
摘 要: 针对XML数据的特点,提出一种对象-关系模型及由XML Schema映射该模型的规则算法,同时根据网络数据特点,引入分片技术。
关键词: XML技术 XML Schema语言 对象-关系模型 分片
Internet数据本身具有的自描述性和动态可变性等一系列复杂特性,使其结构呈现半结构化特点,给网上数据的管理和查询带来困难。解决此问题的关键是寻找一个半结构化的数据模型。事实上,日益普及的XML数据是一种自描述的半结构化数据。从某种意义上说,XML就是一种半结构化的数据模型。它的出现推动了网络在电子商务、电子数据交换和电子图书馆等多方面的应用。但对于如何有效地存储管理和查询这类数据,目前还没有统一的方法。
针对XML数据的特点,本文提出了一种对象-关系模型。其主要思想是将XML数据中具有明显结构特征的数据建立关系数据模型,将具有继承、不确定特征的数据建立面向对象数据模型。这样,既能保证元素的直观性和完整性,又能充分利用关系数据模型的优势提高对部分数据的查询效率。同时根据网络数据分布存储的特点,引入分片技术,以进一步提高查询效率。特别是在面向对象数据模型中则采用类垂直分片技术,并对类垂直分片的概念以及类垂直分片的原则进行了具体详尽的描述。
1 对象-关系模型的建立
1.1 XML Schema
XML Schema是W3C较新推出的标准。它是用来对XML进行文档类型定义的语言,同时可用来规定XML文档的数据类型及组织方式。相对于DTD而言,XML Schema具有丰富的数据类型,而且还可通过对数据类型进行扩展和限制定义新的数据类型。XML Schema本身也采用XML格式编写,从而方便了数据的建立和处理。XML Schema克服了DTD的许多局限,有望取代DTD成为定义XML数据类型的主要手段。文档1是一个XML Schema实例。


为保证数据由XML Schema向对象-关系模型映射的完整性和有效性,需要了解XML Schema包含的信息。XML Schema主要提供下列几方面的信息。
(1)元素的内容信息。包括元素的名称和类型。元素主要包括以下几类:不包含子元素和属性的简单元素;通过元素引用方法声明的元素;包含子元素和属性的复杂元素;类型为ANY的元素等。
(2)元素的数据类型信息。包括XML Schema内建的数据类型;由限制及合并而派生的简单数据类型;由已有数据类型聚集(aggregation)、扩展(extension)派生的复杂数据类型。
(3)元素的属性信息。包括直接定义类型的属性;通过引用声明的属性;声明为ANY内容的属性等。
(4)元素的关系信息。包括嵌套关系、引用关系、顺序关系和继承关系等。
(5)在映射中要考虑的其他信息。包括元素值、属性值限制(由fixed和default属性指定);元素出现次数的限制(由minOccurs和maxOccurs属性控制);元素属性出现限制(由use属性指定,其值可以是required、optional、prohibited)以及元素组、属性组等。
针对XML Schema的上述特点,本文提出了由XML Schema映射对象-关系模型的规则算法。
1.2 映射规则
规则1:创建关系RR映射元素之间的关系。结构如下所示:

按规则1,为文档1创建了图1中的表element_relation。
需说明的是:关系RR的project_table域与复杂元素的element_type一一对应。因此可通过这种对应关系,在已知element_type的情况下找到映射其结构的关系。
规则2:为每个由聚集(aggregation)得到的不同类型的复杂元素EA创建一个关系RE,关系名存在关系RR的project_table域中。
规则3:对每个关系RE,创建主键INSTANCE_ID域,标识惟一元素实例e;创建BIB_ID域,指向e相邻的下一个元素实例en,以映射元素实例之间的顺序关系。
规则4:将元素EA的出现次数不大于一次的简单子元素(maxOccurs=1)映射为关系RE的一个域,类型为简单元素的类型。将通过元素引用方法声明的简单子元素映射为关系RE的与被引用元素类型相同的域。将类型为STRING、BOOLEAN、DECIMAL、FLOAT、DATE等在关系数据库存在的类型或可转化的类型(ID、IDREF、ANYURI、TOKEN等)的属性直接映射为关系RE的相应类型的域。将引用声明的属性映射为关系RE的与被引用属性类型相同的域。
规则5:将元素EA的出现次数不确定或大于一的简单子元素(包括引用声明的简单子元素)、类型为IDREFS、ENTITY、ENTITYS的属性映射为类CE的同一类型的变量;声明INSTANCE_ID和ELEMENT_TYPE变量,元素EA的出现次数不确定或大于一次的复杂子元素(包括引用声明的复杂子元素)的类型映射为类CE的变量,INSTANCE_ID映射为类CE的数组变量,变量名取元素名。
规则6:在关系RE中创建OBJECT_ID域,以存储类CE的指针。
按照规则2~6,对文档1中的memories元素创建表memories和类memory;为memory元素创建memory表。
规则7:由扩展(extension)得到的复杂元素Eh(设父元素为EA),按规则2、3、4映射关系模型,按规则5将类CE没有的属性映射为类CEh,并将CEh作为CE的一个子类,再按规则6创建OBJECT_ID域。
规则8:通过元素引用方法声明的复杂元素与被引用元素具有相同结构,且与被引用元素共用一个数据模型。
规则9:为每个元素(属性)组创建一个类。简单类型的元素(属性)映射为相应类型的变量,变量名取元素(属性)名;声明相应类型的变量,映射复杂类型元素的类型和元素实例的INSTANCE_ID;在包含该元素(属性)组的关系中创建GROUP域,存储相应元素(属性)组类的指针。
按照规则9,可对文档1中的memoryGroup元素组创建类memoryGroup,并在memoryType表中创建“g_point"域(见图1)。

