
摘 要: 研究了一种基于多粒度锁的并发控制算法,包括其多粒度锁锁、锁表数据结构及锁操作的算法步骤。算法可以降低冲突发生的概率和事务的夭折数,减少事务重启,有利于满足事务截止期的要求,提高事务的并发度。在验证算法有效性时,通过测试类对内存数据库记录的插入速度、索引查找的速度、记录的删除速度三方面的性能进行了测试,结果表明,事务并发控制优化算法对内存数据库性能的提升是有效可行的。
关键词: 内存数据库;实时事务;算法;并发控制;粒度
实时事务处理的算法主要有两个方面,一方面是实事事务调度算法,主要是事务优先级的确定;另一方面是实时事务的事务并发控制算法,包括悲观事务并发控制算法和乐观事务并发控制算法两种[1]。近年来,在事务的并发控制方面已取得了大量理论研究成果。迄今为止,许多基于锁、乐观、时间戳的实时数据库并发控制方法已提出,如优先级继承PI(Priority Inheriting)、高优先级夭折HPA(High Priority Abort)、优先级顶PC(Priority Ceiling)等,但很少见有关实时内存数据库并发控制实现技术的相关论述[2]。实时事务的并发控制实现涉及到实时数据库的底层技术,而一般的研究和讨论只是基于一定的实验模型进行理论研究和分析。而且,对于不同的实现环境和所选择的实现策略,实时事务所采用的并发控制技术也不尽相同。本文在研究已有的事务并发控制算法的基础上,对悲观事务并发控制算法2PL进行了改进。
在对算法性能测试时,根据给出的实时内存数据库的引擎结构,开发出一个实时内存数据库,以测试类对内存数据库三个方面的性能进行了测试。测试分为两次,分别为事务并发控制算法优化前和事务并发控制算法优化后。
1 实时事务的并发控制算法
内存数据库的一个重要设计问题是并发控制,它由于既要满足事务的时间限制还要维护数据库的一致性而变得复杂[3]。传统数据库系统的并发控制协议不适合内存数据库系统,实时事务是紧急的并且事务调度必须满足截止期[4]。
定义1:一个调度S定义在一个事务集合T={T1,T2,...,Tn}的基础上,它是多个事务执行的操作系列。
定义2:一个调度S中,各个事务的操作执行时不叠加(即一个接着一个发生),则这个调度是串行的。
定义3:一个调度S是可串行的,当且仅当S冲突等价于一个串行调度。这种可串行化通常称为冲突等价可串行化。
一个并发控制器(或称调度器)的基本功能是产生一个要执行事务的可串行化调度。多数内存数据库系统的并发控制协议均基于串行化理论[5]。并发控制协议用于控制数据的调度,主要目标是维持数据的一致性并提供最大化的并发度[1]。在有些情况下,一致性要求可适当放宽。内存数据库是驻留在内存中的共享数据,在不同线程中同时运行的事务之间可能由于访问内存数据库中的同一个数据对象而发生冲突,并发控制协议就是用来解决事务之间冲突的策略[6]。常见的冲突模式有“读-写”冲突和“写-写”冲突[7]。
“读-写”冲突:对同一个数据对象,一个事务正在执行“读”操作,同时另一个事务执行“写”操作而发生冲突;
“写-写”冲突:对同一个数据对象,一个事务正在执行“写”操作,同时另一个事务也执行“写”操作而发生冲突。
内存数据库中的并发控制协议解决冲突的办法主要有两种策略:
(1)等待:终止其中一个事务引起冲突的操作,使其停留在等待状态,直到另一个事务的操作完成为止。在内存数据库事务并发控制的研究中,等待策略有以下三种派生方法:①不等待(no wait):等待的事务立即夭折,而不是等到另一个事务操作完为止。②损伤等待(wound wait):根据每个事务的达到时间,如果要求得到数据者到达得比较早,则夭折正在使用数据的事务;否则夭折要求得到数据的事务。③等待死亡(wait die):根据每个事务的到达时间,如果要求得到数据者到达得比较早,则该事务可以继续等待,否则夭折这个事务。
