
摘 要: 随着互联网的发展,各种类型的应用层出不穷,网站访问量越来越大、内容越来越多,用户与系统的交互不断增强,访问集中,造成数据库负载过大,网站显示延迟等影响。缓存技术就是解决此问题的一种方案,缓存技术以其简单的设计、高效的存储性能得到了越来越广泛的应用,而内存数据库则是一种优秀的缓存解决方案。主要介绍Redis的特性以及在系统中的应用。
关键词: Redis; 高速缓存; 内存数据库
随着 Internet 技术的快速发展,网络接入速度不断提高,各种类型的应用层出不穷,网站访问量越来越大、内容越来越多,用户交互不断增强,访问集中,造成数据库负载过大、网站显示延迟等影响,而造成影响用户体验的主要瓶颈集中在数据库服务器承载能力方面。要让数据库服务器快速响应并能够承受越来越大的负载, 缓存技术就是解决此问题的一种方案。Cache性能高效,设计简单,可以对数据库中的数据进行缓存,降低数据库负载;可以对Web页面进行缓存,提高Web页面响应速度;对复杂计算结果进行缓存,可以减少网站服务器的传输负荷和计算速度和对用户的响应速度,有效地提高网站性能及可扩展性。本文主要介绍开源内存数据Redis的特性及其应用。
1 Redis简介
Redis是一种 Key-Value类型的内存数据库产品,全名为远程字典服务(REmote DIctionary Server),与Memcache 相似,但Redis 支持更多的数据类型,包括字符串(String)、链表(List)、集合(set)、有序集合(Zset)、哈希(Hash)等。与Memcached一样,为了保证效率,Redis数据都是缓存在内存中,但与Memcache 只是用来做缓存相比,Redis适用的场景更多,并且可以直接用于数据存储服务。
2 Redis特性
虽然Redis与Memcaehed具有很多相似的特征,可替代Memcaehed做为缓存,但它又具有更多优秀的特性,如支持多种数据结构、支持简单事务控制、支持持久化、支持主从复制、Virtual Memory功能等。
2.1 Redis数据类型
Redis除了提供常规的数值或字符串外还提供4种数据类型:List、Set、Zset(Sorted Set)和Hset(Hash Set)。
(1)String(字符串)
Strings数据结构是简单的Key-Value类型,Value其实不仅是String,也可以是数字。使用Strings类型,可以完全实现目前 Memcached 的功能,并且效率更高;还可以享受Redis的定时持久化、操作日志及Replication等功能。
(2)List(双向链表)
Lists就是链表,使用Lists结构可以轻松地实现最新消息排行等功能。Lists的另一个应用就是消息队列,可以利用Lists的PUSH操作将任务存在Lists中,随后工作线程再用POP操作将任务取出进行执行。Redis还提供了操作Lists中某一段的API,可以直接查询、删除Lists中某一段的元素。
(3)Set(集合)
Sets是一个集合,集合的概念就是一堆不重复值的组合。Set是String类型的无序集合。Redis还为集合提供了求交集、并集、差集等操作,可以非常方便地实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
(4)Zset(有序集合)
Zset与Set相似,但在Set的基础上增加了一个Score的属性。这一属性在添加修改元素时进行指定,每次指定后,Zset会自动按新的值重新调整顺序。
(5)Hash(hash表)
在Memcached中,经常将一些结构化的信息打包成hashmap,在客户端序列化后存储为一个字符串的值,比如用户的昵称、年龄、性别、积分等,在需要修改其中某一项时,通常需要将所有值取出反序列化后,修改某一项的值,再序列化存储回去。这样不仅增大了开销,也不适用于一些可能并发操作的场合(比如两个并发的操作都需要修改积分)。而Redis的Hash结构可以实现像在数据库中Update一个属性一样只修改某一项属性值。
2.2 Redis事务控制
