
本文通过分析现今主流的数据库存储模型,对基于MML标准的电子病历构建存储模型。针对对象一关系型和关系型2种存储模型比较分析,给出了基于MML标准的电子病历系统的数据库存储模型设计方案。
1 引 言
MML(Medical Markup Language)作为一套不同医疗信息系统之间的数据交换规格于1995年开发,是一套比较完整的使用XML结构电子病历交换标准,目前最新版本是3.0。采用MML标准可以将基于异构电子病历的医疗信息系统很好的结合起来,实现数据的共享。
目前大多数采用电子病历医疗信息系统的医院都使用关系型数据库,主要考虑到关系型数据库有强大易用的查询分析工具和易与医院遗留系统整合的能力。但是由于基于MML的电子病历映射到关系型数据库时,原有的层次结构信息将丢失,此外关系型数据库对基于MML的电子病历内的嵌套和递归结构支持也较弱。
2数据库类型选择
针对医疗信息系统的研究发现,两类数据库系统操作是必须的:操作类型(例如,统计、分析);研究类型(例如,查询)。在分析应当选取何种类型的数据库存储模型作为研究对象时,首要前提是要支持这两类操作。现有3种数据库系统可以作为MML电子病历的存储模型,分别是XML原生数据库、关系型数据库和对象一关系型数据库。
XML原生数据库是专门为存储XML数据设计的,支持DOM模型和断言查询。但现在缺乏商业级的产品,同时开发人员需要花费相当的时间来熟悉和适应,在未来可能作为XML存储的重要应用但这里不作为分析研究的重点。
对于关系型数据库系统,当MML电子病历映射到数据库时,文档内在的层次关系将丢失。这可能不影响操作类型的操作,可是对审计跟踪将有一定影响。作为现在主流的数据库系统,关系型数据库系统有丰富强大的查询和分析工具,各种优化技术又使得性能高效,因此将其作为研究MML电子病历系统存储模型的对象。
相比之下对象一关系数据库作为较新的数据库系统,其在关系型数据库和面向对象数据库之间搭起了一座桥梁。对象一关系数据库基于关系模型,存储结构和数据访问都是基于标准的面向对象版本的SQL。因为引进了OO概念,对象一关系数据库也附加了、继承和多态等OO特性。对象能存储在表内并包含方法。由于扩展了面向对象的特性,支持复杂数据类型,对象一关系数据库比传统关系型数据库更适合作为MML电子病历的存储模型。
MML电子病历包括各种检验表、图形等对象需要专门的方法来查询,在这种情形下对象一关系型数据库就尤显优势。
3存储模型设计和实现
采用传统的ANSI三层数据库模型(外层、逻辑或内层、物理层)来设计MML电子病历存储模型。概念设计阶段的目标是构造出独立于具体数据库管理系统的数据库概念模式。在逻辑层设计的过程中,选用特定的数据模型将概念模式映射到逻辑模式。最后一步按照物理存储结构开发数据库的规范,底层算法用来设计执行数据榆索和数据管理。
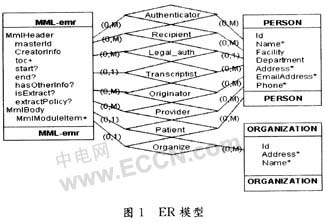
3.1 基于MML电子病历的ER模型
在概念设计阶段采用广为使用的实体一关系(ER)模型。根据MML电子病历处理过程,设计了包括3个实体和8种关系的模型,3个实体分别为:Person,MML-emr和Organization。
针对设计出的ER模型(见图1),町以选用对象导向的方法或传统的纯关系数据模型方法。下而将详细讨论对比两种方法,找出各自的优缺点。
3.2对象一关系型存储模型设计
在将ER模型映射到对象一关系模型时,最直接的办法是采用对象描述实体。表1为Person对象及其对应属性。
需要注意的是有4个属性是对象数组用以表示PER-AON实体的多值属性。MML_emr和Organization对象和Person对象类似。ER图中的关系也可映射为对象,表2为3个实体之间的关系。

ER模型中的多值属性可以用VARRAYS或者嵌套表表示,嵌套表更适合对一组需求的查询,如果是要通过单个操作完成的组需求的话VARRAYS效率更好些。
在对象一关系模型中,N∶M关系可以通过在嵌套表上添加REF(类似参考类型指针)实现。以MML电子病历提供者provider和MML-emr之间的关系为例。每一个oo_MML_emr包含有oo_provider的嵌套表,每个oo_provider属性指向一个person对象。在对象-关系模型中只需两张表MML_emr和person就可以表示出这个N∶M的关系。而在关系型模型中需要MML_emr,per-son和MML_emr_person三张表。
l:M关系的实现在2种模型相似,在对象一关系模型中使用REF类型,而在关系模型中使用外键。
3.3 关系型存储模型设计
