
摘 要: 为了提高Huffman解码的效率和实时性,采用并行处理技术和改进的Huffman并行解码算法,设计基于现场可编程门阵列FPGA的Huffman并行解码器。在不考虑Huffman编码长度的情况下,解码器通过插入流水线结构的方法将Huffman码流的码流头和信息码流分开,同时进行解码。硬件仿真结果表明,在一个时钟节拍内解码器处理的数据位数与解码效率成正比,位数越多,实时性越好。
关键词: Huffman解码;并行解码器;码流头;流水线结构
在静止图像和运动视频的压缩方法中,由于信息量大、速率快,使得编解码效率的提高迫在眉睫。最常用的编解码方式是基于可变长编码VLC(Variable-Length Code)的Huffman编解码[1]。与编码相比,并行Huffman解码较复杂。其实时性不仅要提高时钟频率,还需要从算法、硬件优化的角度提高。
通过改进文献的Huffman解码算法[2-3],在原有基础的解码中加入流水线结构。针对参考文献[4]中Huffman编码方式设计并实现了一种能够节省码字存储空间的、可以提高解码速度的并行Huffman解码方式。
1 Huffman并行解码算法改进
Huffman并行解码方式可以弥补查找表过大引起硬件开销大的不足。与并行解码算法相比[5-7],本算法在解码结构中插入流水线,在并行解码方式中,当头码流分析结束时,输入到解码器中的信息码采用并行多路检测,得到地址偏移量和最小编码的长度。在每个时钟周期内,都会输出一个解码信息码。Huffman并行解码器总的处理过程如图1所示。

2 JPEG中的Huffman并行解码设计
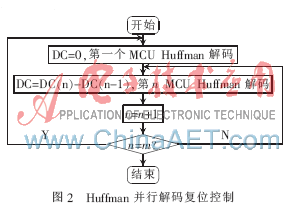
在码流分析中可以得到Huffman编码时的相关信息,即相同长度的最小编码、最小编码的个数和Huffman编码相关值,并分别存入对应的存储器中,再把相应的地址存入16×8存储器里,编码相关值则存入256×8的寄存器中。还需设定Huffman解码的重启间隔,这由JPEG的DC差值编码决定。为了防止解码中造成较大的误差,每解码m比特就需对DC进行清零,其中m为重启间隔度量值。Huffman并行解码复位控制如图2所示。
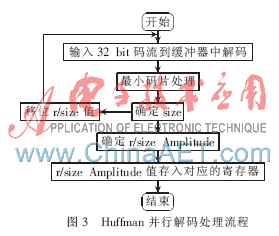
在码流分析中,确定Huffman并行解码的相关信息后进行解码。对JPEG来说,最终要找到AC=0的个数Run、AC的位数Size和幅度Amplitude,以及DC的Size和Amplitude。在JPEG中,AC和DC分别是交流系数和直流系数,其中AC和DC各自又包含色度和亮度。进行一次Huffman并行解码处理流程是整个Huffman并行解码器的关键流程之一,处理流程如图3所示。
输入码流的关键处理是在输入并行多路检测上,它可以同时处理当前对应的最小编码长度、最小编码的解码及其地址偏移量。通过对输入码流的处理,最终得到Huffman并行解码所需要最小编码的Run、Size、Amplitude信息,其并行多路实现方式如图4所示。获得当前编码的宽度提供给当前解码器使用。在当前编码进行对应的最小编码的处理时,同时与在码流分析中得到的存入存储器的最小编码进行比较,确定当前码流解码需要的间隔。其具体过程如图5所示,其中DC、AC就是从码流分析中存入存储器的。解码获得Run、Size及Amplitude的实现流程方式如图6、7所示。但是要注意DC中Huffman并行解码只能得到相应最小编码的Size和Amplitude。而在AC中Huffman并行解码可以得到相应最小编码的Run、Size及Amplitude。
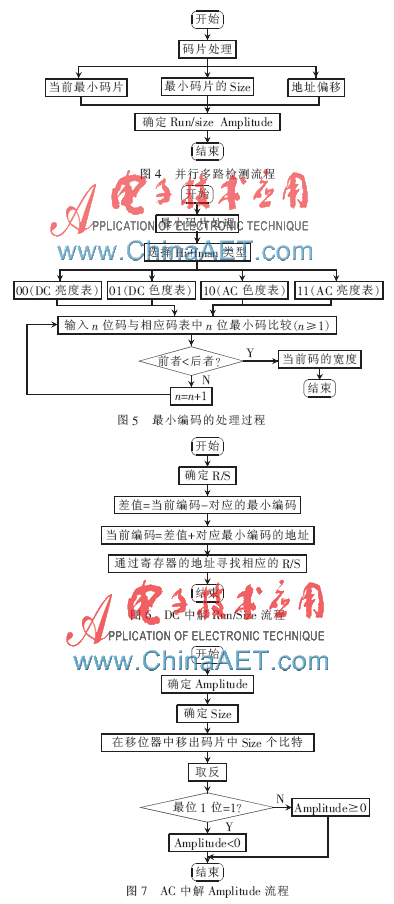
关于解码DC中获得R/S,采用相对地址和绝对地址寻址,即当前最小编码的地址=基本最小编码地址+相对地址(差值)。对不同的4种码表,第一个编码的基本地址都是固定的,由于DC中个数最大值为126,而AC中个数最大值为162。因此将第一个亮度DC地址设为0,第一个亮度AC地址的设为12;第一个色度DC地址设为114,第一个色度AC地址为156。对于不同长度编码同一分量的最小地址,直接采用该分量第一个编码地址与小于该长度编码个数的和。从待解码数据流的输入到确定R/S、Amplitude,都采用并行多路检测的方法。与串行解码方式相比大大提高了码流的解码速度。
