
文献标识码: A
文章编号: 0258-7998(2012)05-0052-04
在TD-LTE系统中,速率匹配是指传输信道上的比特被重发或打孔。一个传输信道中的数据量在不同的传输时间间隔内可以发生变化,而所配置的物理信道容量是固定的。为了匹配物理信道的承载能力,输入序列中的一些比特将被重发或者打孔,以确保在传输信道复用后总的比特率与所分配的物理信道的总的信道比特率相一致。当输入序列的数据量超过物理信道的承载能力时,需要对输入序列打孔;反之则需要重复。高层给每一个传输信道配置一个速率匹配特性。当计算重发或打孔的比特数时,需要使用速率匹配特性。TD-LTE中根据编码方式的不同,速率匹配分为卷积编码和Turbo编码两种匹配方式。
本文对Turbo编码的速率匹配算法进行了分析并设计了一种在TI公司DSP芯片TMS320C64x上的实现方法。
1 Turbo速率匹配算法
在TD-LTE系统中,发送端对各码块分别进行速率匹配,速率匹配模块包括子块交织、比特收集、循环缓冲器生成、比特选择和修剪。具体的过程是Turbo码的三路输出,分别经过子块交织器后,把这三路数据串行收集在一起, 经过打孔或重复过程得到物理信道要传输的比特。如图1所示。


2 Turbo速率匹配的实现
2.1 硬件简介
TMS320C6000最初是为了移动通信基站的信号处理而推出的超级处理芯片。C64x系列DSP主要的特点是在体系结构上采用了VelocoTI甚长指令集VLIW(Very Long Instruction Word)。在VLIW体系结构的DSP中,是由一个超长的机器指令字来驱动内部的多个功能单元。由于每条指令的字段之间是相互独立的,故可以单周期发射多条指令,从而实现更高的指令级并行效率。CPU采用哈佛结构,程序总线和数据总线分开,取指令与执行指令可并行运行。程序总线宽度为256 bit,每一次取指令操作都是取8条指令,称为一个取指包。C64x系列DSP芯片的大容量、高运算能力的优点使其在无线基站、终端等场合下得到广泛的应用,特别是运算精度能满足综合测试仪表的开发条件。
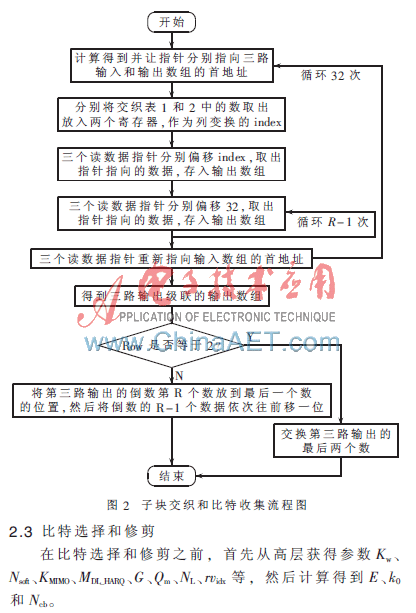
2.2 子块交织和比特收集
将速率匹配的实现分为两个模块来进行,分别是子块交织收集模块和比特选择、修剪模块。这两个模块都采用汇编实现,一些参数的计算用C语言实现。
为了区分NULL比特和有用比特,输入数据按照一个比特占8 bit来存储,NULL比特存储为0FH,0存储为00H,1存储为01H。在输入数据时,Turbo编码模块已经加好NULL比特,而且将三路输出级联。子块交织后的数据仍然是一个比特占8 bit,比特选择和修剪后的输出数据按照一个比特占1位存储。
(1)首先计算每一路输入总比特数KΠ。然后将输入数组首地址加上KΠ,得到第二路数据的首地址,再加上KΠ得到第三路数据的首地址。让三个地址指针分别指向三路输入数组的首地址。输出数组的首地址加KΠ得到第二路的首地址,再加上1得到第三路的首地址,第二路和第三路是交叉放置的,每次存数据时,地址偏移为2。
(2)建立一个32次的外循环,每次外循环处理交织矩阵中一列的数据。依次取出列交织表的各个元素作为index,第一路和第二路从列交织表1中取index,第三路从列交织表2中取index。将地址指针偏移index,同时将指针指向的数据取出来,这相当于取交织矩阵中第一行第index列的数据,将取出来的数据放到输出数组中。
(3)建立一个R-1次的内循环,嵌套在外循环中,每次内循环处理一列中的一个数据。每次循环地址指针偏移32,取出对应的数据,并依次存入输出数组。R-1次内循环结束后,将地址指针重新指向输入数组的首地址。
(4)完成32次的外循环后,将第三路输出的倒数第R个数放到最后一个数的位置,然后将倒数前R-1个数据依次往前移一位。
以上步骤完成了子块交织和比特收集。子块交织和比特收集的流程图如图2所示。
在设计之初,考虑了两种比特选择和修剪方案,一种是先将循环缓冲器中的非NULL比特取出,然后将取得的非NULL拼接成长度为E的输出数组;另外一种是直接从输入数组中依次循环地取非NULL比特,直到取够E个数据为止。第一种方案的不足是当软缓冲器中的非NULL比特数比E大时,多取得的数据会浪费;第二种方案的不足是当E比软缓冲器中的非NULL比特大得多时,会浪费处理时间。综合以上两种情况,在程序的开始部分,先判断E是否大于Ncb,若大于,则程序跳转,采用第一种方案;若不大于则采用第二种方案。
比特选择和修剪模块的输入是输入数组首地址、参数首地址、输出数组首地址。若E大于Ncb,则按如下步骤进行:
(1)首先将参数从参数数组里面取出来,得到E、Ncb、k0的值,让指针指向输入数据的第k0位。
(2)设置两个计数器(计数器0和计数器1),初始值都设置为0。两个计数器都是用来统计取了多少非NULL比特,不过计数器0是用来统计总共取了多少非NULL比特,而计数器1非NULL比特达到32后,就会被清零,实际上它是用来判断取得的非NULL比特数是否达到了32个,如果达到了就将这32比特数据存入内存。
(3)建立一个Ncb次的循环。循环内,依次从k0取出输入数据,然后判断是否为NULL比特。如果是,则对该数据不做操作;如果不是,将临时存储数据的寄存器左移一位,与取得的数据相或。同时两个计数器都加1。判断计数器1是否为32,如果是,则将计数器1清零,同时将临时储存数据的寄存器中的数据存入输出数组,然后清零该寄存器。判断当前指针是否指向输入数组的第Ncb个,如果是,则将指针重新指向输入数组的首地址,继续读下一个数进入下一次循环。当循环次数达到Ncb次时,则跳出循环。
(4)结束上面循环后,判断计数器1是否为0,如果不为0,说明上面还有不到32 bit的数没有存入输出数组,将其存入输出数组。
(5)此时计数器0中的数就是软缓冲器中非NULL比特的数目,记为len。用E除以len,得到商为a,余数为b。这时只需要在上面处理完的输出数组后拼接上面得到的数据a-1次,再拼接b比特就可以完成速率匹配。
(6)先用len除以32,得到商为c,余数为d。这样在拼接时,先建立一个a-1次的外循环,每次外循环拼接长度为len的数据,在每次外循环中建立一个c次的内循环,每次内循环拼接32 bit的数据,在完成c次的内循环后,在外循环中处理多余的d比特。在拼接之前,要先判断d是否等于0,若等于,则程序跳转,每次内循环只需要依次将一个字的数据存入输出数组;若不等于,则说明输出数组中最后的一个字没有被存满,在每次内循环中,要先将待拼接的数据右移,与输出数组中最后一个字中的数据拼接成一整个字的数据,再将待拼接的数据左移,等待下一次循环中拼接。