Redis可以通过MULTI/EXEC来支持简单的事物控制。Redis只能保证事务中的所有命令串行执行,在事务的执行过程中不会为其他客户端发起的请求提供服务。当一个client使用multi命令时,这个连接会进入一个事务上下文,该连接后续的命令会放在一个队列中,当此连接收到exec命令后,Redis会顺序地执行队列中的所有命令,但是如果事务中的一个命令失败了,并不回滚其他命令。
2.3 Redis持久化机制
Redis是一个能支持持久化的内存数据库,它通过将内存中的数据保存到磁盘来持久化。Redis有两种持久化方式,一种是Snapshotting(快照),另一种是append-only file(缩写aof)的方式。下面分别介绍:
(1)Snapshotting方式
快照是默认的持久化方式。这种方式是将内存中数据以快照的方式写入到二进制文件dump.rdb中。可以通过配置redis.conf来设置自动做快照持久化的方式。
(2)aof方式
如果对数据要求很高,可以采用aof持久化方式。因为在使用aof持久化时,Redis会将每个命令都追加到appendonly.aof文件中,当Redis出现意外关闭后,重启后会通过执行appendonly.aof文件中的命令来在内存中重建整个数据[1]。
2.4 主从复制
Redis主从复制配置非常简单,可以通过配置redis.conf文件中的Replication段来实现主从复制。 Redis主从复制特点:
(1)支持一个master可以拥有多个slave,同时slave还可以接收其他的slave。
(2)主从复制不会阻塞master和slave,在同步数据时,master和slaver都可以接收client请求。
通过主从复制的特性可以做到以下3个方面:
(1)可以做到读写分离,提供系统伸缩性和系统性能,如master主服务用来写数据,slave服务用来读数据。
(2)可以做到备份数据分离,如slave服务器群中的一个或两个服务器用来备份数据。
(3)虽然Redis宣称主从复制无阻塞,但是由于Redis使用单线程服务,而与slave的同步是由线程统一处理,因此,对性能有影响。在slave第一次与master做同步时,如果master快照文件较大,相应快照文件的传输将耗费较长时间,文件传输过程中master会造成访问延迟。
2.5 Virtual Memory 功能
Redis的Virtual Memory(虚拟内存)通过配置可以让用户设置最大使用内存,当超出这个内存时,通过LRU类似算法,将一部分数据存入文件中,在内存中只保存使用频率高的数据来提高Redis性能。
3 Redis应用分析
通过上述Redis 的特征分析,可以看到当作Cache工具时,Redis与其他Cache相比更多的优势性能和内存使用效率相差无几却拥有更多的数据结构并支持更丰富的数据操作,同时还支持持久化。例如在某博客系统中,整个系统结构图如图1所示,客户端通过Redis proxy访问Redis。目前的Redis本身都不具备分布式集群特性,当有大量 Redis时,通常只能通过客户端的一些数据分配算法(比如一致性哈希)来实现集群存储。而 Twemproxy 通过引入一个代理层,可以将其后端的多台 Redis实例进行统一管理与分配,使应用程序只需要在 Twemproxy 上进行操作,而不用关心后面具体有多少个真实的 Redis存储,这样就可以通过平行扩展Redis Master服务器来无限扩展Redis。
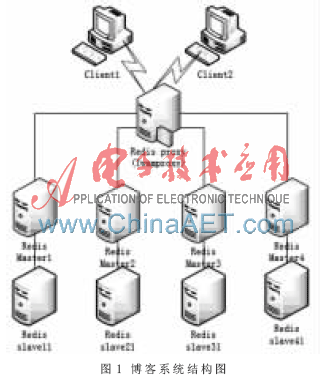
Redis-Master1与Redis-slave11通过主从复制连接。同时,Redis-Slaver11通过aof负责持久化。Twemproxy可以配置结点故障问题,当某一个结点出现故障后,用Redis Master相应的Redis Slave切换成Master。
在系统运行中要处理各种业务逻辑,因而需要访问大量的数据库资源,在数据库上进行读写操作,数据库压力会较大,性能较低。通常把更新不频繁的数据进行缓存。例如下面几种操作。
