
摘 要: 为了使VTL(虚拟磁带库)系统能更有效地利用磁盘空间,存储更多的数据信息,介绍了一种带有重复数据删除算法的虚拟磁带库应用方法。该方法从性能和效率等多方面考虑,首先把磁带按文件级去重,再将文件切分成块,通过Bloom Filter和MD5算法双重计算,经查找和存储实现数据块级的重复删除。实验测试证明,该方案稳定地实现了数据的去重及加密功能,能有效节省虚拟磁带库的存储空间。
关键词: 虚拟磁带库;重复数据删除;Bloom filter;MD5
进入21世纪以来,在科技飞速发展的同时,数据信息的产生也在急剧增长。据悉,企业的数据量平均年度增长率为50%左右,部分数据的冗余率却在60%以上。这使得备份时需消耗大量的时间和空间去存储重复的数据,资源浪费十分严重。为了实时存储大量有效的信息,针对物理磁带库存储容量小和效率低等不足,人们引进了虚拟磁带库技术,将高速磁盘阵列仿真成磁带格式,节省了磁带机上带、定位、退带等机械动作时间,同时无需担心机械手故障、磁头耗损或磁带受潮等问题。节省成本的同时提高了备份和恢复速度,实现了实时有效地存储海量数据信息。
尽管虚拟磁带库在应对数据存储时发挥了巨大作用,但是仍不能满足市场需求。如何对存储在虚拟磁带库系统中的数据进行重新压缩从而更有效地利用存储空间,便成为了如今研究的热门课题。而重复数据删除技术作为目前企业热捧的技术之一,在数据压缩处理和存储领域具有很大的应用空间。本文提出了重复数据删除算法在虚拟磁带库系统中的一种应用方案。
1 相关概念和算法介绍
1.1 重复数据删除算法
重复数据删除算法又名智能压缩算法,是一种通过消除冗余重复数据减少存储需求的方法。
重复数据删除算法有多种分类方法。按照重复内容识别方法分类可分为三种:基于内容散列识别、基于内容识别和基于Hyper-factor识别;而基于消除冗余执行次序的分类则可以分为在线式消冗和后处理式消冗两种;基于去重粒度分类可分为文件级、数据块级和字节级消冗三种[1]。本文在虚拟磁带库系统的应用主要采用基于散列识别方法的数据块级后处理式消冗方案。
1.2 数据分块算法
基于数据块级的分块算法主要有定长切分、CDC切分和滑动块切分三种[2]。
定长分块算法(Fixed-Size Partition)主要采用预先分配好的块对文件进行切分,并计算弱校验值和MD5强校验值。该算法的优点是简单、性能高,但它对数据插入和删除非常敏感,处理十分低效,不能根据内容变化作调整和优化。
CDC(Content-Defined Chunking)算法是一种变长分块算法,它应用数据指纹将文件分割成长度大小不等的分块。CDC算法对文件内容变化不敏感,插入或删除数据只会影响到较少的数据块,其余数据块则不受影响。该算法也有缺陷,数据块大小的确定比较困难。
滑动块(Sliding Block)算法结合了定长切分和CDC切分的优点,数据块大小固定。它对定长数据块先计算弱校验值,如果匹配则再计算MD5强校验值,两者都匹配则认为是一个数据块边界。该数据块前面的数据碎片也是不定长的数据块。如果滑动窗口移过一个块大小的距离仍无法匹配,则认定其为一个数据块边界。滑动块算法对插入和删除问题的处理非常高效,并且能够检测到比CDC更多的冗余数据,但它容易产生数据碎片。
1.3 哈希查找和存储算法
1.3.1 MD5算法