(2)回滚:撤消事务引起冲突的操作,事务重启,回到开始时的状态[1]。
根据解决“读写”操作冲突的不同策略,并发控制算法分为悲观并发控制协议PCC(Pessimistic Concurrency Control)和乐观并发控制协议OCC(Optimistic Concurrency Control)两大类[6]。分类如图1所示。

悲观并发控制算法中最广泛使用的是基于锁(Lock)协议的算法,它为数据访问提供数据锁,分为读锁和写锁,读锁又称共享锁(Shared Lock),被加读锁的数据对象只能读不能写;写锁又称排它锁(Exclusive lock),被加锁的数据对象只能被加锁事务读写,其他事务不能访问[7]。事务要获得对数据的访问,首先要申请得到锁,操作完成后释放锁。一般操作系列为:(1)申请锁(Lock request);(2)授予锁(Lock granted);(3)数据库操作(Database operation);(4)结束操作(End of database operation);(5)释放锁(Release locks)。
两阶段锁2PL(two phase lock)是悲观并发控制协议算法的重要内容,为解决优先级倒置,派生出了高优先级法2PL-HP(也叫优先级夭折)、优先级继承、有条件优先级继承、数据优先级法PCP及其他衍生协议。
乐观并发控制协议认为任何两个并发事务请求同一个数据对象的概率很低,事务对数据库的所有操作在请求时即可进行。乐观并发控制协议的事务处理过程分为:读、验证、提交,验证分为前向验证和后向验证,若在验证阶段发现冲突,则进行事务回滚。如果事务频繁的重启对于内存数据库系统来说会是一个负担并且不利于事务在截止期前完成,因此乐观并发控制协议算法大多是围绕如何减少事务重启而进行改进,派生出了广播算法OCC-BC、WAIT-50、OCC-TI、OCC-DA、多版本协议MCC等。
悲观并发控制协议算法具有节约系统资源的特点,在处理时间限制比较严格的硬实时事务时表现优于乐观并发控制协议,而乐观并发控制协议有利于提高系统的并发度[8]。研究表明,2PL-HP更适合于分布式内存数据库系统。根据流程工业大型内存数据库系统的特点,借鉴分布式两阶段锁协议2PL的思想,本文提出并设计了多粒度锁的并发控制算法,其特点是减少冲突事务之间的等待时间。
2 两阶段锁2PL
数据锁分为读锁(也称共享锁)和写锁(也称独占锁):(1)共享锁Shared lock:只允许读,简称“S锁”;(2)独占锁Exclusive lock:允许读和修改锁住的数据对象,简称“X锁”。一般使用锁的方式是用完即释放,如以下代码所示:
LOCK S(A); //对数据对象A加共享锁
read(A); //读数据对象A
UNLOCK(A);//释放锁
LOCK S(B); //对数据对象B加共享锁
read(B); //读数据对象B
UNLOCK(B); //释放锁
display(A+B); //显示结果
这种使用锁的方式可能会导致不可串行化,而可串行化(serializability)是并发控制最普遍的正确性准则,各个事务对数据对象的操作不交叉存取(即每个事务对数据对象的操作是连续的)[9]。因为在这种方式中,当事务T1释放锁时,事务T2获得了数据对象A的独占锁LOCK X(A)而执行write(A)的操作,就会导致事务T1的执行结果不正确。采用两阶段锁来解决此问题,所谓两阶段指的是封锁阶段和解锁阶段。封锁阶段也称为生长阶段(Growing phase),事务获得锁并存取数据;解锁阶段也叫枯萎阶段(Shrinking phase),事务的锁不断减少。
