
文献标识码: A
文章编号: 0258-7998(2011)12-0114-04
随着网络技术的发展,集成网络外设的嵌入式系统越来越多,对于目前大多数中低端的MCU来说,若运行较大型复杂网络协议栈,如VXWORKS、LINUX系统自带协议栈等,存在多种困难。由于上述协议栈均与各自操作系统绑定,需要同时移植相应操作系统(OS),另外对于一些低端MCU来说,其硬件限制也无法运行大型协议栈。本文在嵌入式系统中设计实现了一种简化的UDPIP协议栈,该协议栈运行占用资源少,数据传输效率高,便于移植,并且可以运行在无操作系统的微型嵌入式系统中。
1 设计原理及整体架构
UDPIP协议栈对数据的处理过程,即对数据的发送和接收流程,主要完成对承载数据添加、剥离协议头的操作。在兼顾UDPIP协议栈功能的基础上,为了达到高效的目的,对协议栈的数据收发流程以及所涉及的重要数据结构进行优化。
在数据发送流程,用户数据传入协议栈以及协议栈将数据递交给ETH控制器两个步骤耗时最多,尤其是大于MTU的数据。通过优化协议栈BUFFER结构以及协议栈与ETH驱动的挂接方式,改进了这两部分的效率;对于大于MTU数据的接收,需要进行重组,所涉及的定时机制以及重组数据的整合,是影响效率的关键所在,需对其进行重新设计。
根据优化协议栈时流程简化、功能不简化的原则,设计开发了协议栈的控制模块,以支持属性设置,参数配置以及ETH设备的控制等功能。协议栈的整体架构如图1所示。

2 关键技术
2.1 BUFFER管理
在数据收发过程中,内存分配、释放、拷贝是耗时最多的部分,尽可能减少内存操作,特别是减少数据在收发流程中的内存拷贝次数能大幅提高协议栈效率,合理的BUFFER池结构是实现高效协议栈的关键。为了配合设计流程的实现,便于协议栈数据BUFFER、系统BUFFER管理,提高协议栈数据传输效率,协议栈实现类LINUX系统中SLAB CACHE模式管理协议栈数据BUFFER和系统控制BUFFER。在系统初始化中分配大块内存,按照不同BUFFER SIZE建立CACHE,其拓扑结构如图2所示。
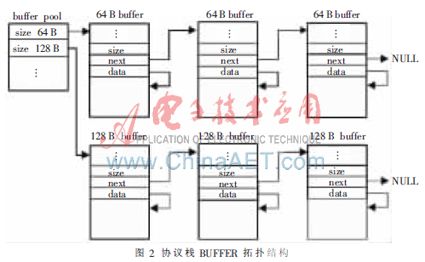
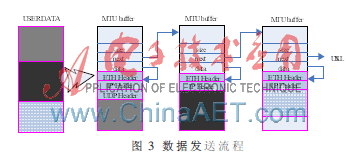
在数据发送流程中,应用程序通过BSD接口将数据传入UDPIP协议栈后,协议栈直接将其拷贝到协议栈BUFFER,若数据长度大于一个MTU,则分片后依次拷贝到多个协议栈BUFFER,相比于复杂协议栈,该协议栈在处理发送流程时,没有按照先加UDP头后分片的顺序,而是先将数据分片,之后在第一分片头添加UDP头,由此省去了一次内存拷贝。用户数据传入协议栈的示意图如图3所示。
在数据接收过程中,特有的BUFFER结构支持链表式数据重组,减少一次数据拷贝,有效地提高了数据的接收效率。从协议栈对数据的处理来讲,接收流程是发送流程的逆过程,即发送流程将用户数据传入协议栈(大于MTU要分片),添加UDP头,IP头以及ETH头,接收流程相反,首先对ETH提交上来的数据进行剥离ETH头,解析IP头(大于MTU的包完成重组),解析UDP头,最终提交给用户。
2.2 BSD接口实现
从通用性考虑,简化的UDPIP协议栈实现BSD面向UDP协议的所有接口。BSD接口基于SOCKET与PORT管理本地资源,包括存储、分配、回收等操作。为了提高SOCKET和PORT资源较多时上述操作的执行效率,采用位图方式管理可用资源,以比特位的0和1状态标识资源是否可用,采用比特操作方式,实现对资源的分配和释放。在分配资源时,采用二分法查询可用资源,即遍历比特为0状态的位置(第几个比特),也就获取了可用资源的Index。该算法保证在资源较多时,查找可用资源耗时为常量且算法复杂度较低,同时也能够实现资源的重复利用。遍历查找方式如图4所示。

