
摘 要: 阐述了一种基于应用性能表现的通用基础软件选型的方法。介绍了基于应用系统性能为基准,对数据库和应用中间件进行选型比对。
关键词: 应用系统;数据库;应用中间件;选型
传统的数据库选型和应用中间件选型测试通常是基于Benchmark的一些基准测试工具。这些测试工具集通常都是第三方非盈利组织提供的,目前常用的基准测试工具集有TPC[1]、SPEC[2]、LINKPACK、EISPACK、LAPACK、NPB、HPCC、IOzone、LMbench等。
TPC和SPEC是数据库和应用中间件最常用的测试基准工具,而其中的TPC-C[3]和SPECjserver2004[4]通常被选择用于数据库和Java应用服务器的性能基准测试工具,这两个基准测试结果在国际上也有很好的认同。这些结果能客观反映数据库和应用中间件本身的性能情况。
但是上述基准测试都是基于仿真业务,对于某个特定的应用系统,基准结果往往和在特定应用系统中的表现有很大差异。所以本文探求一种基于真实业务应用系统的业务模型作为基准,对不同数据库和应用中间件进行选型测试,通过其在真实业务应用系统的表现更客观地反映针对该特定应用系统、数据库和应用中间件达到的最佳能效比。
1 传统Benchmark测试的问题
传统的基于第三方非盈利机构的Benchmark测试工具集测试是基于一个模拟的业务模型进行测试。以最常见的TPC-C测试为例,关于TPC-C的基准规范业务模式,此规范描述的是一个大型的商品批发销售公司,它拥有若干个分布在不同区域的商品仓库。当业务扩展的时候,公司将添加新的仓库。每个仓库负责为10个销售点供货,其中每个销售点为3 000个客户提供服务。每个客户提交的订单中,平均每个订单有10项产品,所有订单中约1%的产品在其直接所属的仓库中没有存货,必须由其他区域的仓库来供货。同时,每个仓库都要维护公司销售的100 000种商品的库存记录。但是对于这个基准,TPC不给出基准程序的代码,只给出基准程序的标准规范。即允许任何厂家或其他测试者构造出符合自己硬件或者软件环境的被测应用,这个被测试的应用只要符合这个规范就可以。
TPC-C测试的结果主要有两个指标,即流量指标(Throughput,简称tpmC)和性价比(Price/Performance,简称Price/tpmC)。流量指标值越大,说明系统的联机事务处理能力越高。性价比测试系统的整体价格与流量指标的比值,在获得相同的tpmC值的情况下,价格越低越好。
TPC-C的指标仅表明当前被测试环境作为一个有机整体,处理符合TPC-C规范、模拟OLTP的商品批发销售公司应用的性能情况。不能离开这个整体去判读TPC-C数据。这个有机整体包含硬件系统,如主机设备、网络设备、存储设备;软件系统如数据库、应用软件、厂商自己开发的TPC-C模型;以及技术支持服务,如架构设计优化、程序优化、参数优化等。
用户实际的应用系统通常与软件厂商测试时的TPCC模型有差异(如业务逻辑、使用习惯、数据量等等方面)。所以客户应用系统的性能即使部署在厂商当时测试TPCC应用的环境上,TPPC值也会有差异的。
因此仅靠TPCC值进行软件选型是不充分、不全面的。
2 基于真实应用系统的选型测试
传统基于Benchmark测试结果的选型测试,由于测试模型和真实业务有区别,选型测试的结果往往不能保证所选数据库或者中间件的表现与测试结果相符。业务模型的差异因子是结果偏差的主要影响因子。区别于传统的Benchmark测试,基于真实应用系统的选型测试模型是真实的业务模型,从业务模型的真实性上避免了业务模型差异产生的比对选型误差。该方法的思想是在相同的测试基准下,针对相同的业务应用模型,进行相同测试的性能测试,通过时间特性和资源利用性两个方面进行选型评价。
3 选型测试案例说明
通过一个实际的业务系统选型测试,介绍了基于应用性能表现进行通用基础软件选型的实践。选型委托方是某机构的核心业务软件,该系统完全基于J2EE规范开发的B/S架构的应用系统,数据库符合美国国家标准学会(ANSI)SQL 2003的关系型数据库。根据上述基本要求,本次选型测试涉及5个中间件和4种数据库。选型组合矩阵关系如表1所示。

根据上述组合,分别采用相同的性能测试脚本进行相同场景设置的综合场景测试,测试点包含了系统的4个典型操作功能点,场景持续运行时间为2 h。为严格保证测试的基准一致性,确保测试相对公平公正,基准一致性应包含5个部分内容要求:
(1)操作系统基准一致性要求:数据库服务器操作系统为AIX 5.3.0.8,应用数据库服务器操作系统为Redhat AS 5.4 64 bit kernel2.6.1.8_164.el5,负载均衡服务器操作系统为Redhat AS 5.4 64 bit kernel2.6.1.8_164.el5;
(2)其他相关软件版本一致;
(3)硬件环境一致;
(4)测试策略与测试压力的一致性:测试中执行相同的测试策略,对脚本和场景运行的设置保持一致;
(5)数据一致性要求:测试环境的数据容量保持一致,数据库的数据记录数量和数据内容保持一致。
3.1 效率评价模型说明
以贴近系统实际使用情况为选择依据,本次测试的综合场景测试最贴近用户的真实使用情况。所以本评价模型的数据基础来源于综合场景测试的测试结果数据。评价模型包括时间特性和资源利用性,具体计算权值可以根据业务需要进行相应调整,本次评价权值仅供参考。评价模型说明如图1所示,评分说明如表2所示。

(1)效率评价总得分=时间特性总得分×0.6+资料利用性得分×0.4
(2)时间特性总体得分计算说明:
时间特性得分=(功能点1×0.125+功能点2×0.125+功能点3×0.125+功能点4×0.125)+总体吞吐量得分×0.5
(3)资源利用性得分计算说明:
资源利用性得分=(数据库CPU占用得分+应用服务器CPU占用得分)/2
3.2 选型评价结果
根据8个环境测试的详细结果,依据上述评价模型和评分说明进行总体的选型评价,得分如图2所示。
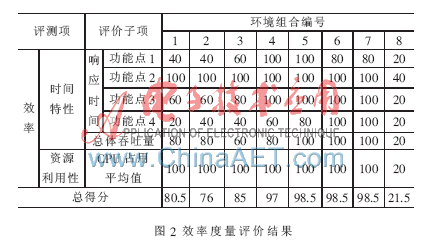
依据上述评价结果,编号4、5、6、7的得分高于95分,可以结合采购成本综合考虑最终的软件选型。
本文介绍了一种基于应用性能表现的通用基础软件选型方法,此方法基于真实的业务应用模型,采用相同的测试约束和统一的评价模型,相对于传统基于基准测试工具进行选型更具有针对性,是对选型测试的一种方法补充。
参考文献
[1] TPC Benchmark Testing[EB/OL]. [2012-12-10]. http://www.tpc.org/information/benchmarks.asp.
[2] SPEC Standard Performance Evaluation[EB/OL]. [2012-12-10]. http://www.spec.org.
[3] TPC-C Benchmark Testing[EB/OL]. [2012-12-20].http://www.tpc.org/tpcc.
[4] SPECjAppServer2004[EB/OL]. [2012-12-20].http://www.spec.org/jAppServer2004.