
网格计算技术在数字油藏模拟领域的应用
2009-08-19
作者:孟照旭
摘 要: 本文测试了基于网格计算技术的PC 集群系统在大规模油藏模拟中的使用,测试结果显示大规模油藏模拟在最新的PC集群系统上高效运行是可行的。
关键词: 油藏模拟 网格计算 PC集群 高速网络
1 数字油藏模拟对计算机性能的要求
在油田开发、地质研究、大规模并行油藏模拟应用方面,目前使用的主流数值模拟软件有美国Schlumberger公司的并行Eclipse,美国Landmark公司的并行VIP和加拿大CMG公司的STARTS。这3个软件都能够提供数值模拟的前期预处理、模拟、后期处理的完整工作流模式,模拟黑油、组份和裂缝模型。当前被模拟的油藏模型从几十万个单元到几千万个单元,运行平台主要是在专业的并行机。在未来几年,随着老油区开发难度的增大,油藏模型的面积和数量将会明显地增加和扩大。如果继续用传统的并行计算机来模拟,为了达到理想的模拟速度和效果,其硬件平台的投资将很高。由于网格计算技术的发展,并行机市场不断萎缩,其系统的扩容、维护等都存在很大的问题。为了应对面临的挑战,本文对今后的数值模拟的硬件平台作了一系列性能评估测试,其目的就是要去验证和评估一个低成本、高性能的计算平台,以满足企业对油藏模拟的不断增长的计算需求。
2 网格计算的发展
随着微处理器、高速网络、网格计算技术和Linux系统的发展,基于低成本的PC架构的服务器和高速网络构成的Linux集群系统在高性能并行计算领域逐渐兴起。网格计算为工程师、科研人员、和其他需要专门、高性能计算的人员提供了无缝的、对分布式计算的透明访问的服务,促成对已安装的IT设施的更好使用率,跨平台和地区的计算能力的更灵活管理和对资源的更好访问。
网格计算的目标是实现资源的集中调度、模块化可扩充的计算节点、资源的透明访问和负载均衡。当前正在建设的网格系统都是以PC集群作为网格主节点,再通过网格中间件,将其他异构的系统加入其中。PC集群是通过高速交换网络连接的PC服务器的集合,其优秀的性能得益于其计算核心(CPU)的性能的极大提高。目前,典型的PC集群采用的处理器的性能(例如主频为1.8GHz的Opteron处理器)要远远超过传统的并行机采用的处理器,3个处理器的性能(SPECfp2000,主要用于衡量处理器浮点运算性能)对比如图1所示。

Power3处理器用于IBM SP2并行系统,Xeon以及Opteron处理器被广泛地使用在低价位的PC服务器上。SPECfp2000测试值仅仅是衡量系统性能的一个指标,一个系统的整体性能高低还是要以应用软件的运行效率来判断。处理器性能测试指标和处理器价格相比,PC集群比并行计算机有更好的性价比。
当前IBM SP2并行机是新疆油田作数值模拟的计算平台,运行LandMark VIP和Schlumberger Eclipse。在国外,石油公司逐步采用了基于网格技术的PC 集群系统替代原有的并行机来作油藏模拟。
3 测试平台的选型
为了验证集群系统是否可行,我们和应用集成商合作搭建了32个节点的基于双AMD Opteron 64位处理器的系统,节点间通信实验了Infiniband、Myrinet、千兆以太网3种互联方式。系统支持MPI调用和OpenMP二种并行机制。油藏模拟软件选择Landmark公司的VIP,计算网格的资源调度、作业分配都由VIP软件来完成。
测试在IBM SP2并行机和运行Linux系统的PC集群平台上进行。IBM SP2使用4个节点,8个222MHz Power3处理器。PC集群系统是基于千兆以太网、Myrinet 高速交换技术和AMD Opteron 64位处理器。在配置集群系统时,应从以下5点考虑:处理器(CPU)、网络连接、内存、I/O以及管理软件等工具。
