
摘 要:考虑到人脸表情识别问题在未来的科学应用中可能出现的样本分布不均匀的情况,在提高识别率的基础上,针对这类问题进行了实验研究,将一种改进的AdaBoost算法与SVM结合运用到表情分类当中。实验结果表明,在出现稀有样本的情况下,相对于普通的AdaBoost训练SVM以及单纯的SVM进行多分类的方法,该算法在识别率方面有了很大提高。
关键词: 人脸表情识别;预处理;Gabor变换;IAdaBoost
对人类面部的表情本质信息进行特征的提取分析,并利用人类的认知和思维方式对其归类及理解,参考人们在情感方面所具有的先验知识让计算机思考和推理,从而据此从人们的面部表情中分析并理解他们的情绪,这就是人类面部表情识别所要做的工作[1]。
本文采用一种改进的AdaBoost算法[2]与支持向量机[3]组合的分类方法,使其能够处理多分类的表情问题,采用该方法的最大优点是能够在实验的训练过程中考虑分布稀疏样本的重要性,使得稀有类别中的样本也能具有较高权值,并且采用了规则抽样的方法,使得其可以较大概率地被选中,这样在之后的迭代过程中更容易被抽到,从而可以有效避免分类器忽视稀有类这一现象的发生,使稀有类样本正确划分更有利。
之所以采用这种分类,是因为所研究的表情分类问题,其最终目的还是要应用到实际生活当中,六类表情在人们的生活当中出现的概率肯定是不尽相同的,像厌恶、悲伤的表情还是要比高兴少,当出现样本分布不均匀的分类情况下,本文研究的算法就可能体现出价值。
1 系统概要
通常来说,把一个完善的人脸表情识别过程分成人脸的检测过程、人脸本质特征的提取过程以及表情的分类过程3个小环节。因此,如果建立一个正常的表情识别系统,第一步需要对人们的面部进行检测和定位[4],其后通常还有一个预处理[5]的过程,进行预处理的主要目的是尽量除去图像因采集因素差异而造成的不同,确保了图像能有一个同等的实验环境,这样再进行表情识别的研究,就可以有效地提高识别的效率。第二步把静态图像或动态的视频序列中能表征人脸表情本质的信息提取出来,其后通常有一个二次特征降维[6]的过程,来进一步降低提取特征的维数。第三步进行特征分类[7],即将输入到系统的人脸表情正确地分类到相应的类中。系统核心框架如图1所示。

1.1 人脸检测
目前,已有很多的人脸检测算法,本文采用由Paul Viola等人提出的基于Haar小波基函数的的矩形特征与级联的Boosted机器学习相结合的对象探测算法进行人脸检测。首先利用样本(大约几百幅样本图片)的Haar特征进行分类器的训练,得到一个级联Boosted分类器,分类器训练完以后,就可以应用于输入图像中的感兴趣区域的检测。为了检测整幅图像,可以在图像中移动搜索窗口,检测每一个位置来确定可能的目标。为了搜索不同大小的目标物体,分类器被设计为可以进行尺寸改变,这样,为了在图像中检测未知大小的目标物体,扫描程序通常需要用不同比例大小的搜索窗口对图像进行多次扫描。
Intel开源OpenCV计算机视觉库已经有效地实现了该算法。本文利用OpenCV库函数进行人脸检测,从输入图像中获取人脸的位置和尺寸信息。为了有效地检测到人脸位置,又不致于使检测扫描的次数过多影响系统运行时间,本文在日本ATR女性表情数据库(JAFFE)[8]和CMU的Cohn-KanadeAU表情数据库[9]上进行了人脸检测的实验。首先对图像库待检测的图像进行了分析计算,以获取图像类Haar特征[10],再利用训练好的AdaBoost算法来处理这些得到的类Haar特征,以检测待测图像,最终显示出了人脸的具体位置。在日本ATR女性表情数据库(JAFFE)上所做实验的部分检测结果如图2所示。

