
摘 要: 提出了一种基于DTW的符号化时间序列聚类算法,对降维后得到的不等长符号时间序列进行聚类。该算法首先对时间序列进行降维处理,提取时间序列的关键点,并对其进行符号化;其次利用DTW方法进行相似度计算;最后利用Normal矩阵和FCM方法进行聚类分析。实验结果表明,将DTW方法应用在关键点提取之后的符号化时间序列上,聚类结果的准确率有较好大提高。
关键词: 时间序列;DTW;SAX;Normal矩阵;FCM
时间序列(Time Series)挖掘是数据挖掘中的一个重要研究分支,有着广泛的应用价值。近年来,时间序列挖掘在宏观的经济预测、市场营销、客流量分析、太阳黑子数、月降水量、河流流量、股票价格变动等众多领域得到了广泛应用[1]。
时间序列的相似性是衡量两个时间序列相似程度的一个重要指标,它是时间序列聚类、分类、异常发现等诸多数据挖掘的基础,也是研究时间序列挖掘的核心问题之一[2]。欧氏距离(Euclidean)和动态时间弯曲距离(Dynamic Time Warping)是计算时间序列相似性时经常被采用的两种度量方式。欧氏距离对时间轴上的轻微变化非常敏感,一些轻微的变化可能使欧氏距离的变化很大,而动态时间弯曲距离可以有效地消除欧氏距离这个缺陷,动态时间弯曲可以广泛应用在自然科学、医学、企业和经济等方面[3]。SAX(Symbolic Aggregate Approximation)[4]是一种运用符号化方法对时间序列进行表示、维度约简及相似性度量的方法。但SAX方法采用PAA算法将时间序列平均划分,不能很好地计算序列之间的相似度。而利用均分点和关键点对序列进行分段,既考虑了序列本身概率分布的变化,又兼顾到序列形态的变化。
本文提出一种基于DTW的符号化时间序列聚类算法,在提取关键点之后,再进行符号化时间序列,以达到降维的目的。降维之后得到的符号序列为不等长序列,采用动态时间弯曲距离(DTW)方法进行计算, 鲁棒性好。然后通过DTW得到的距离矩阵构建复杂网络,并寻找其社团结构,实现了符号时间序列聚类。本文用DTW方法进行相似性度量比KPDIST[4]在聚类结果的准确率上有较好大提高。
1 相关知识
1.1时间序列关键点的选取
基于参考文献[5]可知,时间序列中的极值点EP成为关键点KP的条件为:
条件1. xi保持极值的时间段与该序列长度的比值必须大于某个阈值C;
条件2. 若条件1不满足,则包含xi的最小序列模式<xi-1,xi,xi+1>中, 三点连线形成的夹角小于筛选角度α0。

2.2 基于DTW的符号化聚类算法
输入:时间序列集。
输出:聚类结果。
(1)对每个序列,运用上面的算法得到最终的关键点序列;
(2)计算序列C在各区间[KPci,KPcj)内的均值,并表示为符号序列;
(3)对序列C和序列Q的符号序列进行相似性距离计算(DTW计算和KPDIST计算);
(4)根据相似度,构建复杂网络G;此处要给相似度赋予一个阈值,相似性小于阈值的点则认为无边连接。
(5)用Normal矩阵方法FCM算法对复杂网络G进行社团划分,得到聚类结果。
3 实验结果与分析
本文实验采用Keogh博士的Synthetic Control和ECG数据集。实验环境为2.66 GHz CPU Pentium@4 PC机, 1 GB内存,操作系统为Windows XP Professional。算法实现软环境为matlab 7.0和VC++6.0。Synthetic Control数据集的实验数据为300条,每条时间序列长度为60。ECG数据集有100个样本序列,每条时间序列长度为96(http://www.cs.ucr.edu/~eamonn/time_series_data/)。原时间序列维度为60和96,经过关键点提取、符号化之后,维度大大降低,这为后期处理带来了很大的方便。 在本实验中,关键点提取时筛选角度为45°,预设的压缩率为80%,划分了4个区间段,用符号表示时为a,b,c,d四种字母。由于实验数据的样本个数很多,这里只显示synthetic control的部分实验结果。表1为降维后的前4个符号序列实验结果。

表2为Normal矩阵得到的非平凡特征值对应的非平凡特征向量,根据谱平分算法思想,同一社团内的节点相应的元素xi非常接近。从特征向量的分析中可以看出,将DTW与复杂网络知识应用在符号化时间序列上是一种较好的创新。
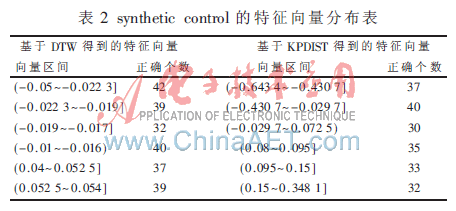
由DTW距离矩阵得到的网络中,第一非平凡特征值取值为:0.252 9,而通过KPDIST距离矩阵得到的复杂网络中,第一非平凡特征值取值为:0.125 7,从特征值中就可以初步判断,DTW得到的特征值更为准确,这两个特征值对应的特征向量的区间表如表2所示。
表3为两种算法对同样数据集进行聚类得到的结果。数据集Synthetic control采用本文方法正确率为76.3%。而利用KPDIST算法正确率为69%;数据集ECG,本文的正确率为72%,KPDIST的正确率为65%。

SAX是一种符号化的时间序列相似性度量方法,该方法在对时间序列划分时,采用了PAA算法的均值划分,得出的结果不能精确地表示出原时间序列,故将关键点提取方法与PAA方法相结合,在对原序列降维的同时又能更准确地表示原时间序列。本文将复杂网络知识和时间序列降维方法相结合,给出了一种时间序列的聚类方法。该算法用DTW算法计算时间序列间的相似度,而后从时间序列的相似度得到一个复杂网络,此复杂网络表示了时间序列相互间的关系。最后采用Normal矩阵的方法进行网络划分,得到一个网络的社团结构。从这个社团结构中已能看出样本时间序列的归属类别,但为了结果更加清晰,用具体数字来体现,所以采用了FCM聚类算法进行最后的聚类。实验结果表明,用DTW方法计算序列之间的相似度结合在降维后的符号化时间序列上比原文KPDIST方法在准确率上有较好大提高。
参考文献
[1] 毛国君,段立娟,王实,等.数据挖掘原理与算法(第二版)[M].北京:清华大学出版社,2007.
[2] 刘懿,鲍德沛,杨泽红.新型时间序列相似性度量方法研究[J].计算机应用研究,2007,24(5):112-114.
[3] KEOGH E, RATANAMAHATANA C A. Exact indexing of dynamic time warping[J]. Springer-Verlag London Ltd, 2005, 10.1007/s10115-004-0154-9:358-386.
[4] 闫秋艳,孟凡荣.一种基于关键点的SAX改进算法[J].计算机研究与发展,2009,46(z2):483-490.
[5] 杜奕.时间序列挖掘相关算法研究及应用[D].合肥:中国科学技术大学,2007.
[6] 汪小帆,李翔,陈关荣.复杂网络理论及其应用[M].北京:清华大学出版社,2006:169-171.