
摘 要: 通过研究各种决策树分类算法的并行方案后,并行设计C4.5算法。同时根据Hadoop云平台的MapReduce编程模型,详细描述C4.5并行算法在MapReduce编程模型下的实现及其执行流程。最后,对输入的海量文本数据进行分类,验证了算法的高效性和扩展性。
关键词: 云计算;Hadoop;MapReduce;数据分类;C4.5算法;并行
随着信息技术的高速发展,人们积累的数据量急剧增长,如何从海量数据中提取有用的知识成为当务之急。数据挖掘应运而生,它是一个从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的人们事先不知道的但又是潜在有用的信息和知识的过程[1]。然而随着数据量的增加,数据挖掘处理海量数据的能力成为了不可忽视的问题。
云计算是解决这个问题的有效途径,它把大量高度虚拟化的资源管理起来,组成一个大的资源池,用来统一提供服务。云计算是最近几年出现的一门新兴技术,是并行计算、分布式计算、网格计算的发展[2],具有广泛的应用前景。IBM、Google、微软等众多公司都很重视云计算技术,都快速推出了自己的云计算平台。目前比较热门的开源云计算平台有:Abiquo公司的abiCloud、Amazon公司的Eucalyptus、MongoDB、Enomalism、Nimbus、Hadoop。其中Hadoop平台是完全模仿Google体系架构做的一个开源项目,是现在应用最广、最成熟的平台。
决策树分类算法作为一个经典的数据挖掘方法,通过对大量数据的属性值进行分析,构造决策树,来发现数据中蕴涵的分类规则。然而,在数据增长大爆炸的时代,这些算法处理海量数据的性能总有些差强人意。云计算作为一个处理海量数据的良好途径,将算法布置在云计算平台中进行分布式计算是一个行之有效的方法。
本文采用Hadoop开源云平台,对数据集进行数据横向和纵向划分,分布到不同的节点对不同的属性进行并行处理,对海量文本数据进行分类。
1 Hadoop开源云平台
Hadoop是Apache软件基金会旗下的一个开源分布式平台,以Hadoop分布式文件系统HDFS和MapReduce(Google MapReduce的开源实现)为核心,为用户提供了系统底层细节透明的分布式基础架构[3]。HDFS的高容错性、高伸缩性等优点允许用户将Hadoop部署在低廉的硬件上,MapReduce分布式编程模型允许用户在不了解分布式系统底层细节的情况下开发并行应用程序。因此用户可以充分利用集群的计算和存储能力,完成海量数据的处理。
1.1 分布式文件系统HDFS
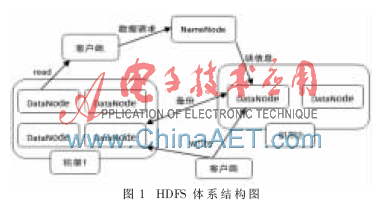
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群由一个NameNode和若干个DataNode组成。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。HDFS允许用户以文件形式存储数据。从内部来看,文件被分成若干个数据块,而且这若干个数据块存放在一组DataNode上[3]。NameNode执行文件系统的命名空间操作,如打开、关闭、重命名文件或目录等,也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建、删除和复制工作。图1所示为HDFS的体系结构。
1.2 并行编程框架MapReduce
Hadoop上的并行应用程序开发基于MapReduce编程框架,框架由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成。它的原理是:利用一个输入的key/value对集合来产生一个输出的key/value对集合。用户用Map和Reduce两个函数来表达计算[3]。
用户自定义的Map函数接收一个输入的key/value对,然后产生一个中间key/value对的集合。MapReduce把所有具有相同key值的value集合在一起,然后传递给Reduce函数。自定义的Reduce函数接收key和相关的value集合,合并这些value值,形成一个较小的value集合。
图2为MapReduce的数据流图,这个过程简而言之就是将大数据集分集为成百上千个小数据集,每个或若干个小数据集分别由集群中的一个节点进行处理并生成中间结果,然后这些中间结果又由大量的节点合并,形成最终结果。此框架下并行程序中需要3个主要函数:Map、Reduce、Main。在这个结构中,需要用户完成的工作仅仅是根据任务编写Map和Reduce两个函数。

