
文献标识码: A
文章编号: 0258-7998(2012)05-0019-04
原语是从物理层到非接入层各层间的通信数据,这些数据包含带有大量标识信息的头。在TD-LTE无线综合测试仪表数据传输过程中,从最上端非接入层开始向下逐层将数据加头并加入本层的有效数据,到物理层后向上反馈并逐层解析头提取本层所需数据。这些数据的正确性是确保整个通信系统正常运作的关键所在,因此,在系统设计与调试过程中对这些数据的实时跟踪检测十分必要。
本文介绍了在TD-LTE中基于三星ARM1176JZF芯片S3C6410的DMA技术的具体应用实现(即原语跟踪技术),以及在具体环境中不同技术方案的对比分析。最终的设计方案充分利用了DMA在基带芯片中的可用性与占用CPU资源小的优势[1],实现了高效实时可靠的原语跟踪。
1 S3C6410中DMA控制器特性
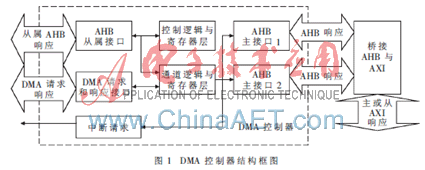
S3C6410包含4个DMA控制器,每个DMA控制器由8个传输通道组成。DMA控制器的每个通道能在主AXI(Advanced Extensible Interface)总线的设备和外部AXI总线之间通过AHB(Advanced High performance Bus)到AXI进行单向数据传输。DMA控制器结构框图如图1所示,每个控制器提供16个外设DMA请求,并且DMA控制器支持外部中断响应,即每个通道可以支持从内存到外设、从内存到内存、从外设到内存、从外设到外设4种模式的数据传输。在TD-LTE系统中,原语跟踪使用的是内存到外设模式,每个外设连接到DMA控制器,可以产生DMA脉冲请求或是单一DMA请求,脉冲大小可编程。DMA内部有4个字的FIFO通道,支持8 bit、16 bit、32 bit宽度处理。由于原语跟踪采用的外设是UART支持的8 bit输出,故本文在设计中DMA也采用8 bit处理[2]。
2 DMA信号处理流程与跟踪步骤
数据跟踪的基本机制如下:首先为各层的数据在内存中开辟存储空间,将数据存储到指定缓存中,再由DMA实现内存到外设的数据搬移。本文的外设是UART,将数据搬移到UART的输出缓存区以实现数据跟踪。DMA控制器和外设的信号交互如图2所示。

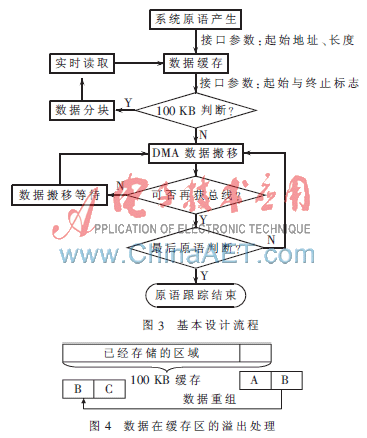
当请求被允许且剩余数据量大于脉冲大小时,DMA控制器发送全部数据脉冲;而剩余数据量小于脉冲大小时,DMA控制器将再次监控请求信号等待下次传输[3]。本文在数据跟踪时将脉冲设置为1以满足数据跟踪实时性的要求。此外,由于单次数据量并不是很大(最大不过字节单位的数据量),因此没有采用链表模式来传输数据。整个跟踪过程主要包括以下几个步骤:首先DMA接收到外设驱动初始化完毕后发送的DMA请求;然后DMA控制器请求CPU将数据搬移到需要使用的总线交给DMA控制,将数据预读取到DMA-FIFO中(即DMA数据搬移内部过程);最后打开DMA通道将DMA-FIFO中的数据传输到UART的输出缓存中,输出到显示设备。其中只有驱动初始化和总线释放过程有CPU参与,而驱动初始化过程是一次性的,之后的步骤都由DMA单独控制从而释放CPU资源以继续执行系统的其他工作。工作中会产生更多的原语需要DMA反复运行支持实时跟踪,图3为数据跟踪基本设计流程。
3 DMA跟踪数据方案设计与分析
数据在内存中的缓存处理方案是:根据TD-LTE无线综合测试仪表系统单次跟踪的数据量大小以及原语产生地址与时间的随机不连续性,DMA搬移数据时设置了100 KB的数据缓存区,以统一数据地址提高跟踪效率[4],从而在合理利用存储空间的同时也保证了数据在传输过程中的高效与完整性,设计中采用起始地址和结束地址标志相减的方式判断单次数据量大小。当数据存储到100 KB缓存边界缓存溢出时,需要采用一定的数据处理机制来做溢出判断,其处理方式如图4所示。将本次的数据量分成A、B两块,分两次分别传输,A部分是本次数据搬移起始位置到100 KB边界位置的数据量,B部分是当前数据总量减去A部分数据后的剩余数据量。这里要注意的是:A部分数据传输完成后,系统可能又产生了新的原语数据块C,因此设计中,在传输数据块B时要重新读取数据的终止标志位加上后面产生的新的数据块C,以保证数据的实时性与完整性。