MD5算法即消息摘要算法第5版,由MIT计算机科学实验室和RSA数码保安公司联合开发,经MD2、MD3和MD4延伸而来[3]。它将文件的任意一段内容通过一系列算法压缩成一段128 bit的信息摘要(哈希值)。其本质即为一种哈希函数,具有单向性、抗弱碰撞性和抗强碰撞性等特点。
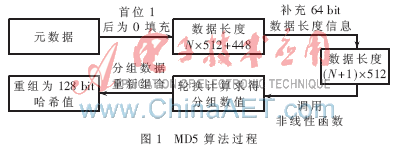
在MD5算法操作中,先对元数据信息进行填充,使得其字节长度对512求余结果为448;接着填充64 bit数据段长度信息,凑齐为512的整数倍;然后用4个固定的链接变量作为参数对MD缓冲器进行初始化;最后用4种不同的非线性函数进行轮换计算,结果输出4个32 bit即128 bit的哈希值[4-5]。算法过程如图1所示。
1.3.2 Bloom Filter算法
Bloom Filter由Howard Bloom在1970年提出。它利用位数组很简洁地表示一个集合,并能通过一组哈希映射函数判断一个元素是否属于这个集合。该算法具有很好的空间效率和时间效率,但是却有一定的误识别率(假阳性误判),并且删除操作比较困难。
该算法主要包括数据元素的查找和插入两部分。在查找操作中,首先将目标信息存储到一个集合S中,接着设计多个相互独立的哈希函数及适度大小的哈希表,并设其初始值全为0。在集合S中任取一个元素,经哈希函数分别映射到哈希表中。如果所对应哈希表位置的值都为1,则说明该元素可能已经存在,但也有误判的可能。若有任意其中一个位置不为1,则说明该元素必不存在。同样插入操作经哈希函数计算并映射后,把相应位置的值都置为1。
2 方案设计及实现
2.1 应用场景
图2所示为常见的一种应用虚拟磁带库进行数据备份的场景。各个客户端所产生的数据通过网络传送到服务器端,在服务器中备份软件的操作下,将数据备份到虚拟磁带库所模拟成磁带格式的磁盘阵列中,该磁盘阵列由相应的RAID组构成,从而进行容灾保护。该数据可以实时导入、导出到相应的物理磁带库中。同样,数据流的逆向即可实现数据恢复作业。在虚拟磁带库系统中可以对所备份的数据进行重新扫描和重复数据删除,并存储压缩后的数据,选择是否删除原有数据,进而节省大量的磁盘空间。

2.2 系统结构设计
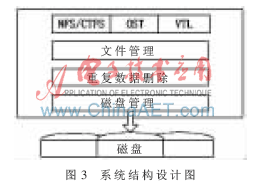
带有重复数据删除功能的虚拟磁带库系统结构设计如图3所示。上层为包含有支持NFS/CIFS、OST及VTL等文件协议的文件协议读取层,该层将存储子系统进行网络化,实现存储内容的高速共享访问。下一层为文件管理层,该层主要实现对数据存放文件及命名空间的管理和设置。文件管理层下面为重复数据删除模块,主要对搜寻到的数据文件进行分块处理、哈希计算和查找并归类存储等操作。下一层为磁盘管理模块,主要负责对磁盘阵列数据元数据和哈希值的分类存放和获取,以及磁盘访问顺序的优化处理等。
2.3 重复数据删除功能详细设计
为实现文件中重复数据的删除功能,本文进行了如图4所示的详细设计。首先该模块对虚拟磁带库中需处理的磁带文件进行查找和获取,然后计算出相应的哈希值,先用Bloom Filter 算法进行快速计算和查找,如果位数组A中已存在相关的文件,则再次进行MD5算法计算和查找,如果位数组A中的确存在该文件,则只存储该文件相关哈希值,接着进行下个文件的处理。如果在Bloom Filter算法的位数组A中不存在该数据的信息,则进行添加和更新,接着完成对该文件哈希值的存储,然后对该文件进行数据块级的处理。由于在Bloom Filter中可能出现误判,故而当MD5再次校验不存在时,同样也会进入数据块级处理中。