(1)根据条件得到最新数据的操作,以时间为权重
比较典型的取最新博文的数据代码如图2所示。可以将最新的5 000条博客的ID放在Redis的双向链表(list)集合中,使用LPUSH globle:blogpostids命令向双向链表(list)集合中插入数据,插入完成后再用LTRIM global.latest.blogs 0 5000命令使其永远只保存最近5 000个ID,然后在客户端获取最新博文时可以用下面的逻辑(伪代码)了。如果还有其他的取最新数据需求,比如“模拟技术”分类的最新50条数据,则可以再建一个按此分类的双向链表(list),将博文的ID插入此双向链表(list)中。

(2)根据条件得到排行榜应用,相当于数据中取TOP N操作,例如访问量最高的博文、用户的相互关注等。
以某个条件为权重得到数据,如果博文按浏览的次数排序,这时可以使用sorted set将浏览次数值设置成sorted set的score,将具体的博文ID设置成相应的value,每次新增博文时只需要执行一条ZADD blog:getblogpostrank 0 1000,每当博文被浏览时,使用ZINCRBY blog:getblogpostrank 1 1000,取访问量最高的博文时就可以使用ZREVRANGE blog:getblogpostrank 0 -1,来按照浏览次数高低排行了。
(3)网站计数的应用,比如在博客系统中浏览次数、评论数等。
Redis的命令都是原子性的,可以使用INCRBY、ZINCRBY命令来增加计数,使用DECRBY、ZINCRBY命令来减少计数。如果给博文ID号为1 000的增加一次浏览,则使用INCRBY blogpost:1000 1命令。
(4)构建反垃圾信息(spam)系统,比如评论系统中的反垃圾信息等。
在博客系统中评论是必不可少的,同时各种攻击spam也少不了(如垃圾评论、广告、刷排名等),可以针对这些spam制定一个规则,例如一分钟评论不得超过2次,5分钟不能评论多于5次。这可以使用Redis的Sorted Set来将最近一天用户操作记起来。使用系统时间为score,这样执行一条ZADD user:1000:operation 54561227854“发表评论”,得到用户最近一分钟的操作如下ZRANGEBYSCORE user:1000: operation 54561227854 +inf。这样如果一分钟有两次评论,就可以判定为spam(每个网站的规则不一样)。
(5)可以使用Redis系统中Pub/Sub和Ajax长链接来构建实时消息系统。
Redis的Pub/Sub系统作为一种消息通信模式,类似于设计模式中的观察者模式,发布和订阅机制可以很方便地实现简单的聊天功能,可以应用于实时聊天(通过与Ajax长链接)、异步消息处理(如注册后给用户邮件通知)等场景。将不同的频道分布到不同服务器上,也可以很方便地实现服务器的扩展以应对用户量的增长。
(6)使用List或者Zset构建队列系统。
可以使用List构建队列系统,加入队列可以使用rpush global:queue addblogpost,退出队列使用lpop global:queue。使用Zset来构建有优先级的队列系统,加入普通级别的列队命令zadd global:zqueue 1 addblogpost,加入高优先级的列队可以通过提高score的值来提高优先级。
为了高速缓存在系统应用的不同需求,对Redis 的主要特征进行了分析,同时对其作为缓存解决方案的应用进行了举列说明。随着Redis的发展,官方roadmap在Redis 3版本中将加入集群功能,Redis作为内存数据库,可以通过水平扩展来延伸系统的物理内存,同时又支持持久化,完全可以将所有数据存放在Redis内存数据库中,这样才能充分发挥内存数据库的优势。
参考文献
[1] Xhan.redis学习笔记之持久化[EP/OL].[2011-02-07](2013-03-15).http://www.cnblogs.com/xhan/archive/
2011/02/07/1949640.html.