在集群的处理器方面,主要考察了Intel的Xeon处理器以及AMD的Opteron处理器。因为Intel处理器应用范围广,应用软件兼容性好,而AMD Opteron 64位处理器可以向下兼容32位应用,可以保护以前在32位平台上的软件投资,并且在未来软件升级到64位后,无需更换硬件平台,保护了硬件的投资。从处理器性能等方面综合考虑,选择了基于Opteron处理器的集群平台。
在高速交换方面有几种选择:千兆以太网、Myrinet、Quadrics、Infiniband。4种交换网络的性能参数对比如表1所示。
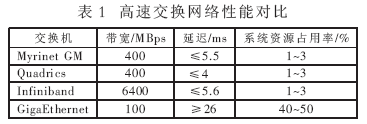
VIP并行油藏模拟软件要求高速、低延迟的通信方式,因为计算节点之间需要大量的数据交换去计算相邻网格单元边缘处的偏移。千兆以太网价格低,但是带宽窄、延迟大,可以作为集群管理和I/O网络,但不适于节点间的数据通信(节点间的通信带宽至少要200MBps)。Myrinet、Quadrics、Inifiband在带宽和延迟方面都可以满足VIP软件的要求,结合应用需求最终选择Myrinet。
存储选择采用SCSI技术的NAS系统,计算节点访问存储采用千兆以太网。集群系统的管理采用了基于浏览器的监控软件,可以实时检测每个计算节点的CPU、机箱内温度、风扇转速等参数以及系统资源利用率等。
4 测试结果
在测试中,选择了国外某油田100万个网格(有效网格85万个)、8个断层、7个组分、100个井的模型。从2001年开始模拟时间20年,并行分区64个,共设计了单个节点(2个CPU)、4个节点(8个CPU)、8个节点(16个CPU)、16个节点(32个CPU)、32个节点(64个CPU)5个方案进行测试。交换网络采用千兆以太网和Myrinet。在测试中,验证了多处理器集群性能的关键指标:精度、解法稳定性、并行效率。
4.1 计算精度和解法的稳定性
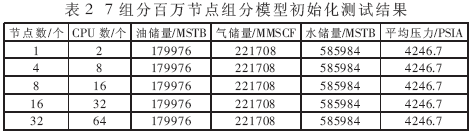
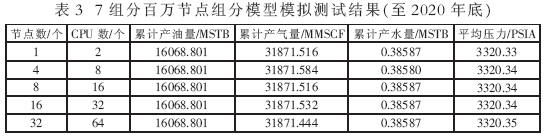
测试表明,几个方案初始化结果的油储量、气储量、水储量、原始油藏压力完全相同;计算到2020年底,几个方案模拟结果的累计产油量完全相同,累计产气量、累计产水量及平均压力基本相同,如表2、表3所示。
4.2 并行效率
评价并行软件效率高低的主要指标是加速比、加速效率、增量加速比和增量加速效率,其中加速比包括实际加速比和理想加速比2个概念。当运行某一作业时,实际加速比是指使用多个CPU时的作业运行时间与只用1个CPU时的作业运行时间之比;理想加速比是指使用多个CPU的理想运行时间与只用1个CPU的运行时间之比。加速效率指实际加速比与理想加速比之比的百分数。
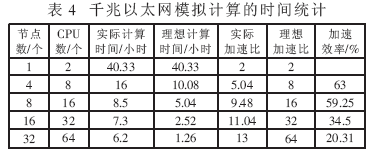
4.2.1 千兆以太网(GbE)
千兆以太网模拟计算的时间统计如表4所示。由表4可知,在千兆以太网环境下,4、8、16、32个节点的加速效率为63%~20.31%,其中4、8节点分别为63%、59.25%,16和32个节点的加速效率明显下降,只有34.5%和20.31%,增量加速效率均不高,为59%左右。分析表明,随着节点数的增多,节点与节点之间的数据交换占用了大量的时间,CPU的利用效率明显降低。因此在多节点的情况下,节点之间的数据交换成为制约运算速度的瓶颈。
4.2.2 Myrinet交换网络
由表5可以看出,8个CPU的加速比为6.92,加速效率为86%,16个CPU的加速比为12.22,加速效率为76%,均达到较为理想的加速比。
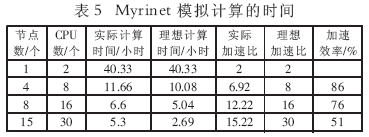
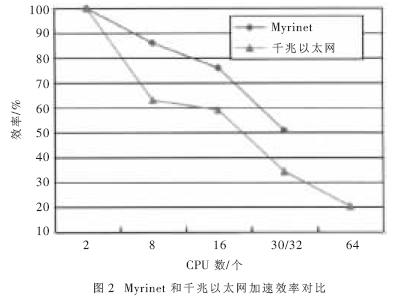