规则10:创建名称为ANY的类,以存储ANY类型的元素和属性。在包含ANY类型元素(属性)的关系中创建ANY域,存储ANY类的指针。ANY类包括以下变量:
class any {
element_type string /*复杂元素的类型*/
instance_id integer /*该对象实例在相应
关系中的instance_id*/
element_name string /*元素名*/
instance_value string /*简单类型的元素(属性)值,均转换为字符串类型*/
}
按规则10,为文档1中的ANY元素创建类“any”(见图1)。
规则11:对于XML Schema定义各种约束及派生的简单数据类型,可通过关系数据模型的域约束来实现。
图1是按以上规则,为文档1创建的对象-关系模型。
2 分片和类垂直分片技术
分片技术分为水平分片、垂直分片和混合分片,其在关系数据库中运用的理论和实践已比较成熟,形成了相对一致的看法。类垂直分片技术则是近几年提出的新思想,有关这方面的研究不多。文献[2]对类垂直分片在提高查询效率方面的作用进行了评估和论证,提出了影响类垂直分片的制约因素,证明了类垂直分片的有效性。
2.1 类垂直分片的基本思想
类垂直分片是依据类实例变量的相关程度和经常一起访问的频率对类实例变量分组、构造类片段并分片存储,通过减少对无关实例变量的访问来降低磁盘I/O,提高查询效率。类垂直分片技术尤其适用于数据量大,且无需访问整个类实例的情况。
2.2 类垂直分片的定义

2.3 类垂直分片的基本原则和方法
由于面向对象数据模型中的子类继承、类组装继承(class composition hierarchy)等复杂关系,使得对类进行垂直分片变得复杂。下面给出类垂直分片的基本原则和方法。
(1)将相关的及可能经常一起访问的实例变量归入同一类片段。
(2)类与类之间存在高输出(fan-out)的情况,对沿类组装继承路径上的所有类进行垂直分片。
(3)要根据源类的大小选择垂直分片策略。对于较小的源类不易做过多的分片,因为过多分片不仅不会提高反而会降低查询效率。但较大的源类对分片多少不是非常敏感。
(4)选择垂直分片策略前,首先要分析投影率(projection ratio)。如投影率高则不易进行分片。
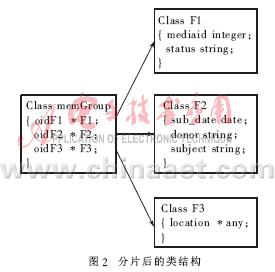
(5)类垂直分片的方法是:将类C的每一个类片段描述为一个类,而逻辑类C则描述为一个复合类,由所有类片段的指针构成。例如,将图1中的class memoryGroup垂直分片如下:
class memoryGroup:类片段1(mediaid,status),类片段2(sub_date,donor,subject),类片段3(location)。分片后的类结构如图2所示。
3 讨 论
采用关系数据模型存储XML数据,可利用关系数据库现有的存储管理、并发控制、恢复、版本机制等技术有效地管理XML数据。但由于关系模型不支持复杂类型的属性,一个简单的查询路径有时要通过多重链接实现,从而影响了查询的效率。半结构化数据的不确定性也是这种模型难以解决的问题。面向对象数据模型虽接近半结构化数据模型,并能更好地处理嵌套的集合和顺序,但在数据加载时对未知的数据类型需要建立新的类对应,这样就影响了加载效率。当元素类型改变时,数据模式的变动代价也很高。而且对XML数据中明显具有结构化特性的数据采用面向对象模型存储,其查询效率远比不上关系数据模型。目前采用的对象—关系模型大多是通过对关系模型的扩展来实现的。如文献[3]就是通过对关系中增加嵌套属性组的方法来实现多值属性(元素)的存储,它综合了上述二种方法的优点,但仍不能充分体现XML数据的灵活性和不确定性。本文提出的对象—关系模型是将元素的关系信息和元素的实例信息分别存储,这可有效降低数据的维护代价。同时,将部分元素和属性采用关系模型存储,将具有继承、不确定特征的数据建立面向对象数据模型,既能保证元素的直观性和完整性,又可提高部分数据的查询效率。此模型还能对ANY类型的元素和属性创建特定的类进行维护。这些都体现了XML数据的特点。分片技术的运用也对提高查询效率有很大的作用。
本文讨论了XML数据的物理存储模型。对建立在该模型上的数据库查询及在XML Schema和对象-关系物理存储模型之间引入适当逻辑数据模型将是下一步研究的课题。
参考文献
1 盖江南.Java,XML和Web服务宝典.北京:电子工业出版社,2002
2 Fan W,Libkin L.On XML Integrity constraints in the presence of DTDs.JACM,2002;49(3)
3 Florescu D,Kossmann D.Storing and querying XML data using an RDBMS.IEEE Data Engineering Bulletin,1999;22(3)
4 Aboulnaga A,Naughton J,Zhang C.Generating synthetic complex-structured XML data.In Proceedings of the WebDB′ 01Workshop,2001
5 Khalifa S A,Jagadish H V,Koudas N et al.Structural joins:A primitive for efficient XML query pattern matching. In:Proceedings of the 2002 International Conference on Data Engineering,2002