
1 前言
随着RFID(Radio Frequency Identification)技术的推广,越来越多的企业开始使用RFID 技术, 并且正在被应用到很多著名的ERP 系统中去,例如EBS 和SAP 系统。在整合RFID 中间件和ERP 系统时,我们遇到了很多挑战。对于大多数的ERP 系统,高可靠性、高可用性、高扩展性、高性能是至关重要的,因此在RFID 中间件与ERP 系统整合过程中,RFID 中间件也必须像必须向上层应用系统提供高质量的服务, 才能保证整个系统的高可靠性、高可用性、高扩展性、高性能。
为了解决这些问题, 我们将集群技术应用到中间件中来。RFID 中间件是基于组件的形式开发的,因此系统可以粗略的划分为2 个部分:数据和组件。对于数据,我们可以利用集群的分布式数据管理模块来处理, 通过分布式缓存服务形成同一的数据视图,使得每个节点都可以访问到其他节点的数据;通过复制缓存服务为每一个数据在不同节点产生一个备份, 使得数据具有高可靠性和高可用性。对于组件,我们通过组件调度策略是把所有的组件分配到不同的节点去, 以实现系统的高扩展性和高性能。
2 系统架构
2.1 整体架构
设备管理层:RFID 中间件的底层系统部分,完成对RFID 系统中的所有硬件设备的管理与监控。为不同生产厂家的读写设备提供了统一的接口,屏蔽了底层环境的异构性和复杂性;对各种硬件设备进行统一的管理, 极大地简化和加快了应用系统和设备的集成。

数据处理层: 数据处理层需要对原始数据进行处理,包括数据过滤以消除重复读取产生的冗余数据, 位过滤筛选感兴趣的数据,数据聚合分组等等。从而减少数据量并且保留感兴趣的数据。
应用程序级接口层:提供标准化的事件接口,应用系统可通过向其发送事件请求来订阅需要的数据。事件请求中定义了数据处理的方式以及发送报告的格式。该层解析应用系统的事件请求,根据请求中的定义调用设备层获取数据并对采集到的原始数据进行数据缓存、数据编码解析、数据过滤和数据归并等基本数据处理操作。最后将处理结果封装成报告,发送给应用系统。
信息服务层:提供各种RFID 信息服务,包括存储捕获的事件、对事件进行推理、提供信息的查询等,协助应用程序完成相应的业务操作。
业务集成层:用户可以结合具体的业务,定义相应的业务模型, 由RFID 中间件根据定义的业务模型来辅助完成相应业务,最后将处理的结果与后台应用系统进行整合。
集群服务层: 为上层的应用系统提供一个统一的中间件视图,管理集群节点状态,系统所有组件在各个节点间的分配,并且提供统一的分布式缓存视图。
2.2 集群服务层
集群服务层主要由以下4 个部分组成:
跟踪服务:该模块主要管理集群系统内的节点成员列表和注册服务列表。当节点启动时,该服务自动启动,并且将该节点加入到集群中,同时维护集群内其他节点列表,探测节点失败状态,并且维护集群中所注册的服务列表(主要就是分布式缓存服务)。分布式缓存服务:该模块允许节点去访问其他节点的数据,这样就可以使得数据只保存在一个节点中, 另外通过悲观锁来实现分布式缓存的一致性。
复制缓存服务: 该模块同步的复制分布式缓存服务中的数据,将复制数据保存在其他节点上。当数据发生变动时,复制数据自动相应变动。当集群节点增加时,自动将复制数据均摊到新增节点中,实现复制数据的负载平衡。当集群节点发生故障或者离开集群时,备份数据自动变为可访问数据,并且在其他节点备份该数据。
组件管理:该RFID 中间件是面向组件开发设计的,每个层次都是由多个组件串行或者并行组合实现其功能。该模块就是通过制定一定的策略,来决定组件如何分布在各个节点,并且协同工作,来提高系统性能
3 系统实现
3.1 组件定义
组件是系统最基本的功能模块, 每个层次的服务都是通过多个组件串行或者并行组合来实现其功能的。设备管理层的基本组件就是device 组件,每个device 组件对应一个实际读写器,所有的device 组件并行工作就组成了设备管理层。数据处理层的基本组件是各种过滤器,包括冗余过滤器、位过滤器等等,多个过滤器串行工作,使得要处理的数据依次通过这些过滤器,则实现了数据处理层的工作。
3.2 组件结构
每个组件都包含输入和输出, 在这里输入和输出都要挂在数据缓存总线上, 各个节点的数据缓存总线都有分布式缓存服务来管理,并且生成一致的数据视图,这样就把分布在各个节点的组件通过分布式缓存服务整合了起来。结构如下:
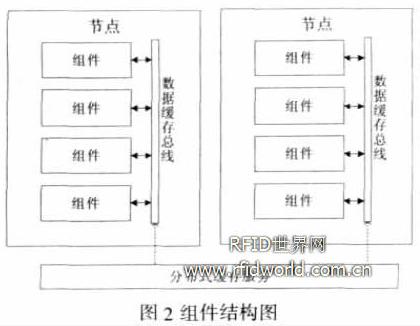
3.3 组件类型
在确定组件协同工作机制之前, 首先需要定义一下组件的类型:有状态组件和无状态组件。
