
一种基于模糊模板匹配的车牌汉字识别方法
2009-08-25
作者:吴 炜,杨晓敏,刘大宇,何小海
摘 要: 针对车牌汉字识别提出了一种基于二值图形变动分析的模糊模板匹配的车牌汉字识别方案。介绍了该方法的具体实现算法和实验流程及结果。
关键词: 模式识别 车牌识别 模板匹配
字符识别属于模式识别的范畴,通常的字符识别方法可分为2类:基于字符结构(笔画特征)的结构识别和基于字符统计特征的统计识别。结构模式识别方法的优点是可以识别复杂的模式,缺点是需要进行笔画特征的提取,在输入图像质量不佳的情况下,这一点往往难以做到。在统计模式识别方法中,特征提取方便,识别速度与识别对象无关,但需要得到字符集的稳定特征,且在字符笔画较多时要求的特征量非常大。二种识别方法各有优缺点。
人类的视觉感知系统是一个鲁棒性很强的、能抵御实际中可能遇到的各种变形和噪声干扰的文字识别系统。人们的认字过程实际上是对汉字整体形象的把握,是对汉字图像全局的处理过程[1]。因而,汉字的整体信息在无笔顺识别中起着无法替代的重要作用。
统计模式识别借助概率论的知识,判断或决策对象的特征类别,使得决策的错误率达到最小。基于统计特征的识别方法先抽取识别对象的稳定特征,组成特征矢量,然后在字符集的特征空间中进行特征匹配。基于以上认识,在分析汽车牌照中汉字字符的特点后,采用了有别于结构分析的一种基于字符图像特征统计的模式识别方法进行汉字识别。同时针对统计方法无法区分的相似汉字,提取其微结构信息进行特殊的校正识别。
1 特征统计匹配
统计决策论其要点是提取待识别模式的一组统计特征,然后按照一定准则所确定的决策函数进行分类判决[2]。汉字的统计模式识别是将字符点阵看作一个整体,从该整体上经过大量统计得到所用特征,用尽可能少的特征模式来描述尽可能多的信息。所采用的方法有:特征统计的方法、整体变换分析法[3]、几何矩特征、笔划密度特征、字符投影特征、外围特征、微结构特征和特征点特征等。这些方法都具有各自的优缺点,应根据具体应用进行选取。主要方法有外围面积特征匹配法和网格特征匹配法。外围面积特征反映了字符的轮廓信息。外围面积特征提取法,主要是从周围形状的心理学知识来获得汉字信息的特征,即对文字周围上下左右的形状进行量化,从而构造特征向量。网格特征实际是结构模式识别和统计模式识别相结合的产物。字符图像被均匀或非均匀地划分为若干区域,称之为“网格”。在每个网格内寻找各种特征,如目标面积比例、交叉点、笔划端点的个数、细化后的笔划长度和笔划密度等。特征统计以网格为单位,即使个别点统计有误差也不会造成大的影响,从而增强了特征的抗干扰性。因此这种方法得到日益广泛的应用。在实际的车牌汉字识别中,当相同汉字的二值图形变动较小时该方法较有效。具体应用:将尺寸为34×66象素的汉字二值图均匀分成32个正方形的小区域(不考虑外边框的1个象素),统计每个8×8的小区域内目标象素(白色)所占的面积比例,就得到了归一化的32维特征矢量。统计多幅相同汉字的32维特征矢量,取均值作为该汉字的标准网格特征模板。识别时,计算待识别汉字的32维网格特征矢量与模板矢量之间的Euclid距离,求得最小距离值,其对应的汉字即为识别结果。在具体应用中,由于外部原因常常会出现字符模糊、字符倾斜的情况,而网格特征匹配方法对字符模糊和倾斜较敏感,因此鲁棒性不是很强,不适合实际应用。
2 模板匹配
考虑到以上2种主要识别方法存在的弊端,决定选用模板匹配的算法进行字符的识别。实际研究中发现,二值化的图形模板虽然直观,但其匹配计算过程过于简单直接,对倾斜、形变、残损、模糊的待识别字符匹配误差较大,因此鲁棒性较差。而灰度模板由于色彩、光照等因素影响,难以找到普遍适用的模板形式实现直接的匹配计算。综合以上二方面的问题,在引入统计模式识别思想的基础上,提出了基于二值图形变动分析的模糊模板匹配方案。
2.1 基于二值图形变动分析的模糊模板匹配
在含有汽车牌照的图像中,将汉字定位并提取出来以后,还要完成规格化、二值化等操作。即使是相同的汉字,由于车牌倾斜、模糊,特别是由于每次定位不可能完全精确一致等诸多因素的影响,导致在二值图中字体的形状、大小都会不同,字体位置也会发生不同程度的偏移。将这种二值图形的不规则现象称为图形的变动。在汉字识别的分析过程中,希望对图形变动的大小进行量化处理。因此,提出了求图形整体变动量的统计方法,其优点是不需要参照标准图形,可以进行客观评价,并构造出用于匹配识别的模糊模板。
对每一个车牌的汉字字符,选取n幅质量较好的参考图。将这n幅参考图规格化为17×33的标准大小后进行二值化处理,得到标准参考图fi(x,y)。因此每个车牌汉字字符都有n幅由0、1所组成的二值图像。将这n幅二值图像对齐后叠加,再进行归一化。得到的模糊图形F(x,y)。四个汉字的模糊图形模板(不同方向的视觉效果)如图1所示。