Myrinet和千兆以太网加速效率对比如图2所示。图2数据表明,这种紧耦合应用的集群系统中,由于并行节点间需要大的数据交换,所以节点间数据交换的效率将极大地影响并行软件运算的效率,因此Myrinet以其高带宽和低延迟而取得了比千兆以太网好得多的加速比。另外,将这组数据输入到IBM SP2的4个节点8 CPU的并行机上模拟,系统运行了30.2个小时后,同样CPU个数的基于Myrinet的PC集群的运算时间为11.66小时;基于千兆以太网的PC Cluster运算时间是16小时,速度比IBM SP2提高了2.6~1.9倍。而同样配置的硬件平台的价格相差就更大了。
4.3 其他相关问题
在测试中,其他例如兼容性、管理、I/O存储等方面问题,需要在将来改进。
(1)Linux的兼容性问题。开源的Linux可以降低拥有成本,但由于硬件平台的品牌太多,在支持不同的板卡、网络等方面,缺乏统一的解决方案,因而在构建应用系统时,需要做很多的测试来保证软件和硬件的匹配和兼容。
(2)现在的PC集群系统是由许多1U高度的机架式低端服务器集成在一个机柜内的,因此散热等问题将考验这样一个集合的系统的稳定性。同时要考虑这么多通过网络连接起来的、物理上独立、逻辑上相关的服务器怎样集中监控管理,才能保证其作为一个完整的系统发挥最佳的运算效能。所以选择产品时,就要考虑设备厂商是否有对集群系统可靠的产品和完整网格计算的解决方案。目前国际上有许多网格的工程在开展,如Globus、Gridbus Tools等,而且涉及到网格中间件、资源调度、开发工具、安全等方面。因此在组建网格系统时要跟踪这些工程的进展,才能有效地利用这些技术,最大地发挥网格系统的运算能力,达到最佳的性能指标。
(3)I/O存储问题。在PC 集群系统中,由于计算节点间要共享存储系统,当计算节点很多时,就存在着访问网络的瓶颈问题。目前有多种解决瓶颈问题的方案可供选择,例如:①采用SAN方式解决计算节点的访问瓶颈问题,但这种方案投资高。②后端采用SAN存储网络,前端采用多个I/O节点进行复杂均衡。③正在进行试验的许多新方案,例如并行虚拟文件系统(PVFS)、面向对象的存储(OOS)等。至于如何选择,要从应用的性能、兼容性和成本费用等方面综合考虑。
5 结 论
根据本文的测试,可得出以下一些结论:
(1)PC集群系统在油藏数值模拟是一个表现很不错的硬件平台,从性能和成本等方面都是很有竞争力的选择。
(2)大规模的上百万网格的油藏模拟在PC Cluster上运算是切实可行。
(3)系统管理、I/O问题将在大规模计算节点的集群中显得更加突出。
(4)基于Linux的网格集群技术将在油田勘探开发中扮演更加重要的角色,所以在新的系统选型中应综合考虑系统的性价比。
参考文献
1 Buyya R.High Performance Cluster Computing Architectures and Systems.ISBN,1999;(1)
2 孟杰.MPI 网络并行计算系统通信性能及并行计算性能的研究.小型微型计算机系统,1997;18(1)
3 Feng P,Jianwen C.Parallel Reservoir Integrated Simulation Platform For One Million Grid Blocks Case.超级计算通讯,2004;2(3)
4 Wheeler M F.Arbogast T,Bryant S et al.A Parallel Multiblock/Multidomain Approach for Reservoir Simulation.Paper SPE 51884 Presented at the 1999 SPE Symposium on Reservoir Simulation,Houston.Texas,1999