在标准BSD接口中recvfrom涉及数据拷贝,且每次只能接收一个数据包,效率低且耗时。一般应用程序调用recvfrom接口的应用流程为:为了能够获取完整的数据包,特别是保证特大包(约64 KB)也能成功接收,应用程序在调用recvfrom接口时传入的BUFFER要足够大,一般设为64 KB。为了提高应用程序BUFFER的利用率,该BUFFER不是由应用程序提供,而是用一专门接受数据的缓存保存recvfrom的返回值,之后将该数据拷贝至应用程序提供的BUFFER进行处理。从上面流程可见,存在的主要问题是增加一次内存拷贝,特别是在协议栈满负荷运行时,对协议栈性能影响巨大。在recvfrom读取数据时,可以同时检查SOCKET接收缓存是否还有数据包待接收,若有将其长度返回,应用程序在获取当前数据时即可知道下一个数据包的长度,据此动态分配内存,既不浪费BUFFER空间也减少了一次拷贝。为了保持标准的recvfrom接口兼容性,考虑不通过扩展参数的情况下完成后续待接收数据长度提示信息的传递:接口recvfrom在每次拷贝一次数据到用户缓存时,在拷贝完数据后,将后续是否有数据包待接收以及数据长度信息附于其后,应用程序可以提取该信息。
上述设计方案越是在协议栈繁忙时越能体现其优越性,当每次接收数据时下一个数据均已到达SOCKET接收缓存时,可以保证每次数据接收均可以减少一次拷贝;若协议栈比较清闲,则该方案失效,但此时系统欠载,多拷贝一次对系统效率也无影响。
2.3 简单路由设计
路由查询需要确定数据包内所要填入的源IP地址,查找所要经过的协议栈网口,网口由协议栈数据接口描述。该结构对应于ETH驱动面向的物理网口或虚拟网口,使数据包在物理上或逻辑上分流和隔离,达到负荷分担,优先级控制等目的。路由查询同时需要获取数据包下一跳所要发往的节点以及该节点的MAC地址,用于封装ETH头。UDPIP协议栈支持简单多网口路由,策略如下:协议栈支持多网口挂接,网口个数取决于ETH向协议栈注册的网口个数,每个网口可以拥有多个IP地址,但每个IP地址唯一地属于一个网口。数据发送时,根据目的IP地址,依次考虑其子网掩码和网络掩码,采取网段位数最大匹配原理,选取网段最大匹配的本地IP所在的网口作为发送网口,若网段不能匹配,说明目的主机与本地主机不属于同一网络,UDPIP协议栈此时采取默认网关方式,选取任一ETH网口作为发送网口,将数据发往网关。
针对上述缺陷,优化的UDPIP协议栈在实现上述简单路由机制的基础上,简化了ARP协议,采用ARP表现静态配置的方式,将有通信需求的对端IP及MAC地址静态配置到本地,在通过简单路由机制获取下一跳IP地址后,通过查询该静态配置表,将IP地址解析为MAC地址,进而封装ETH头,将数据发送出去。整个流程如图3所示。
2.4 重组机制
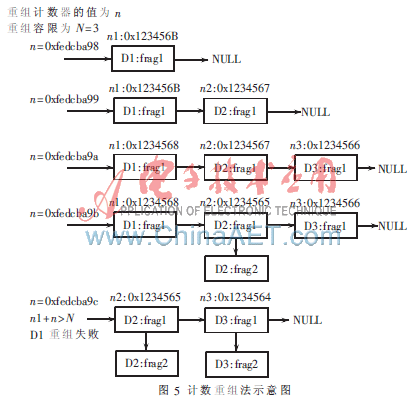
当第一次收到某报文的分片时,需要将分片暂存并启动重组机制,直到该报文的所有分片到齐,重组成功,方能继续执行后续处理。在某些情况下,分片报文在传输过程中丢弃将导致数据永远重组不全,已经收上来的分片将长期占着资源不能释放,因此必须防止此类情况发生。在标准协议栈中采用定时机制,在收到第一个分片时启动重组定时器,若在定时期间内不能完成重组则将已收到的分片释放,防止资源泄露。在简化UDPIP协议栈中,考虑到定时机制相对复杂,而且增加定时器则会引入异步事件,增加了不可控因素,因此采用计数重组法保证重组机制的正常工作。
计数重组法的工作原理:正常情况下,定时重组机制在所设时间内所有分片应该可以收齐,计数重组法则假定在某数据报的所有分片应该在所设定的IP报文个数内收齐。如定时重组机制中每收到该报文的任何一个分片重启定时器,计数重组机制中则将计数器复位,重新计数。因此,首先应该给出假定的数据报文个数,此处设为N,在收到某个数据报的第一个分片时开始计数,当收到第N个数据报文时该数据报仍没有重组完成,则认为该数据报重组失败,需要将已收上来的分片释放。
在实现上,计数重组法与无符号数的计数溢出原理相结合,极大地提高了重组效率,系统声明一无符号全局变量作为全局计数器,每收到一个IP报文,该计数器加1。当收到数据报D的第一个分片frag1时,若此时全局计数器的值为n,则初始化m对应的重组计数器基值为(0-n),之后在每次收到IP报文时,将全局计数器的当前值n1与其基值相加,获取的值与设定的最大容限个数N比较,若大于N则认为数据重组失败,否则继续等待后续的分片。该算法具体实现原理如图5所示。
2.5 与驱动挂接