在TD-LTE无线综合测试仪表系统中,原语是单条产生的,并带有一定的时间间隔。为满足系统对实现数据跟踪的实时性要求,在跟踪数据时也是单条实时显示。这就要求在设计中判定DMA在每次传输是否完成,避免本次传输还未完成而下一次传输已经开始,导致本次传输数据不完整。因此在设计过程中,采用了中断判断模式和中断标志位判断模式两种方案来判定传输是否完成并获取总线来执行下一次数据搬移。
3.1 中断判定模式
根据S3C6410中DMA控制器特性,DMA在数据搬移结束时可以产生数据计数中断或数据错误中断两种中断。设计中打开DMA对应的GPIO(General Purpose Input Output)口并初始化相对应的41号VIC(Vectored Interrupt Controllers)中断向量,就可以利用数据计数中断来完成系统的外部中断响应,进入中断函数,在中断函数中再次调用DMA以此完成多次数据搬移[4]。在使能DMA通道并且数据传输完成后由硬件自动响应中断,有效避免了DMA设备在传输过程中被下一次传输请求打断,而搬移数据和系统其他程序的执行完全互不干扰。这种模式可以在各种数据量大小的数据搬移过程中最大限度地利用CPU资源。但是,由于采用了上述的数据缓存机制,而且在TD-LTE系统中断处理中比DMA计数中断优先级高的中断还有很多,因此采用中断模式在实际运用中会出现以下三种典型不稳定的情况及所采取的措施:
(1)在CPU向缓存中搬移数据过程中产生了中断,此时会出现当前一次要搬移的数据在内存中不完整或标志位混乱的情况,因此,在设计时搬移数据前还需要增加内存数据是否存储完成的标志位判定。由于中断类型众多,设计有一定难度。
(2)最后几条原语数据在存入内存缓存区后,若前面的搬移数据还没有完成,则无法获取总线,则会导致最后几条原语无法跟踪。因此,需要在原语全部发送完毕后在系统程序靠后的固定位置添加一条空的原语跟踪语句来跟踪最后几条。
(3)当出现较大数据量搬移时耗时较长,可能超过上层系统原语发送的间隔时间,后面几条原语将堆积到缓存中,等待下一次DMA总线获取后,一次性搬出,这样会导致下一次数据搬移时间的延长。这一条是基于机制的本质问题,实时性和数据完整性预计会受到较大影响。
3.2 中断标志位判定模式
这种方案的基本思路与中断模式相似,也需要解决DMA反复获取总线的问题。方案中屏蔽了DMA控制器在ARM中的中断响应,在每次系统上层调用数据缓存的过程中加入了DMA接口函数,以这种方式在系统上层作为数据缓存时主动获取总线[5]。采用软件的方式编程判断DMA数据计数中断标志位(在DMACIntTCStatus寄存器中)是否拉高置1,然后以消耗CPU资源为代价来等待传输完成或是传输完成后直接进行下一次DMA总线获取。这种模式以软件方式代替硬件中断响应,可以保证每一条原语在数据缓存后的及时跟踪,也能满足实时性与数据完整性的要求。但该方案也存在机制上的缺陷,其表现为在连续大数据量跟踪时会出现持续消耗CPU、等待DMA数据搬移完成的情况,从而影响系统运行效率。
4 方案性能对比分析
由于两种方案各有优缺点,在调试过程中对两种方案做了详细的对比与分析,最后根据TD-LTE无线综合测试仪表系统的具体特性与应用要求选择了较优的中断标志位判定模式。
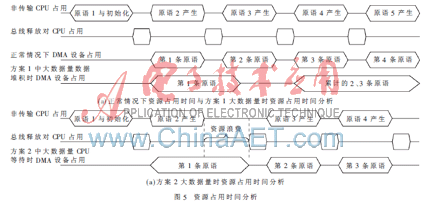
首先,根据设计原理和调试中呈现的不稳定情况,通过对两种方案进行资源占用时间分析,了解它们对系统的影响,图5中分别列出了两种方案中正常情况和不稳定状态下的典型资源占用时间情况。
由图5(a)可以看出,采用中断模式(方案1)出现不稳定情况时,在下次跟踪时会累计更多条原语从而使DMA占用更多时间,虽然CPU资源利用率较高,但是会产生恶性循环,导致最后大量数据无法输出,破坏数据完整性,同时也降低了数据跟踪的实时性。图5(b)中采用中断标志位判定模式(方案2),在出现不稳定情况时,由于各条原语跟踪相对独立,仅在当前一条的原语跟踪后出现对CPU资源占用,虽然对系统总体CPU利用率产生影响,但是不会对后面的原语跟踪产生任何影响。