有状态组件:输出结果的产生不只依赖当前的输入数据,还依赖于之前的输入数据。每一次输入数据都会对后续结果的产生有影响。设备管理层的device 组件就是一个有状态组件,因为device 组件中维护着与读写器之间的连接, 该连接是有状态的,所以device 组件也是有状态的。数据处理层的冗余过滤器也是有状态的组件, 因为每次输出结果时都要判断指定时间内是否存在相同的数据。应用程序级接口层的EventCycle 组件CommandCycle组件也是有状态的组件, 因为产生的报告与指定时间段内的所有数据有关。
无状态组件:输出结果的产生只与当前的输入数据有关。在输入数据确定的情况下,输出数据也是确定的。数据处理层中的位过滤器是无状态组件, 因为它只需要根据当前数据数据的EPC 码来判断是否符合过滤条件,与之前状态无关。应用程序级接口层的Dispatcher 组件, 负责将产生的报告分发至指定URI,也是一个无状态组件。
3.4 负载均衡
根据组件分类, 有状态组件和无状态组件我们将采用不同的策略。
对于无状态组件,由于不涉及之前输入数据的状态,数据即时产生即时处理。因此,我们在集群每一个节点处都创建出所有的无状态组件, 每个节点的无状态组件将通过一定负载均衡策略来获得数据的处理权, 从而将数据计算处理的工作量分散到各个节点。
可以采用的负载均衡策略目前有2 种:
轮询调度算法(Round-Robin Scheduling):针对每一个层次,把来自数据缓存总线的数据轮流分配给集群中各个节点, 从1开始,直到N(集群内节点数),然后重新开始循环。由于无状态组件不会占用高消耗的系统资源, 如数据库连结、Socket 连接等(如果拥有连接,该组件应属于有状态组件),因此轮询调度算法基本可以实现无状态组件在各个节点上处理能力的负载均衡。
就近调度算法:在各个层次中,无状态组件一般要与有状态组件相结合,共同完成该层次所提供的功能。就近调度算法就是根据有状态组件所处节点位置,来决定无状态组件所处位置,使该层次中所有无状态组件与有状态组件处于同一个节点。这种算法的优点就是当一个层次中所有串行操作的组件都处于同一个节点时, 数据在每一个组件处理完成时不必在不同的节点间迁移, 大大减少了数据迁移时的时间延迟。该算法的缺点就是,负载均衡的效果很大程度上取决于有状态组件的分布情况对于有状态组件,参见后面的组件调度策略。
3.5 组件调度策略
该策略主要用来分配有状态组件在各个节点的分布, 位于组件管理模块中。
1) 平均分配策略
平均分配策略即将每个层次中的有状态组件平均的分配到各个节点中。
该策略的优点是实现简单, 在加入新节点或者节点故障时也比较容易在集群中重新分配组件。
该策略的缺点是大量的数据迁移带来不可忽视的延迟。不同层次间的数据可能需要迁移到不同的节点, 来移交给下一个层次的组件来处。相同层次内,也有能由多个组件组成一个串行操作,当这些组件位于不同节点时,也会带来大量的层次内组件间的数据迁移。
2) 流水分配策略

如上图所示,流水分配策略就是类似于流水线作业,按层次分配组件,将相同层次的组件放在相同的节点中。
该策略的优点是实现也相对比较简单。使得相同节点内串行操作组件的数据全部位于本地节点内, 完全消除这类数据操作远程存储和数据迁移的时间延迟。
该策略的缺点是不能做到负载均衡, 不同层次间的计算量差异较大,也就导致了不同节点间的负载不均衡。不同节点层次间的数据迁移量很大,
对于这一点可以利用分布式缓存服务的批量迁移功能,减少迁移次数,增大每次的迁移数据量,来减少时间延迟。
3) 并行分配策略
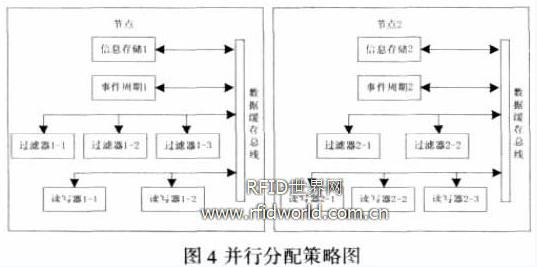
如上图所示,并行分配策略就是类似于并行作业,将处理相同逻辑的读写器定义为一个逻辑读写器组, 从逻辑读写器组出发,跟踪数据流动的路径,将数据流经的所有的组件都分配在同一个节点处。
该策略的优点是使得数据的本地副本只在一个节点内传递,尽可能的消除数据远程调用和数据迁移的时间延迟,复制缓存服务也可以批量异步的完成备份数据的更新操作。
该策略的缺点是程序实现的复杂度高, 当逻辑不相关的组件之间的交叉引用增多时,该策略的效率将会明显下降。这种情况下,应当考虑重新设计组件架构,适当增加重复组件,以减少不相关组件之间的交叉引用关系。
4 小结
本文第一次将集群技术引入到RFID 中间件中来。并且讨论了分布式数据管理和组件调度策略。分布式数据管理通过分布式缓存服务形成同一的数据视图, 使得每个节点都可以访问到其他节点的数据; 通过复制缓存服务为每一个数据在不同节点产生一个备份,使得数据具有高可靠性和高可用性。组件调度策略是把所有的组件分配到不同的节点去, 以实现系统的高扩展性和高性能。最终实现了RFID 中间件的高可靠性、高可用性、高扩展性、高性能。
本文作者创新点: 本文第一次将集群技术引入到RFID 中间件中来, 并且讨论了分布式数据管理和组件调度策略在中间件中的实现,最终实现了RFID 中间件的高可靠性、高可用性、高扩展性、高性能。