计算的执行过程中,Master占据核心位置,为计算程序的顺利运行提供各种服务并负责任务的调度。为将要执行的MPI程序提供MR-MPI库,同时选择执行Map和Reduce程序的节点机,读取节点机上相应的数据块进行分布式并行计算。同时Master还定期探测worker,当某个testworker任务失败时,相应的map操作将被通知重起。这种计算模式综合了云计算和并行计算的各自优势,在高速计算的同时又实现了系统的负载均衡和故障恢复。
高性能计算技术可高效地解决建筑行业中大型复杂结构高精度分析、优化和控制等问题,从而促进建筑工程结构设计水平和设计质量的提高。本文给出了将Hadoop的MapReduce计算架构与MPI相互整合的应用方法,提出了云计算在建筑结构程序并行化上的应用,为大规模工程计算技术发展提供了新思路。
参考文献
[1] MATTSON T G. 并行编程模式[M].北京:清华大学出版社,2005.
[2] 王文义,刘辉.并行程序设计环境MPICH的应用机理分析[J].计算机应用,2004,22(4):1-3.
[3] 王鹏. 云计算的关键技术与应用实例[M]. 北京:人民邮电出版社, 2010.
[4] WHITE T. Hadoop: the definitive guide[M].Oreilly Media, 2009.
[5] GHEMAWAT S, GOBIOFF H, LEUNG S T. The google file system[J].ACM SIGOPS Operating Systems,2003,9(8):1-5.
[6] 张林波,迟学斌,莫则尧.并行计算导论[M].北京:清华大学出版社,2006.