
文献标识码: A
文章编号: 0258-7998(2012)09-0011-03
嵌入式领域的处理器设计已向多核处理器迅速发展,TI公司的KeyStone架构的多核处理器就是其中之一。2010年11月,TI公司发布了最新的KeyStone架构的8核DSP处理器TMS320C6678,每个C66x内核频率为1.25 GHz,提供每秒高达40 GB MAC定点运算和20 GB FLOP浮点运算能力;1片8核的TMS320C6678提供等效达10 GHz的内核频率,单精度浮点并行运算能力理论上可达160 GB FLOP,是TS201S的50倍、C67x+的115.2倍[1],适合于诸如油气勘探、雷达信号处理以及分子动力学等对定浮点运算能力及实时性有较高要求的超高性能计算应用。
核间通信是多核处理器系统所面临的主要难点,通信机制的优劣直接影响多核处理器的性能,高效的通信机制是发挥多核处理器高性能的重要保障。TMS320C6678采用TI全新KeyStone多核架构,属于单芯片多核架构,有别于常见的板载多芯片通信方式[2]。而KeyStone架构的通信研究才刚刚起步,因多核通信复杂,需要搭建合适的通信拓扑结构,因此拓扑结构的选取会直接影响通信代价和并行计算的效率[3]。TMS320C6678采用基于KeyStone架构的中断控制器、核间通信寄存器以及合适的通信拓扑结构实现多核间的通信。通过中断系统激活处理器,触发具有通信功能的中断服务程序,调用寄存器完成相应的功能,并通过合适拓扑结构完成通信。
基于以上分析,本文针对TMS320C6678多核处理器,首先分析了中断控制器和核间中断原理及其实现;然后分析了核间通信的原理,给出了通信的发起和响应的实现方法;最后介绍了主辅和数据流两种多核通信的拓扑结构,并通过仿真对其通信代价进行了对比,得出了两种结构的优缺点以及适用范围。对设计多核处理器核间通信有一定指导意义。
1 TMS320C6678中断控制器
TMS320C6678采用基于KeyStone架构的中断控制器INTC(Interrupt Controller)[4]、激活处理器触发相应的中断服务程序,完成通信的第一步。
首先需要配置中断向量表,启动CPU中断功能。TMS320C6678的CPU可接收15个中断,其中:1个硬件异常(EXCEP)、1个不可屏蔽中断(NMI)、1个复位(RESET)和12个可屏蔽中断(INT4~INT15),中断源支持最多128个。每个核心通过事件控制器产生事件(Event),触发核间中断(IPI)和其他核心进行通信。在TMS320C6678中,核间中断(IPC_LOCAL)默认对应91号事件,而核间中断属于可屏蔽中断,通过中断控制器可以映射到INT4~INT15任意一个中断上。为了实现核间中断,必须按以下方式进行设置:
(1)控制状态寄存器(CSR)中的全局中断使能位置为1,全局中断使能;
(2)中断使能寄存器(IER)中的NMIE位置为1,可屏蔽中断使能;
(3)中断使能寄存器(IER)将要映射的可屏蔽中断的相应位置1;
(4)选择91号事件作为中断源,映射事件到指定的物理中断号。中断发生后,将中断标志寄存器(IFR)的相应位置1。
中断发生时,由事先配置好的中断向量表跳入中断服务程序(ISR),完成核间通信,如图1所示。

