
摘 要: 在分析SM3算法的基础上详细介绍了目前Hash函数的4种硬件实现策略,同时给出了迭代方式和基于充分利用时钟周期的循环展开方式下的FPGA实现。该循环展开方式有效地减少了一半的工作时钟数和11%的运算时间,吞吐量提高了11%,且占用的硬件资源较少。
关键词: SM3;迭代方式;循环展开方式;FPGA;VHDL
Hash函数是密码学中最基本的模块之一,在密码学中扮演着极其重要的角色,广泛应用于数字签名、消息鉴别和伪随机数生成器等领域,是近几年密码学研究的热点领域[1]。
Hash函数是将任意长度的信息通过算法变成固定长度的输出,且这个变换过程是不可逆的。Hash函数的不可逆特性使得攻击者不能通过Hash值推出任何部分的原始信息。因为对于原始信息中的任意一个比特数据发生改变,其Hash值都将发生明显变化。此外,Hash函数还具有碰撞约束性,即不能找到一个输入使其输出结果等于一个已知的输出结果,或者不能同时找到两个不同的输入使其输出结果完全一致。正是这些特性,使得Hash值可以用来验证信息是否被修改。
1 SM3算法简介
为了满足电子认证服务系统等应用需求,国家密码管理局于2010年12月发布了SM3密码Hash算法。该算法适用于商用密码应用中的数字签名和验证、消息认证码的生成与验证以及随机数的生成,可满足多种密码应用的安全需求。SM3算法能够对任何小于264 bit的数据进行计算,输出长度为256 bit的Hash值。
SM3算法包括预处理、消息扩展和计算Hash值三部分。预处理部分由消息填充和消息分组两部分组成。首先将接收到的消息末尾填充一个“1”,再添加k个“0”,使得填充后的数据成为满足Length=448 mod 512 bit的数据长度,再在末尾附上64 bit消息长度的二进制表示数,然后将消息分成512 bit的子块,最后将每个512 bit的消息子块扩展成132个字W0,W1,…,W67,W0′,W1′,…,W63′用于Hash值的计算。SM3算法计算流程图如图1所示。
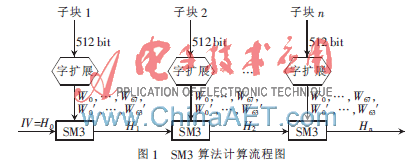
SM3算法的Hash运算主要是在压缩函数部分,压缩函数共包含64轮,每轮包括12步运算,64轮循环计算结束后,再将计算结果与输入到本轮计算的初始数据进行异或运算,即上一次Hash运算的Hash值输出Hi与输入到本轮计算的初始数据异或得到本次Hash值输出Hi+1。Hn即为最终的Hash值,H0为设计者提供的初始值IV。
2 Hash算法的硬件实现策略
在通过FPGA编程实现Hash算法过程中,提高吞吐量以及减少硬件资源占用是衡量硬件实现算法的重要指标,高效率、低功耗以及面积优化设计都是FPGA设计中最受关注的方面。目前为止,Hash算法的FPGA实现策略大致有以下4种方式[1-2],如图2所示。