其次,对两种方案中不稳定情况在TD-LTE无线综合测试仪表系统中发生的可能性进行分析,主要需要考虑系统产生原语数据量的大小以及产生时间间隔这两个参数。在整个调试流程中UART波特率为56 000 baud/s,系统时钟ARMCLK为667 MHz、PCLK为66.7 MHz、HCLK为133 MHz,产生原语平均大小为128 B(其中大部分原语数据量小于这个值,由于个别数据量较大而将平均值拉大)。通过示波器分析可以看出,在单次跟踪数据量为128 B、总次数为10次的数据跟踪条件下,平均时间间隔(每次产生数据跟踪间隔的时间)与小时间间隔(产生数据跟踪间隔的时间小于数据跟踪所需时间)时两种方案的测试情况,其波形与时间分析如图6所示。图6中,A波形为128 B原语数据单次跟踪波形,△X为所需要的时间;B波形为正常时间间隔下连续10次、128 B数据量原语跟踪,其中的间隔时间△X 内CPU仍然在运行,中断模式与中断标志位判定模式在A、B两种情况下的输出占用时间大体相同。C波形是中断标志位判定模式下小时间间隔10次、128 B数据量原语跟踪所输出的波形,在没有原语跟踪的情况下CPU执行时间在190 ms,而这里消耗了227 ms,跟踪数据正常,只是多占用了37 ms的CPU资源。D波形为中断模式下小时间间隔10次、128 B数据量原语跟踪所输出的波形,根据波形输出情况可以断定发生了图5中数据积累情况,导致后面有两条原语在跟踪时由于DMA没有获取到总线而没有输出,对数据跟踪的实时性和完整性影响颇大。

本文介绍的两种DMA原语跟踪方案已经在ARM Workbench IDE v4.0与RealView Debugger v4.0上编译调试,并通过了测试板验证和联机验证。在反复验证后,采取了中断标志位判定模式来实现跟踪。该方案的运行结果与理论值一致,不受系统中其他诸如DSP数据中断、FPGA指针中断等高优先级中断的干扰[4],具有较强的独立性和稳定性,优化了系统CPU资源利用率,实现了DMA数据跟踪的高强度反复稳定运行。
参考文献
[1] Tang Dan,Bao Yungang,Hu Weiwu,et al.DMA cache:using on-chip storage to architecturally separate I/O data from CPU data for improving I/O performance[C].High Performance Computer Architecture(HPCA),2010 IEEE 16th International Symposium.Bangalore,India.January 9-14.2010:1-12.
[2] 唐中燕.DMA技术在嵌入式现场前端设备中的应用[J]. 电测与仪表,2006,43(483):60-61.
[3] Samsung Electronics.S3C6410X RISC microprocessor user's manual[R].2008.
[4] HESSEL S,SZCZESNY D,BRUNS F,et al.Architectural analysis of a smart DMA controller for protocol stack acceleration in LTE terminals[C].The Sixteenth IEEE International Conference on Embedded and Real-Time Computing Systems and Applications.Macau, China.Aug 23-25, 2010:309-315.
[5] DASYGENIS M,BROCKMEYER E,DURINCK B,et al.A combined DMA and application-specific prefetching approach for tackling the memory latency bottleneck[J].Very Large Scale Integration(VLSI) Systems.2006,14(3):279-291.