2 C4.5决策树分类算法
在决策树分类算法中,最常用、最经典的是C4.5算法,它继承了ID3算法的优点并对ID3算法进行了改进和补充。此算法描述如下[4]:
(1)预处理样本数据集。若存在连续取值的属性变量,则将其进行离散化,形成决策树的训练集;若不存在则忽略此步。
①根据原始数据,分别找到该连续型属性的最小取值a0和最大取值an+1;
②在区间[a0,an+1]内插入n个数值,将其等分为n+1个小区间;
③分别以ai(i=1,2,…,n)为分段点,将区间[a0,an+1]划分为两个子区间:[a0,ai],[ai+1,an+1],对应该连续型属性变量的两类取值,有n种划分方式。
(2)计算每个属性的信息增益和信息增益率。
①计算属性A的信息增益Gain(A);
②计算属性A的信息增益率GainRatio(A)。对于取值连续的属性,以ai(i=1,2,…,n)为分割点计算相应分类的信息增益率,选择最大信息增益率对应的ai作为该属性分类的分割点。而后选择信息增益率最大的属性作为当前的属性节点,得到决策树的根节点。
(3)根节点属性的每一个取值对应一个子集,对样本子集递归执行步骤(2),直到划分的每个子集中的数据在分类属性上取值都相同,或者没有剩余属性可以进一步划分数据,或者给定的分支中没有数据,便停止划分,生成决策树。
(4)根据生成的决策树提取分类规则,对新的数据集进行分类。
3 C4.5算法并行化
本文结合数据横向和纵向划分方法,以提高并行效率。具体设计思想如下:
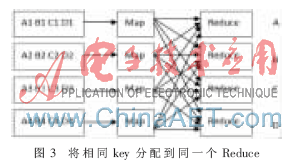
Map阶段:主要任务是处理输入的1/M训练样本集,扫描每条记录,将其格式化为<key,value>对。具体格式为key=属性S,value=<对应属性S的值s,所属类别c,原表中此记录的id>。格式化后即可进行Map操作,每个Map任务为划分归类具有相同key的键值对,写到相应文件,由partition用模计算将各个文件分配到指定的Reduce上,即将相同的key分配到同一个Reduce节点上,如图3所示。
Reduce阶段:主要任务是处理Map输出的<key,value>键值对。对于具有连续值的属性,先从小到大排序属性值,生成直方图,用来记录该属性对应记录的类分布,初始化为0,每个Reduce任务都计算分割点的信息增益率,并及时更新直方图。对于离散的属性,不需要排序,也无需更新直方图,第一次扫描数据Map的输出记录时,生成相对应的直方图,计算各子节点的信息增益率。每个Reduce节点都将计算得到各自属性列的信息增益率和分裂点,根据分裂点分割属性列表,用列表的索引号生成记录所在节点的哈希表,存储分裂点两侧的数据记录。哈希表格式为<key,value>键值对,value=<树节点号NodeID,当前树节点号的子节点号SubNodeID>,其中SubNodeID为0表示左节点,1表示右节点。哈希表中的第N条记录表示原数据中第N条记录所划分到的树节点号。最后根据哈希表各分节点对其他属性列表进行分割,并生成属性直方图。
主程序算法设计描述如下:
Main()
{
输入训练样本集T;
生成有序的属性列表A和直方图G;
创建节点队列Q,首节点N为训练样本集所有数据
记录;
while(队列不为空)
{
取出队列首节点;
while(节点数据样本不属于同一类&&还有属性
可操作&&样本数据不是太少)
{
将节点中的训练样本集进行水平划分,分割为
M份,由InputFormat完成,将数据划分为InputSplit发
送到各个Map节点进行处理,这里同时也进行垂直
分割;
Map操作;
Reduce操作,以Map节点的输出中间结果作为
输入;
根据各个Reduce节点返回的输出结果,选择最
大信息增益的属性,以其分裂点和哈希表分裂原始数
据集,生成子节点N1和N2,放入队列Q;
}
}
}
例如,以ALLElectronic顾客数据为训练集,Hadoop默认参数进行分片,其中水平和垂直分割过程如图4所示。
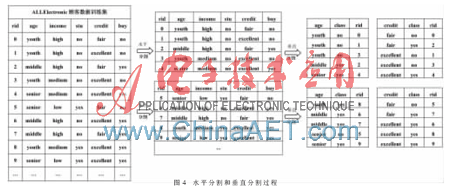
对ALLElectronic顾客数据集进行分类,顾客数据集的属性分别为ID、年龄、收入水平、学生身份标志、信用卡水平。根据这些属性对顾客消费潜力进行评估,将顾客分为会消费顾客和不会消费顾客,训练产生的决策树模型如图5所示,用此模型对数据进行分类。

4 实验
本实验主要验证算法的高效性和扩展性。实验数据为UCI数据集Bank Marketing,用来预测用户是否会定期存款。该数据集属于商业领域,具有多变量的特征,包括客户的年龄、工作、婚姻情况、学历、年均收入、房贷、支出等17个属性,而且是实数,有45 211个元组,没有缺省值,经常用来完成分类的任务。
实验环境:软件方面:采用Hadoop-0.20.2版本,Ubuntu Linux 9.04系统,Eclipse3.3.2开发工具,Jdk 7.0;(上接第87页)
硬件方面:7台PC(其中1台作为主机,其他6台作为从机),每台PC的配置为:CPU i3,内存1 GB,网卡100 Mb/s。
实验内容:采用复制的手段将Bank Marketing扩大,产生分别为100 MB、200 MB、400 MB、700 MB、1 GB大小的数据集。测试各个数据集在不同数量的集群中算法的运行时间,从机集群数量分别设为1、2、4、6台。运行结果统计如图6所示。

数据的处理时间主要花费在数据的分割和记录的格式化过程,由图6可见,随着集群数量的增大,处理时间有效地缩短了。具体原因分析如下:MapReduce对数据的分割一般以64 MB为一基本单位。例如,700 MB大小的数据可分割为11个数据块,如果用1台机器去处理,需要计算11次;用2台处理,需要计算6次;4台处理则只要计算3次;6台则只要计算2次。因此可以得出此算法有很高的高效性和扩展性。
决策树分类算法有广泛的应用领域,如客户关系管理、专家系统、语音识别、模式识别等。C4.5并行化决策树分类算法与传统决策树分类算法相比,有较大优势,可以支持海量数据的处理。同时将其运行在Hadoop云计算平台上,能够高效地对大规模海量数据进行分类。
参考文献
[1] 房祥飞.基于决策树的分类算法的并行化研究及应用[D]. 济南:山东师范大学,2007.
[2] 刘鹏.云计算[M].北京:电子工业出版社,2010.
[3] 陆嘉恒.Hadoop实战[M].北京:机械工业出版社,2011.
[4] 田金兰,赵庆玉.并行决策树算法的研究[J].计算机工程与应用,2001,16(5):17-20.