(1)迭代方式:该方式将单步运算的结果重新反馈到输入端,在节约硬件资源的同时造成了较大的时延,虽然效率较低,但比较实用。
(2)循环展开方式:该方式根据算法的具体特性,将多步运算合并成单步运算,以加大并行运算规模的方式来提高单步运算的效率。
(3)流水线方式:该方式将所有单步运算全部在时钟的控制下予以实现,每个时钟均有输出。全流水线时的吞吐量达到最高,但是硬件资源消耗相当大。由于Hash函数的运算特点,该方式很少在实际中使用。
(4)混合方式:该方式实现的算法能在面积和速度上取得平衡。
3 SM3算法的FPGA实现
由于SM3算法消息扩展部分的软硬件实现的效率相差不大,因此本文着重讨论该算法的计算部分在FPGA上的两种实现方式。
3.1 迭代方式
由于SM3算法的每轮计算过程大致相同,因此可以采用迭代方式实现。实现过程中,将存放常数Tj和IV的常量矩阵利用ROM结构实现。分析SM3算法的消息扩展和压缩函数的计算过程与特点可以看出,预先通过组合逻辑计算全部W0,W1,…,W67,W0′,W1′,…,W63′的值需要消耗大量的硬件资源。而在每轮的压缩函数计算过程中,只需使用相应的一组Wj和Wj′,因此便无需预先将W0,W1,…,W67,W0′,W1′,…,W63′值全部计算出来,可以利用时钟的控制,在每次运算压缩函数之前,预先计算将要被使用的一组Wj和Wj′,显然这将使获得每轮压缩函数运算结果消耗2个时钟周期。加上初始值的输入、明文输入以及Hash结果输出共消耗的3个时钟周期,采用迭代方式进行一次SM3算法需要消耗1+1+1+64×2=131个时钟周期。
3.2 循环展开方式
仔细分析SM3算法的运算过程及迭代方式实现SM3算法的设计过程可知,时间主要耗费在消息扩展和压缩函数的计算上[3]。在SM3算法的迭代方式实现中,每轮压缩函数的运算和消息扩展运算中均需消耗一个时钟周期,尤其是在进行消息扩展过程中,每组Wj和Wj′计算量都比较小,利用一个时钟周期去进行运算实在过于浪费。如果在一个时钟周期里进行两组Wj和Wj′的计算,同时把一个时钟中本来只进行一轮压缩函数的运算也增加到两轮,这样不仅能更充分地利用一个时钟周期提高计算速度,而且整个SM3算法核心运算过程的时钟消耗也将缩短到64个时钟周期。
3.3 FPGA实现结果
本文采用Altera公司Stratix II系列的EP2S90F1508C3芯片,以Quartus II 8.1为开发环境[4],采用硬件描述语言VHDL进行SM3算法的FPGA实现。SM3算法实现的整体结构可分为库函数模块和主程序模块两大模块[1,5]。在SM3算法库函数模块中定义了6个左循环移位函数ROL7、ROL9、ROL12、ROL15、ROL19、ROLk和4个函数FF、GG、P0、P1,均用组合逻辑资源实现,常数Tj和IV的常量矩阵利用ROM结构实现。主程序中定义了实体端口(如图3所示),编译生成的模块图如图4所示。用状态机对运算过程进行控制,SM3算法的主程序中包含了s00、s01、s02、s03、s04和s05 6个状态。
以2010年12月国家密码管理局发布SM3算法所附录的运算示例中提供的数据为标准,将实验仿真所得到的计算数据与该标准进行对照,对于一个512 bit分组和两个512 bit分组,采用迭代方式实现和采用循环展开方式实现均计算出了正确的Hash值“66c7f0f4 62eeedd9 d1f2d46b dc10e4e2 4167c487 5cf2f7a2 297da02b 8f4ba8e0”和“debe9ff9 2275b8a1 38604889 c18e5a4d 6fdb70e5 387e5765 293dcba3 9c0c5732”。实验仿真结果分别如图5~图8所示。

表1比较了两种实现方式下的硬件资源占用、工作主频、所需时钟数、计算时间及吞吐量。由表1可得,循环展开方式的吞吐量是迭代方式的1.11倍,即工作效率提高了11%,循环展开方式的计算时间为迭代方式的0.9倍,即时间消耗减少了11%。

本文成功将SM3算法进行了FPGA实现,并将基于充分利用时钟周期的循环展开方式与迭代方式实现的SM3算法相比较,虽然硬件资源占用有所增加,但其时间消耗减少了11%,吞吐量提高了11%。由此可见,对于SM3算法的实现,采用循环展开方式比完全的迭代方式效率更高,时间消耗更少,而占用资源的增加与取得的收效相比并不算多,这对追求高效率、低资源消耗的移动设备至关重要。
参考文献
[1] 高献伟,路而红.密码算法FPGA实现技术[M].北京:西苑出版社,2010.
[2] RODRIGUEZ-HENRIQUEZ R. SAQIB N A, Díaz Pérez A, et al . Cryptographic Algorithms on reconfigurable hardware[M]. Springer, 2006:189-220.
[3] 曾旭,高献伟,路而红,等.HASH算法MD5的高速实现[J].成都信息工程学报,2009,24(2):129-132.
[4] 李洪伟,袁斯华.基于Quartus II的FPGA/CPLD设计[M].北京:电子工业出版社,2006.
[5] 刘欲晓,方强.EDA技术与VHDL电路开发应用实践[M].北京:电子工业出版社,2009.