E大于Ncb时流程图如图3所示。
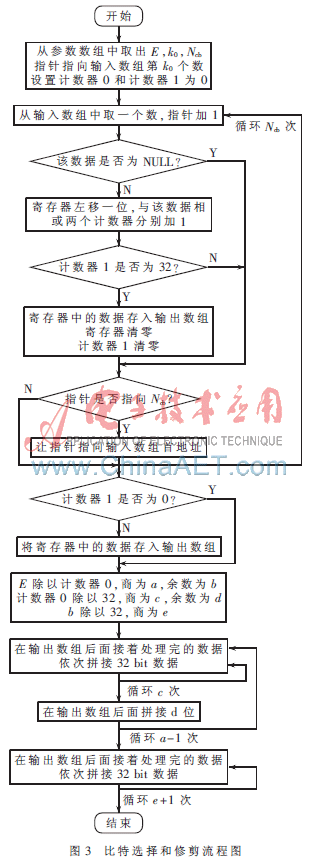
若E不大于Ncb,处理步骤与上面类似,只需要前4步处理,不同之处是步骤3中的循环次数不固定,直到取得E个非NULL比特后就跳出循环。
3 性能分析
在进行DSP程序设计时,需要对程序进行优化,尽量减少或者消除程序中的“NOP”指令,特别是循环体内的“NOP”指令。通过在CCS3.3上运行程序,在Ncb=Kw时,统计得到各条件下的速率匹配仿真执行结果,如表3所示,表中数据的长度为Turbo编码后每一路数据的长度。

表3仅列举了几种典型的数据长度,且不失一般性,通过分析可以看出:比特选择和修剪时,数据长度为1 124时,只需依次取出E个非NULL比特,占用周期较少;数据长度为3 140而E的大小不同时,拼接软缓冲器中的非NULL比特消耗了一部分周期;E的大小相同而数据长度不同时对比发现,将软缓冲器中的非NULL比特取出消耗了大量cycle。所以也可以看出,当E大于Ncb时先将软缓冲器中的非NULL比特取出,再进行拼接的方法可以节省处理时间。
总之,本实现方法可以满足TD-LTE系统实时处理的需要并已经应用到国家科技重大专项项目“TD-LTE无线综合测试仪表”开发中。
参考文献
[1] 3GPP TS 36.212 v9.1.0:Rate matching(release 9)[S]. 2009-12.
[2] 沈嘉,索士强,全海洋,等.3GPP长期演进(LTE)技术原理与系统设计[M].北京:人民邮电出版社,2005,2008.
[3] Texas Instruments Incorporated.TMS320C6000系列DSP编程工具与指南[M].田黎育,何佩琨,朱梦宇,译.北京:清华大学出版社,2006:32-50.