2 多核处理器的核间通信机制
多核处理器由中断触发通信后,配置相应的寄存器,以完成通信。TMS320C6678主要的核间通信寄存器有16个,其中8个IPC中断生成寄存器(IPCGR0~IPCGR7)和8个IPC中断确认寄存器(IPCAR0~IPCAR7)。将IPC中断生成寄存器IPCGRx(0≤x≤7)的最后一位IPCG位置1,就能产生对core_x的中断;1~3位是保留位,4~31位(SRCS0~SRCS27)提供了可以识别多达28种的中断来源。IPC中断确认寄存器IPCARx(0≤x≤7)的0~3位是保留位,4~31位(SRCC0~SRCC27)分别对应28种不同的中断来源。当SRCSx被置1时,寄存器将相应的中断确认寄存器的SRCCx位置1。当中断被确认后,寄存器将SRCCx和相应的SRCSx位同时置0。
当TMS320C6678的一个处理器核准备与其他处理器核通信时,根据TMS320C6678的中断事件映射表,引发91号事件,产生可屏蔽的核间中断,调用中断服务例程。中断服务例程IPC_ISR函数设计如下:
void IPC_ISR()
{
KICK0 = KICK0_UNLOCK;
KICK1 = KICK1_UNLOCK;
*(volatile uint32_t *) IPCGR[2] = 0x20;
*(volatile uint32_t *) IPCGR [2] |= 1;
KICK0 = KICK0_UNLOCK;
KICK1 = KICK1_UNLOCK;
}
以向core_2发送0x20信息的中断为例,对应的0x20的信息存入SRCS位中,用于识别中断源。同时将当前CPU核心内的中断产生寄存器IPCGR2的最后一位IPCG位置1,触发IPC中断。当目标处理器核被中断触发后,会自动跳转到中断异常向量表中相应的入口点,读取当前核心中断产生寄存器IPCGRx(0≤x≤7),从寄存器的SRCS位中获取通信发起方传来的核间信息。然后将信息存入对应的中断确认寄存器IPCARx中,清空SRCC和相应的SRCS位,用以接收下一次的核间中断。其中的KICK0和KICK1为陷阱控制寄存器,用来避免通信冲突的发生。
3 拓扑结构设计与性能测试
以上对TMS320C6678基本核间通信机制及其实现过程进行了分析,但是要实现TMS320C6678强大的多核功能,必须从系统的角度上设计良好的并行计算方案,设计合适的系统并行拓扑是其中的关键所在。通信代价、带宽和功能是评测通信的重要指标,下面介绍了两种多核通信并行方式,分析了它们的拓扑结构,并对上述指标做了测试对比。
3.1 通信的拓扑结构
适用于多核DSP通信的并行方式有两种:一种是主辅拓扑结构(Master Slave)[5],另一种是数据流拓扑结构(Data Flow)[6]。
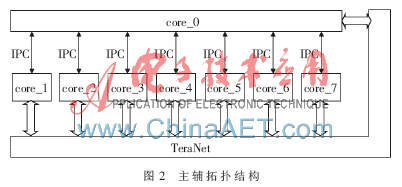
主辅拓扑结构,在TMS320C6678中如图2所示。作为主核(控制核)的处理器通过EDMA与外部存储器DDR进行数据交换,然后主核通过核间中断与辅核通信。主核起到控制的作用,所有辅核(计算核)的中断都由控制核来处理,辅核只负责计算任务,辅核之间没有任何核间通信的产生。
数据流拓扑结构,在TMS320C6678中如图3所示,是一种基于片上互联的结构。每个处理器核均有单独的处理单元和存储媒介。第一个核与FPGA或者外部存储器DDR相连,核间通信顺序产生。核间通信时每个处理器核既是控制核又是计算核,核间传递的信息在每个核内都起到一个中转站的作用。

3.2 性能测试实验
本文设计了核间通信测试程序来测试两种结构。程序的功能是:当一个核收到来自其他核的中断后,立即确认并按照拓扑结构依次发出核间中断,没有其他耗时的操作。程序在TMDXEVM6678L评估板上进行仿真,板载有一块TMS320C6678芯片,处理器运行的频率设置为1 GHz,采用的编译环境是TI公司的CCSv5.0。
通信测试结果如表1所示,主辅结构运行完测试程序所需要的总通信代价是171 352个时钟周期。其中,作为主核的core_0耗费116 311个时钟周期,而7个辅核每个核均耗费7 863个时钟周期。采用数据流结构运行完测试程序所需要的总通信代价是171 319个时钟周期,其中core_0耗费21 385个时钟周期,core_7耗费21 366个时钟周期,其他6个核耗费21 428个时钟周期。
如图4所示,采用主辅结构时,作为辅助核的7个核可以同时并行运行,理论上通信时间可以减少到124 174个时钟周期。主辅结构由于利用了多核的并行处理,总的通信时间是数据流结构的72.5%,以测试环境中的1 GHz的主频计算,则节省了47.1 μs。

主辅结构涉及到通信任务的分配,主核的设计困难,而且辅核之间不能通信。每个线程的执行时间可能是随机的,作为控制核的主核需要最优化负载均衡以达到系统最优的并行效率,适用于高级的操作系统(如Linux)上,并预先要设定好每个核的通信线程,由操作系统进行调度。
数据流结构的优点是数据带宽有保证,可扩展性好。但是设计过程复杂,而且由于具有比较高的数据传输速率,对通信带宽有较高的要求,因此数据流结构更适用于简单的实时系统。因为每个数据单元的传输都是统一的,结构相对简单,数据的通信也是有规律的,不过通信时间较长。
本文研究了基于TMS320C6678多核DSP处理器的核间通信,深入分析了核间中断、核间通信机制(包括寄存器配置以及具体的实现方法),讨论及测试了主辅结构和数据流结构两种多核通信的拓扑结构,并对比了两者的性能和优缺点。对设计多核DSP处理器的核间通信有一定的指导价值。
参考文献
[1] Texas Instruments Inc. TMS320C6678 data manual[Z].2011.
[2] 邢向磊,周余,都思丹.基于ARM11MPCore的多核间通信机制研究[J].计算机应用与软件,2009,26(5):9-10,110.
[3] 谢子光.多核处理器核间通信技术研究[D].成都:电子科技大学,2009.
[4] Texas Instruments Inc.KeyStone architecture interrupt controller user guide[Z].2011.
[5] 陈国兵.嵌入式异构多核体系的片上通信[D].杭州:浙江大学,2007.
[6] Texas Instruments Inc.Multicore design overview[Z].2011.