采用标准算法将ER模型映射到关系型模型。首先为ER模型中的每个实体创建1张表;再对ER模型中的每个多值属性创建表;1∶M类型的关系通过添加外键来实现;N∶M类型的关系使用单独的表。由于基于MML的电子病历包括大量的多值属性和N∶M类型关系,所以相对于对象一关系模型会产生大量的表。
鉴于关系型数据库在信息系统中的设计问题已经有了详尽深入的研究,这里就不详细展开了。
4 比较
在前述段落提到的分析结果我们认为基于MML电子病历的数据库存储模型的最佳选择是对象一关系类型。针对对象一关系型数据库有2种设计方法,一种是把包括数据成员和方法的对象存储到表中;另一种是在只使用传统关系型数据库设计方法不能满足需求时才采用面向对象的方法来操作对象。
就分别采用这2种方法设计和实现对象一关系模型过程中存在的问题和对执行结果的分析来讨论二者的优劣。
4.1 实现问题
对象关系模型创建的表的数量较关系型模型少许多,且使用基于对象方法的简单表达式使得查询也趋于简单化。但是对象方法要认真设计实现,否则某些查询因为没有设计合适的对象方法将无法完成。
设计实现对象一关系数据库时,每个对象都要考虑采用何种类型,是否使用用户自定义类型(UDT)。对每个对象可能有的查询/操作认真分析,据此设计用户自定义函数(UDF)。例如,通过名字Bob Smith查询病人电话列表,下面列出对象一关系的SQL语句:SELECT o.phoneFROM oo.person o WHERE o.hasName('Bob','Smith');这里必须为oo.person对象设计该hasName自定义方法,不然将无法进行此查询。在对象一关系模型中需要设计大量自定义方法。在传统关系型模型,该查询可以通过下列语句实现:SELECT o.phone FROM person p,person-name n person-phom o WHERE n.name='Bob Smith'AND n.id=p.id AND o.id=p.id;需要连接3个表。
对象一关系模型中表的查询/操作比传统的关系型模型简单直观,但是需要编程实现大量的自定义函数。此外由于N∶M关系是通过在对象中添加嵌套表或数组实现的,设计人员必须认真考虑应该将其添加到该关系相关的哪个对象上。
4.2 时延分析
对两个均包含100份MML电子病历的对象一关系数据库和传统关系型数据库进行比较。选取下面4组典型的数据库操作分别在2个数据库上运行,以比较性能:
(1)使用简单搜索规则对单个病人进行数据检索,例如通过名字检索病人数据;
(2)多病人数据检索查询;
(3)检索MML emr tab表数据(不是病人数据);
(4)增、删和更新数据。
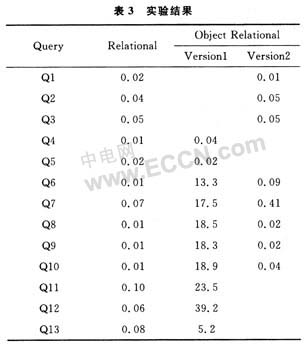
使用Oracle9i实现2个数据库,共进行13组操作,每组运行5次取平均时间。实验结果表3所示,对象一关系模型包含2列,2个版本的差别在于版本二只在必须的情况下使用用户自定义函数(UDF)。Q1到Q3属于分组一,在两种数据库中都没有使用UDF。Q4到Q6属于分组二,分别对oo_person_tab,oo_organization和oo_MML表进行多病人数据检索查询。以Q4为例,该查询需要扫描整个oo_person_tab表以便执行hasName()。Q4的时间复杂度为O(n)。使用类似hasName(),hasID()等UDF的查询依赖于表的行数。关系型数据库采用优化技术,时间复杂度为O(log(n)),对对象一关系数据库的优化由于UDF非常复杂,难于优化。Q7,Q8和Q9属于分组三,在对象一关系数据库的2个实现中也同样发现,版本二由于只在必须时使用UDF,执行时延得以大幅缩短。分组四同样是使用UDF的缘故,执行效率传统关系型数据明显高于对象一关系型。
5 结 语
设计层次上,对象一关系模型因为表的数量比较少而显得比较简洁,但设计的过程不如关系型模型直观,设计人员需要认真考虑对象间的关系应当如何表示。实现层次上,对象一关系模型需要提供支持多值属性和关系的搜索方法的具体实现,可以使用嵌套表或数组表示;关系型模型则采用独立表,不需要设计人员编写代码。
查询和执行方面,在对象一关系模型上的查询表达式简洁直观,但需要事先编程实现对象方法。传统关系型模型的数据库操作效率要高过对象一关系模型。综上,因为基于MML的电子病历系统的原型非常复杂,使用对象一关系型存储模型可以简化数据库的设计和实现,缩短开发周期;同时可以结合传统关系型的优点,只在必须用用户自定义方法的时候才使用UDF,一方面可以提高执行效率;另一方面可以尽量避免因为没有提供必要的UDF而不能执行电子病历灵活多样的数据库查询操作