1.2 图像预处理
因为采集设施的差异、光照因素的不同以及环境背景的变换等因素会影响到所输入到系统的图像,因此,在进行表情特征提取前,检测获取的人脸区域还需要进行另外的一些处理,这就是通常所讲的预处理操作。
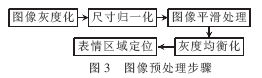
图像的预处理步骤通常包括了尺寸的归一化、噪声的去除以及灰度的均衡化等,正如前文所说,这样做的目的是尽量消除图像采集因素间的差异,以确保图像能有一个同等的实验环境,这样再进行表情识别的研究,就可以有效地提高识别的效率。
本文采用的图像预处理大致步骤如图3所示。
2 特征提取和降维
2.1 Gabor特征提取
由Gabor函数经过尺度的伸缩及旋转而生成的一组复函数系,称为Gabor小波[11],其具有的多分辨率特性以及良好的时频局部化特征,使得它可以提取到待测图像局部细微的变化,因此,它很适合于人脸表情特征提取。此外,其对于光照的变化不敏感,具有较好的光照性。
被用作提取特征和表征图像的方法,Gabor滤波器在图像分析、图像识别等领域得到了很大程度的应用,这里关于它的原理就不再赘述,主要说下本文的思路和实现。
假如对整个待测的图片直接做Gabor变换[12],经过实验得到的维数是非常大的,因此为了便于后续的表情分类,可以设想,由于人们的每一种表情其实主要是在眉毛、眼和嘴部等这些个最能代表面部表情特征的区域进行了较为集中的展现,因此就可以对第一步人脸检测过程中,通过图像的预处理已经定位出的表情区域进行有目的的选择,即选择最能代表人脸表情本质信息的区域,并对这些个区域进行一些网格化的处理。这样不但可以使特征向量的维数有效地减少,还保留了原始表情本质信息的有效性。经过试验比对,最终选取了Gabor的核函数窗口为61×61,变换频率总数为3,变换方向总数为7的情况来获得最佳的识别率。而对于表情区域的网格化,则选取了眼部区域尺寸为35×42,嘴部区域尺寸为28×63,表情的子网格颗粒尺寸为7×7的情况来获取最佳的识别率。Gabor滤波器提取表情特征的大致步骤如图4所示。

2.2 AdaBoost二次降维
虽然区域化选择表情特征使得提取到的特征图像维数有了一定程度的降低,但是对于识别分类的要求而言,其维数还是比较高的,因此,本文又选取了AdaBoost的修改算法进行二次降维。在这个过程中,令每一个弱分类器仅仅对应于1个特征,并且由特征值大小来对分类进行判断,这样一来,Adaboost对于弱分类器的挑选过程也就成了对于特征的挑选过程。整个特征提取的过程如图5所示。

3 基于改进的AdaBoost算法的表情分类
3.1 AdaBoost算法
AdaBoost算法是一种分类器算法。具体来说,AdaBoost学习算法的核心思想是从一个很大的特征集中选择很小的一部分关键的视觉特征,从而产生一个及其有效的分类器。它利用大量的分类能力一般的简单分类器通过一定的方法叠加(Boost)起来,构成一个分类能力很强的强分类器,再将若干个强分类器串联成为分级分类器(Classifier Cascade)完成图像搜索检测。串联的级数依赖于系统对错误率和识别速度的要求。这种用“Cascade”来不断组合成更复杂的分类器的方法可以使图像的背景区域能够很快地被排除掉,而将更多的计算花费在更有希望成为目标的区域。对于每一种特征而言,弱学习器决定弱分类器的最佳的门限值,使其具有最小的误分样本数。全部的检测过程的形式就是这样的一个退化的决策树。

3.2 IAdaBoost算法
本文采用把AdaBoost应用到SVM的多类分类方法,不同之处是对AdaBoost中随机抽样的方法做了改进,采用了规则的抽样方法来提高分类器的泛化能力,把按照这样的方法改进的AdaBoost算法叫做IAdaBoost算法[13]。
IAdaBoost是利用AdaBoost迭代的思想训练支持向量机的基分类器。AdaBoost本身用的是抽样处理,即把自助的样本集从原始的数据集中提取出来,并自适应地进行多轮迭代,但该算法在建立稀有类的分类模型上有局限性,而IAdaBoost可以很好地解决此类问题。它使用了规则抽样,并用样本所在类的规模来标记样本的初始权重,赋予了稀有类样本比较高的权值,使得这些样本能够拥有较大的概率在规则抽样中被选中,并且在迭代过程中较容易被抽到,从而使得分类器忽视稀有类的现象得以避免。可见,IAdaBoost算法在处理具有稀有类的分类问题上,相比AdaBoost算法有了改进。