协议栈若能实现正常通信,需要设备驱动与之配合,在一些稍高端的微处理器上,配有ETH外设,可实现ETH驱动与协议栈挂接,ETH驱动以BD(Buffer Descriptor)的方式管理以太数据的收发。为了提高数据传输效率,在数据接收方向BD采取替换方式以避免拷贝,接收流程如图6所示;在数据发送方向,协议栈将数据封装成ETH帧,挂接到发送BD上,启动ETH控制器完成发送,在发送完成后释放数据BUFFER。一些中低端的微控制器不支持ETH外设,若需要与UDPIP协议栈挂接,则必须实现虚拟的ETH驱动,底层物理传输可以承载于串口、SPI、GPIO等普遍存在的外设之上。虚拟驱动也需要提供类BD的管理模式,完成数据的发送、接收、缓存,由于物理承载的限制,要求通信的对端设备物理介质相同,否则需要通过硬件转换电路实现不对等的物理设备间的ETH通信。

3 性能测试
协议栈的综合性能取决于其接收方面的性能,因为数据接收流程要完成的工作相对于发送流程更为繁杂。将UDPIP协议栈与VXWORKS协议栈进行了性能对比测试,测试平台为PPC85XX处理器,工作频率为800 MHz,测试模型为发包仪器SmartBit与PPC85XX通过网线连接,ETH工作在千兆全双工模式。SmartBit做为数据源向PPC发包,PPC应用程序接收到数据并处理。由于PPC硬件平台处理能力较强,若应用程序调用recvfrom后不做任何处理,无论是Vxworks协议栈还是简化UDPIP协议栈均能轻松达到单向900 Mb/s,区别在于CPU占用率不一样。为了达到直观的效果,测试用例采取附加应用程序处理数据,使CPU工作在满负荷情况下,测试数据收发性能对比如表1所示。

UDPIP协议栈为实现更高的传输效率,同时兼容各种硬件平台,优化设计了协议栈BUFFER管理系统,SOCKET接口模块,采用简洁快速的路由策略及重组机制,充分利用以太BD的特性,采取BUFFER替换方式完成ETH数据向协议栈的提交,尽可能减少数据拷贝。改进了标准BSD SOCKET接口的实现,既能很好地支持标准应用,又能够大幅提高数据接收速率,兼容不同硬件平台、操作系统平台,甚至可以运行于无操作系统的低端MCU。在当前提倡三网融合的大环境下,电子终端种类日益增多,但IP化是电子终端的趋势,也是三网融合实现的关键,相信UDPIP协议栈能够满足绝大多数中低端电子设备对IP传输的需求。
参考文献
[1] Ma Qiang, Zhao Jianguo,Liu Bingxu. Implementation of Embedded Ethernet Based on Hardware Protocol Stack in Substation Automation System [J]. Transactions of Tianjin University, 2008,14(2).
[2] JONES M T. TCP/IP Application layer protocols for embedded systems[M].Publishing House of Electronics Industry, 2002.
[3] 徐颖,栾胜. 基于UDP的端对端通讯的原理及实现[J]. 北京航空航天大学学报,2005,31(7):823-827.
[4] Dou Xiaobo, Wu Zaijun, Hu Minqiang,et al. Implementation of UDP in communication system of substation automation[J]. Electric Power Automation Equipment, 2003(12):5.
[5] JAMALIPOUR A,MARCHESE M,CMICKSHANKH S,et al. Broadband IP networks via satellites-Part I [J].IEEE Journal on Selected Areas in Communications, 2004,22(2):213-217.
[6] 何赞园,宋华伟,吉立新. VxWorks下UDP协议栈效率的 研究与改进[J]. 单片机与嵌入式系统应用, 2006(05):28-30