该模糊图形上每一象素点实际上都对应着一个概率值,该概率值代表白色目标(汉字笔划)在该点出现的可能性。例如在模糊模板中若某一点值为1,表明在所有参加统计的二值图形上汉字笔划都经过该点,其为白色目标象素的可能性是100%,为黑色背景象素的可能性是0;反之亦然。进行匹配识别时,对一幅切分后的待识别汉字灰度图,将其规格化、二值化,然后计算每一象素点与模板的吻合程度,即每一象素点正确匹配的置信度con(x,y)。引入置信度的公式:
f(x,y)为得到的二值化后的待识别图像,把所有点的置信度平均后得到总的置信度con作为判别依据。最大置信度con所对应的模板汉字作为匹配识别输出的结果。
公式中的width和height分别是归一化后标准图像的长和宽。通过对实验结果的分析发现,识别错误的图像,往往严重变形、模糊,二值化效果差。
2.2 基于二值图形变动分析的模糊模板匹配的改进算法
针对以上问题,提出了一种简单的改进算法。将切分后不同大小的灰度字符图像规格化为17×33的标准尺寸以后,将各象素点的灰度值线性变换到[0,1]区间,再与模糊图形模板匹配,计算Euclid距离,其最小距离值对应的模板汉字作为匹配识别输出的结果。该方法的优点是不用对灰度图像作二值化处理,避免了由于二值化操作带来的图像信息损失。特别是对一些模糊图像,若直接采用二值化效果较差,影响匹配准确度。因此使用该方法在一定程度上提高了识别正确率。
实验中发现,对少数明暗程度变化大或对比度不强的模糊图像,该方法也产生了少量识别错误。这是由于将待识别图像的各点灰度值线性拉伸到[0,1]区间后,原始图像明暗程度不同导致其平均值与对应模板的平均值并不一致,直接用Euclid距离进行匹配,带来了计算误差。因此引入了归一化相关性度量公式:
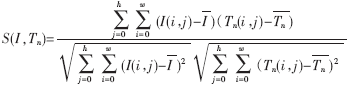
其中I(i,j)和Tn(i,j)分别是输入的待识别的字符图像和第n个模板,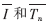 分别是输入字符图像所有灰度的均值和第n个模板的均值,w和h分别为图像的长和宽,S(I,Tn)是匹配函数,其值在0~1之间,代表待识别图像与模板图像的匹配程度。使用该公式计算相关性,可以避免由于明暗和对比度变化导致图像和模板的“能量”不一致而带来的匹配误差,进一步提高了匹配准确度。
分别是输入字符图像所有灰度的均值和第n个模板的均值,w和h分别为图像的长和宽,S(I,Tn)是匹配函数,其值在0~1之间,代表待识别图像与模板图像的匹配程度。使用该公式计算相关性,可以避免由于明暗和对比度变化导致图像和模板的“能量”不一致而带来的匹配误差,进一步提高了匹配准确度。
3 试验结果的进一步校正
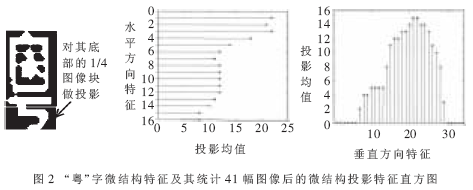
模板匹配表现的主要是汉字的整体特征,但是有些汉字存在着一定程度上整体的相似性,因此必须对相似的字符进行进一步的校正才能提高识别的正确率。对相似汉字的区分,往往是寻找其特有的笔划结构,这也是在统计模式识别中引入结构方法的必要之处。例如在车牌汉字识别中,“粤”字与其他省份汉字的最大区别是底部的钩状结构。为此对预处理后的17×33二值图像的底部1/4部分作水平和垂直方向的投影,水平投影17个特征值(由左、右二边分别投影得到),垂直投影33个特征值(由上、下二边分别投影得到),形成50维的微结构投影特征矢量。“粤”字微结构特征及其统计41幅图像后的微结构投影特征直方图如图2所示。经统计平均后作为区分相似汉字的依据。实际校正时,计算微结构特征的匹配距离。若小于预先设定的阈值,则直接返回该汉字作为识别结果。
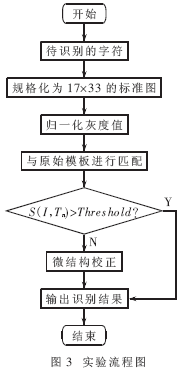
4 实验流程及结果
对识别300幅切分后的质量较好的汉字灰度图进行识别,实验流程如图3所示。实验结果表明,外围面积特征匹配法正确率达88%,网格特征匹配法86%,简单模板匹配法91%,改进算法的正确率达到了93%。如果对识别结果进一步校正,正确率将提高到95%。若再进一步增加训练集,完善模板,相信正确率还可以继续提高。
参考文献
1 丁晓青.汉字识别研究的回顾.电子学报,2002;30(9)
2 Trier I D,Jain A K,Taxt T.Feature Extraction Methods for Character Recognition-A Survey.Pattern Recognition.1996;29(4)
3 朱小燕,史一凡,马少平.手写体字符识别研究.模式识别与人工智能,2000;13(2)
4 王学文,丁晓青,刘长松.基于Gabor变换的高鲁棒汉字识别新方法.电子学报,2002;30(9)