
摘 要: 提出了利用2个麦克风基于FPGA的声源定位的方法。具体通过基于相位变换改进的互相关方法成功在低信噪比(10 dB)的噪声环境下完成声源定位。利用同样的算法和硬件结构,可以在1片FPGA芯片上实现5组并行的时域处理的系统,而且每个麦克风的功耗只有77 mW~108 mW。
关键词: 声源定位;时延估计;FPGA
实时声源定位在许多方面得到了应用,例如声音的识别和电话会议,可以利用阵列麦克风来实现对多个声源信号的获取和并行处理[1-3]。由于处理多路语音信号需要多个处理器,使得其实现费用昂贵,即便是使用DSP,系统也会带来很大的功耗,因而限制了其在许多实际中的应用。例如Brown大学发展的大规模麦克阵列系统利用多个DSP处理器和缓冲器来实现声源的定位,每个麦克的功耗达到了400 mW。这大大超过了一些便携式设备(PDA和手机)的功耗,因此最好的解决办法是设计专用芯片。
本文将阐述声源定位系统在FPGA中的实现,为专用芯片提供一个可行性参考,具有很好的商业应用价值。以前采用DSP[4]或是DSP+FPGA[5]实现多路声源信号的定位,而本设计的整个定位系统除了前端的模拟部分外其余部分均在FPGA中实现。采取有效的算法后,整个硬件实现的功耗可以控制在77 mW~108 mW之间。
1 声源定位的算法
现有许多算法[1-4]实现声源定位,包括基于信号子空间的方法(例如MUSIC算法)和空间似然方法[2,4]等,最为常用的方法是估计信号的对应的麦克对到达延时(TDOA)[3]估计方法。该方法的每一组麦克对将声源定位在3维空间的一个双曲面上,这样通过多个麦克对确定的双曲面的交点能有效地实现声源的定位。TDOA估计方法已进行了很多研究[3,6],最为普通的是广义互相关GCC(Generalized Cross Correlation)方法[6]。与其他的方法相比,基于GCC的方法计算量小、计算效率高。
假设2个麦克各自接收的信号分别为m1(t)和m2(t)(包括噪声、回响和声音的延时信号)。常用的估计延时的方法是互相关方法:



PHAT权系数对应的是相位变换,在回响环境中效果明显[1,3,6]。UCC权系数为1,对应的是单纯的互相关而没有经过滤波处理。
离散信号的GCC表示为:

如果采用方波作为补偿函数,(4)式可以写成:
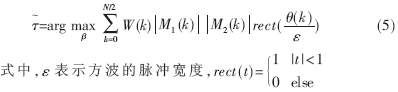
与(4)式相比,(5)式用来估计TDOA的好处在于计算量的减少,而且在低的信噪比下具有更好的性能,所以本文采用的是(5)式在FPGA中的实现。
2 FPGA的实现
设计中只考虑最简单的一对麦克风的TDOA的估计,每个麦克风接收的信号经过放大、带通滤波后以20 kHz的频率进行采样,每个采样的数据宽度为24位。取量化后的高8位送往FPGA(Xilinx Virtex II 2000)中进行运算。尽管只讨论了1对麦克风的情况,多个麦克风对也能在同一个FPGA中实现(本文将会在后面具体介绍)。
输入的采样信号分别存储在2个Buffer里(Buffer的大小为256~1 024个采样点),然后将输出信号经过汉宁窗滤波,将数据转化为16位的浮点数存储在FFT的Buffer中,FFT模块将各自的Buffer中的数据进行FFT运算,如图1所示。
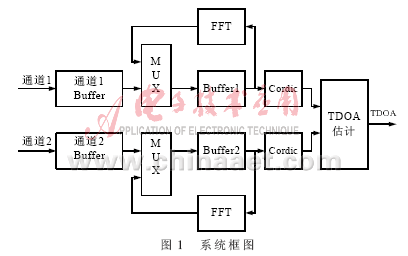
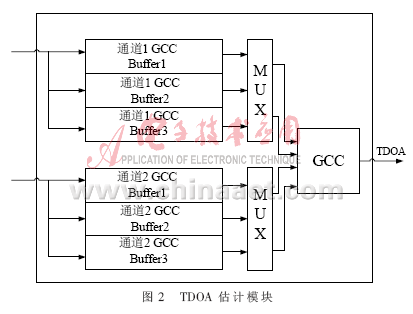
在FPGA的实现过程中采用CORDIC算法,它将傅里叶变换的复数表达形式转换成幅度和相位表达形式,在能够减少计算量的同时不增加硬件的资源。2路信号的幅度和相位计算出来后利用(5)式得到TDOA的估计,如图2所示。估计的过程涉及到根据(5)式搜索最大的τ,搜索的范围从-30 Ts~30 Ts(步进为采样周期Ts),ε=0.5。为了实现TDOA的实时估计,硬件部分主要由3部分组成:输入信号采集部分、FFT的计算及幅相转换部分、TDOA的估计部分。2个Buffer已经能够满足GCC前端数据缓存的要求,但考虑到CORDIC算法的误差,设计中多用了1个Buffer储存数据的复数形式,为系统的误差分析提供数据,确保定位精度。
3 实验结果
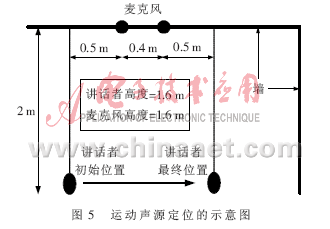
在实验中Buffer的大小为1 024位,对应的时间缓存时间为50 ms。麦克风对按前面介绍的方法安置。第一个实验是对固定声源的定位,讲话人在房间内固定的地方说话,如图3所示。
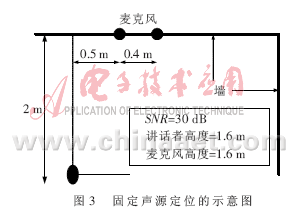