两阶段锁算法的规则是:(1)如果事务T想读(修改)一个对象,它首先要获得一个共享(独占)锁;(2)对事务已经持有的封锁,不得重复申请;(3)一个事务必须注意到其他事务所做的封锁;(4)每个事务分做两段:生长期和枯萎期。生长期申请封锁,枯萎期解除封锁,在枯萎期不得申请新封锁;(5)调度器在数据管理器完成对数据对象椭操作后才能释放锁;(6)事务结束时,解除所有封锁。
两阶段锁算法规则保证了事务执行的可串行化,锁管理器LM (Lock Manager)在存取结束时即刻释放锁,提高了事务的并发度。但它存在的问题是可能导致级联退出,所以需要使用严格2PL(strict two-phase locking,简称S2PL), S2PL在数据存取完成的最后阶段释放所有锁。
3 基于多粒度锁的并发控制
内存数据库中,两阶段锁封锁对象的大小称为封锁的粒度,一般情况下,加锁的粒度越大,加锁的次数就越少,系统资源的开销小,事务之间冲突发生的概率就越高,系统的并发度越低;多粒度锁封锁就是在一个系统中同时支持多种封锁粒度供不同的事务进行选择。采取多粒度锁封锁策略,可以降低冲突发生的概率和事务的夭折数,减少事务重启,有利于满足事务截止期的要求,提高事务的并发度。
3.1 多粒度锁并发控制锁
参考关系数据库的概念,内存数据库中锁的粒度可定义为:数据库DataBase (如果多于一个库,数据库也可以作为粒度的元素)、表Table、页Page、记录Record、元组Tuple。从前到后是一种顺序包含的关系,展开以后其层次结构形成了一棵树。多粒度锁封锁允许对树上的每一个数据项进行封锁。由于节点的这种包含关系,除S锁和X锁外,多粒度锁锁时需要引入以下的意向锁:
(1)IS(Intent Share Lock):意向共享锁。如果对一个数据对象加IS锁,表示它的子结点拟加S锁。
(2)IX(Intent Exclusive Lock):意向排它锁。如果对一个数据对象加IX锁,表示它的子结点拟加X锁。
(3)SIX(Share Intent Exclusive Lock):共享意向排它锁。如果对一个数据对象加SIX锁,表示对它加S锁,再加IX锁,即SIX=S+IX。例如,对某个表加SIX锁,则表示该事务要读整个表(对该表加S锁),同时会更新个别元组(对该表加IX锁)。
多粒度锁锁协议准则:
(1)从层次结构的根节点开始封锁;
(2)子节点要获得S或IS锁,它的父节点必须持有IS或IX锁;
(3)子节点要获得X或IX或SIX锁,它的父节点必须持有IX或SIX锁;
(4)必须从由底向上的顺序释放锁。
3.2 粒度并发控制算法步骤
本文提出的多粒度锁的并发控制协议中,采用S2PL-HP算法解决冲突。如果低优先级事务试图申请高优先级事务持有的锁,则阻塞优先级低的事务;如果优先级高的事务到达时申请低优先级事务持有的锁,则将低优先级事务回滚。
两阶段锁算法需要构造锁管理器LM,锁管理器管理的锁存放在散列表(Hash Table)一类的数据结构中,数据结构中的元素可定义如下:
typedef lock_type{
DATAID data_id: //被锁定的数据对象ID
vector trans_id; //持有锁的事务ID向量
int lt://锁类型:S、X、1S、IX,SIX
int lg;//锁粒度:db,table,page,record,Tuple
}lock_item
定义4:RTDB={DT1,DT2,…,DTn},其中, DTi为数据库中第i个的数据表,DTi={DR1,DR2,…,DRn}:DRj为数据表中第j条记录,DRj={DF1,DF2,…,DFn};DFk为记录中的第k个元组。