4 实验与分析
在日本ATR女性表情数据库和CMU的Cohn-KanadeAU表情数据库上针对除中性之外的六种表情,进行了两组对照试验,即在表情数据库上做每类样本大致相同时和某几类样本明显减少时的对照试验来检测本文方法的可行性。本文将悲伤和厌恶两类样本作为了稀有样本,将其样本数量减少至一半,这也是主要考虑到在以后的社会应用中,此类样本出现的概率肯定要比高兴等其他表情要少,凸显了本文的研究目的。在日本ATR女性表情数据库上进行的不同算法多次实验的平均识别水平如表1和2所示,在CMU的Cohn-KanadeAU表情数据库上进行的不同算法多次实验的平均识别水平如表3和4所示。
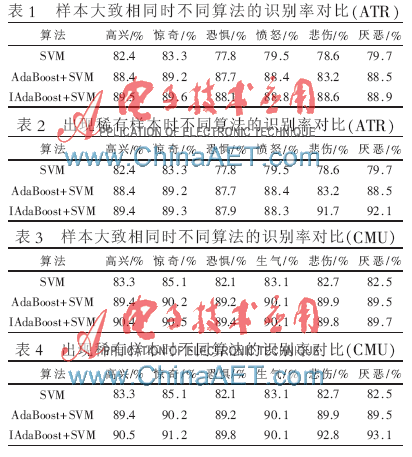
本文针对人脸表情识别问题在未来的科学应用中可能出现的样本分布不均匀的情况,在提高识别率的基础上,采用IAdaBoost训练SVM的多分类方法很好地解决了这一问题,在实验中使用规则抽样,并用样本所在类的规模来标记样本的初始权重,赋予了稀有类样本比较高的权值,使得这些样本在规则抽样中被选中的概率较大,并且在迭代过程中较容易被抽到,从而使得分类器忽视稀有类的现象得以避免,并达到了很好的效果。
参考文献
[1] 王志良,陈锋军,薛为民.人脸表情识别方法综述[J].计算机应用与软件,2003,20(12):63-66.
[2] 武妍,项恩宁.动态权值预划分实值Adaboost人脸检测算法[J].计算机工程,2007,33(3):208-209.
[3] 应自炉,唐京海,李景文.支持向量鉴别分析及在人脸表情识别中的应用[J].电子学报,2008,36(4):725-730.
[4] 梁路宏,艾海舟.人脸检测研究综述[J].计算机学报,2002,25(5):449-458.
[5] 孔凡芝,张兴周,谢耀菊.基于Adaboost的人脸检测技术[J].应用科技,2005,32(6):7-9.
[6] 王志良,刘芳,王莉.基于计算机视觉的表情识别技术综述[J].计算机工程,2006,32(11):231-233.
[7] 章品正,王征,赵宏玉.面部表情特征抽取的研究进展[J].计算机工程与应用,2006,38(9):38-42.
[8] LYONS M, BUDYNEK J, AKAMASTU S. Automatic classification of single facial images[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1999, 21 (12): 1357-1362.
[9] KANADE T, COHN J F, TIAN Y. Comprehensive database for facial expression analysis[C]. Proceedings of the Fourth International Conference of Face and Gesture Recognition, Grenoble, France, 2000: 46-53.
[10] LIENHART R, MAYDT J. An extended set of Haar-like features for rapid object detection[C]. IEEE ICIP 2002, 2002, 1: 900-903.
[11] 印勇,史金玉,刘丹平.基于Gabor小波的人脸表情识别[J].光电工程,2009,36(5):111-1169.
[12] 王化勇,李昕.基于改进的Gabor和ADABOOST的人脸表情识别[J].辽宁工业大学学报(自然科学版), 2010,30(1):17-19.
[13] 李亚军,刘晓霞,陈平.改进的AdaBoost算法与SVM的组合分类器[J].计算机工程与应用,2008,44(32):140-142.