在并行Huffman解码结构中,处理了几位编码后,补上相应个数的新的待解编码,补充的位数是由Size和Amplitude值决定的。由于每次解码码长的不确定性,本文采用桶型移位寄存器,但是会占有一定的面积资源。因为每次移位的位数也是不确定的,所以必须要考虑移位溢出的情况。设计中选用32位移位寄存器和16位桶型移位寄存器,前者相当于一个缓存器,其[15:0]的后半段寄存器进行解码操作,[31:16]后半段寄存器存入桶型移位寄存器中。当最小编码等于16时,Amplitude值从桶型寄存器中移出;若操作编码流长度大于16,需要由32位寄存器对它进行移位补位,[15:0]和[31:16]共同移位。当移位位数超过48时,设计一个累加器向外输出码流输入允许信号,继续输入码流到32位寄存器中。此外,输入解码器数据位宽在0~32范围内变化,实际输入的待解码数据位宽将取决于该编码数据在Huffman编码树中的位置。
3 Huffman并行解码的实现
将Run、Size及Amplitude值存入相应的寄存器后,为JPEG后续的解码做准备。同时也就完成了一次Huffman并行解码,所有的解码处理过程都是同步进行的。经过验证,Huffman并行解码处理过程是在一个时钟周期内实现解一个编码。由于FPGA实现,需采用很多组合逻辑,因此关键路径的延时必须考虑在内[8-9]。同时该硬件实现中也用到了许多存储器,所以会占有一定FPGA的面积资源,与串行解码相比,在速度上和输出的稳定性上有一定的优势。其中具体环节的硬件实现框架如图8所示。
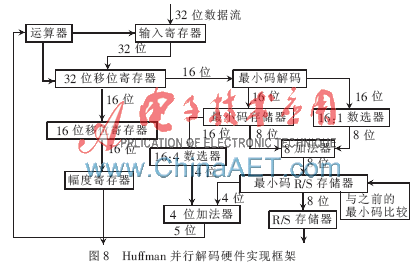
图8中各模块的性能为:
(1)16位最小码存储器。存放的是DC和AC的最小编码。
(2)16位最小码解码模块。输入的16位待解码流与最小编码进行比较,找到相同长度的最小编码,输出Huffman最小编码到R/S存储器,输出与相应最小编码同等长度的实际码子到数选器[10]。
(3)16:1数选器。差值=实际编码长度-最小编码长度。
(4)16位最小码存储器。预存的最小编码地址,16×8的寄存器。
(5)8位加法器。最小编码的地址+差值=实际编码的地址。
(6)最小码R/S存储器。预存R/S和所有与Huffman相对应的值在256×8的寄存器中,最终解码解出相应的R/S。
(7)16:4数选器。把16位编码的长度换成4位表示。
(8)4位加法器。最小编码的长度+差值Size=解码时一共处理的位数,即需要补入数据流的位数。
(9)运算器。累加器是将移位的总位数进行相加,并向移位器提供当前移位位数。当总数≥16时,输出输入数据允许信号,请求前置模块输入数据,在输入允许信号有效时,刷新运算器的值;当总数≥32时,输入允许信号仍未有效,则终止后续的操作。
(10)32移位寄存器。对输入数据进行存储和移位。
(11)16移位寄存器。移出幅度的值,选用桶型移位寄存器的原因是当移出位数>16时也可以处理。
与串行解码相比,Huffman并行解码算法的优点是在一个时钟周期内,无论Huffman编码的长度是多少,都可以正确解出编码信息。数据处理速度的提高,显然会伴随硬件FPGA设计的复杂度的增加。本文采用并行处理技术给出了Huffman解码算法,实现了Huffman并行解码器的设计。不但能够在一个时钟节拍内处理多比特数据,而且节省了存储空间,克服了Huffman串行解码实时性差的不足。显然,本算法的实现是在提高处理数据速度的同时,增加了FPGA硬件的面积资源。
参考文献
[1] 宋奇刚,魏小义.霍夫曼解码器的设计及在MP3解码中的应用[J].今日电子,2005(3):10-12.
[2] 李晓飞.Huffman编解码及其快速算法研究[J].现在电子技术,2009(21):102-108.
[3] 陈亚光,陈少平,朱翠涛,等.并行Huffman解码器算法分析[J].计算机测量与控制,2002,10(6):418-420.
[4] 雒莎,葛海波.基于查找表的自适应Huffman编码算法[J].西安邮电学院报,2011,16(5):76-79.
[5] 杨浪花,张涛,于凤萍,等.MP3/AAC解码器中Huffman硬件加速器设计与实现[J].电声技术,2010(6):55-59.
[6] 陈佳昕,林涛.一种优化了的并行Huffman解码器[J].有线电视技术,2007(8):47-50.
[7] 方婵婵,叶兵,吴彪,等.Huffman并行解码结构及硬件实现[J].合肥工业大学学报,2007,30(7):855-857.
[8] 傅祖芸.信息论基础理论与应用[M].北京:电子工业出版社,2001.
[9] 马建国,孟宪元.FPGA现代数字系统设计(第1版)[M].北京:清华大学出版社,2010.
[10] PALNITKAR S.Verilog HDL数字设计与综合(第2版)[M].夏宇闻,胡燕祥,刁岚松,等译.北京:电子工业出版社,2009.