定义5:数据的全局标识为GID=f(DB,DTi,DRj,DFk);conflict(Ti,Tj)为事务Ti和Tj的冲突;lock(Ti,Di)表示事务Ti对数据对象Di加锁。
LM:Lock Manager,即锁表管理器;DM:Data Manager,即数据管理器。当事务Ti到达时,多粒度锁并发控制算法步骤为:
(1)进行事务预分析,根据一定的算法规则计算Ti所操作的数据对象的数据标识;并填写lock_item中的其他项;将锁粒度lg初始化设置为table。
(2)查看锁表管理器,找到事务Tj的数据对象ID:
①Ti和Tj不冲突,则锁表管理器将Ti的信息加入锁表中,lock(Ti,Di),转到第(3)步;
②如果Ti和Tj发生冲突,若它们的锁类型相容,则锁表管理器将Ti的trans_id加入向量中,转到第(3)步;
③如果锁粒度是元组,即最小加锁粒度,则跳到第(5)步,否则调整Ti和Tj的加锁粒度,并返回第(2)步;
(3)处理事务,调用数据管理器进行数据读写操作;
(4)数据管理器处理完毕,锁表管理器更新对应锁表中的信息,跳到第(6)步;
(5)如果有冲突发生,调用S2PL—HP算法规则解决冲突;
(6)结束。
4 算法测试
4.1 内存数据库引擎结构设计
内存数据库 Engine是内存数据库的核心,它对实时/历史数据进行管理,它的本质是一个实时事务处理器。
关系型数据库采用二维关系表来进行数据的存储,基于磁盘的存储结构,数据存取过程中要进行频繁的磁盘I/O操作。由于磁盘I/O操作时间不确定性,要引入内存数据库中是不现实的。内存数据库将实时数据常驻内存,访问实时数据时无需进行I/O操作,保证了运行速度,有利于满足实时事务截止期的要求。
4.2 事务并发控制优化算法测试结果
测试系统环境为:Win7+JDK+NetBeans6.7。
事务并发控制算法优化前测试结果如图2所示。

事务并发控制算法优化后测试结果如图3所示。
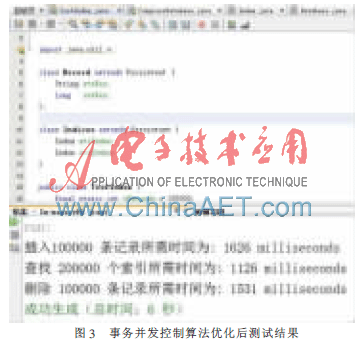
与传统数据库不同,内存数据库系统事务的并发擦控制除需保证共享数据的一致性外,还要考虑事务的定时限制。因此,其并发控制机制比传统数据库要复杂。本文给出了一个基于多粒度锁的并发控制机制,通过验证,该方法成功且有效地解决了内存数据库的事务并发问题。从内存数据库的测试结果可知,算法优化后系统的各项性能都有所提升,证明了算法优化的可行性和必要性。
参考文献
[1] 纳永良.大型实时数据库关键技术及应用研究[D].北京:北京化工大学,2010.
[2] 祁鑫,王文海.内存数据库系统并发控制机制综述[J].计算机技术,2006.33(1):47-50.
[3] 陈小艳.嵌入式主动内存数据库ARTs.EDB的并发控制[D].武汉:华中科技人学,2009.
[4] 桑楠.嵌入式应用原理及应用开发技术[M].北京:北京航空航天大学出版社,2003.
[5] 夏家莉.嵌入式数据库系统中无冲突并发控制协议CCCP[J].计算机研究与发展,2004,41(11):1936-1941.
[6] 廖国琼,刘云生,等.嵌入式内存数据库事务的并发控制[J].计算机工程,2005(9).
[7] 赵文洁.基于OPC技术的实时数据库的研究与设计[D].太原:太原理工大学,2007.
[8] 廖国琼,刘云生,等.嵌入式实时数据库事务的并发控制[J].计算机工程,2005,32(5):12-18.
[9] LAM K W, LAM K Y, HUNG S L.Optimistic concurrency controlprotocol for real-time databases[J]. SYSTEMS SOFTWARE, 2007,11:34-39.