要注意保持麦克风对与讲话者嘴的高度一致。将麦克风得到的数据经过放大、滤波、采样和FPGA处理。系统噪声由麦克风、放大器或滤波器等器件引入,信噪比为30 dB。利用麦克风获取的50 ms的信号帧,分别用GCC和PHAT的权值来估计讲话者的TDOA。将每帧的到达时间时延τ转换成波达方向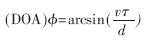 ,其中,v表示声音的传播速度(取345 m/s),d表示2个麦克风之间的距离(d=0.4 m)。
,其中,v表示声音的传播速度(取345 m/s),d表示2个麦克风之间的距离(d=0.4 m)。
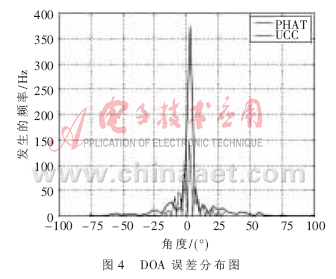
通过DOA的估计和实际的DOA来计算DOA的误差,实际的DOA可以通过讲话者在环境的实际位置得到。DOA误差如图4所示。利用PHAT权值的TDOA定位精度要比UCC的好,因此试验中利用的是PHAT权值。为了得到基于FPGA的声源定位系统在运动的声源和不同背景噪声下的性能,本文利用PHAT权系数分别进行实验。如图5所示,讲话者从一个地方移动到另外一个地方,整个移动持续1 min,讲话者始终面对着麦克风对。
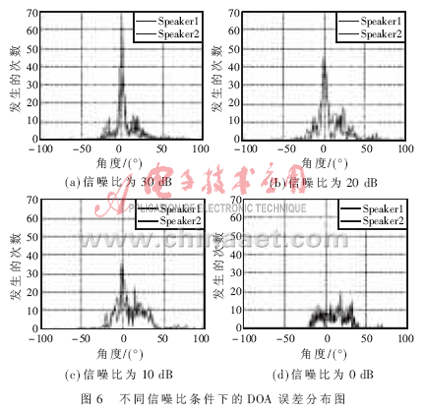
分别在信噪比为30 dB、20 dB、10 dB、0 dB的条件下对2个不同的讲话者做试验,当信噪比为30 dB时,噪声只由传感器和信号处理系统自身引入;当信噪比为20 dB、10 dB、0 dB时,则通过提供一个高斯噪声源来提供,通过调整噪声的强度可以实现信噪比的变化。信噪比为30 dB的DOA误差如图6(a)所示,在不同的信噪比条件下,0°的位置具有共同的峰值,但是随着信噪比的降低(20 dB和10 dB分别对应图6(b)和图6(c)),误差越来越大,当降到0 dB时起不到定位的作用,如图6(d)所示。
实时声源定位系统在Xilinx公司的xc3s1000 FPGA中实现,按文中提出的算法和实现方法可以实现10 dB信噪比以上的声源定位,整个系统具有很好的鲁棒性。通常的处理多对麦克风对的信号算法常常利用DSP,然而功耗的需求以及外围设备的复杂使得DSP在许多场合受到限制。利用本文介绍的算法,在FPGA Virtex II Pro-70中并行处理6个TDOA估计模块,时钟选取为10 MHz,功耗可以控制在0.776 W~1.074 W之间,试验消耗的逻辑门为1 192 793。通过流水线处理,如果系统的时钟为100 MHz,在1块FPGA中能并行处理50个TDOA估计模块,不过功耗要增大到7.76~10.74 W之间。由于Virtex II Pro-70有足够的存储空间,因此输入Buffer部分无需额外的逻辑门。与其他的方法相比,如大型麦克阵列每个麦克的功耗为400 mW[5],本文的方法的平均功耗要小得多(每个麦克77~108 mW),为减少VLSI电路的功耗提供了一个切实可行的途径。
参考文献
[1] AARABI P,MAHDAVI A.The relation between speech segment selectivity and time delay estimation accuracy. In Proceedings of ICASSP,May 2002.
[2] AARABI P,ZAKY S. Robust sound localization using mult-source audiovisual information fusion. Information Fusion, 2001,3(2):209-223.
[3] BRANDSTEIN M S, SILVERMAN H. A robust method for speech signal time-delay estimation in reverberant rooms.IN Proceedings of ICASSP,May 1997.
[4] PONCA M, SCHAUER C. FPGA implementation of a spike-based sound localization system. In 5th International Conference on Artificial Neural Networks and genetic Algorithms, 2001.
[5] SILVERMAN H F,PATTERSON W R,FLANAGAN J L.The huge microphone array.Brown University Technical Report,May 1996.
[6] KNAPP C H, CARTER G.The generalized correlation method for estimation of time delay.IEEE Tarnsactions on ASSP,1976,24(4):320-327.