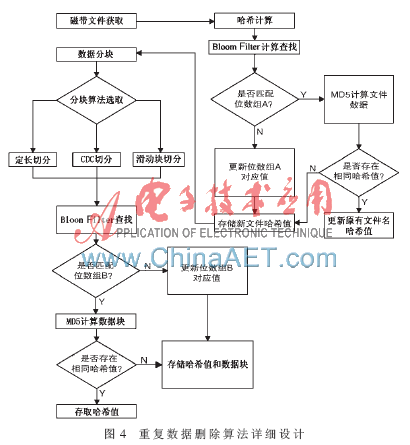
本文应用可以根据需要选择定长、CDC、滑动块任意一种切分方式来进行数据块划分。接着对所切分的数据块进行如同文件级别的Bloom Filter和MD5双重验证。首先对数据块进行Bloom Filter计算,当结果不匹配位数组B中相关位时,则表明该数据块必不存在,对位数组中相关位进行插入和更新,并分别存储该数据块和相关的哈希值;如果该数据块匹配该位数组B时,则再次进行MD5计算和校验。如果仍然匹配,则说明该数据块重复,只存储该数据块的哈希值;如果出现不匹配情况,则说明前面计算出现误判,分别存储该数据块和相应的哈希值。
数据块及相应哈希值存储及检索如图5所示。当文件A进入计算时,会生成相应哈希值并指向对应数据块。当首次查找数据块N不存在时,则先存入数据块,然后再把数据块N的索引指向该数据块所在位置,当再次查找时,仅存储对应哈希值。文件A检索完毕后同样对文件B进行相关操作。而当A’经计算与文件A内容相同时,则文件A’的索引会指向文件A的索引,当文件A’数据恢复时,通过指引直接检索调用文件A中的索引值,从而进一步加快效率,节省存储空间。

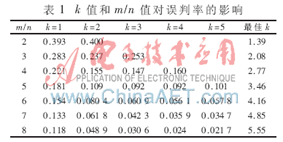
若使f≤0.01,则需m≥9.567n,此时取k=7[6]。表1中所示数据可获得不同k值和m/n下对应的误判率的大小以及m/n固定时取得最小误判率的最佳k值。

实验中采用分块大小为4 KB,共对5组大小及内容不同的文件进行了数据的重复删除处理。由表2可知,文件1中TXT文件和文件3中PDF文件存在相当数量的重复块;而照片、音频和视频等文件存在较少重复数据块。由于测试环境限制,本次测试的子文件都不相同,且数据量小,所以重删率较低,甚至出现小于1的情况。不过数据经还原处理后,与原始数据相比完全相同,安全性能有保障,当出现大量重复文件时,效果更好。
本文主要介绍了一种重复数据删除算法在虚拟磁带库系统中的应用方法。该应用采用后处理式的数据分块哈希计算方法来进行数据的重复删除。数据分块可选择使用任一种常用的3种分块方法,数据查找和存储采用Bloom Filter和MD5算法双重计算,经过设置参数有效地降低了Bloom Filter的误判率和MD5算法的碰撞率。有效提高了存储的时间效率和空间效率,并获得良好的重删率,同时完成了数据的压缩和加密双重功能。
参考文献
[1] 付印芳,肖侬,刘芳.重复数据删除关键技术研究进展[J].计算机研究与发展,2012,49(1):12-20.
[2] 敖莉,舒继武,李明强.重复数据删除技术[J].软件学报,2010,21(5):916-929.
[3] RIVEST R.The MD5 message digest algorithm[M].RFC 1321,1992.
[4] 陈少晖,翟晓宁,阎娜,等.MD5算法破译过程解析[J].计算机工程与应用,2010,46(19):109-112.
[5] 张裔智,赵毅,汤小斌.MD5算法研究[J].计算机科学,2008,35(7):295-297.
[6] HOROWITZ E,SAHNI S,MEHTA D.Fundamentals of data structures in C++[M].Computer Science Press,1995.