
摘 要: 克隆代码会导致项目的维护困难,削弱项目的健壮性,并且克隆代码中所包含的bug会破坏整个项目。当前克隆代码检测技术或者拘泥于只能检测少数几种克隆代码,或者需要极高的检测时间。而且如果需要检测大量的源代码,一台机器的主存也许无法存储所有的信息。对克隆代码检测技术的并行运行进行了可能性研究,使用基于程序依赖图的克隆代码检测技术,这种技术不仅可以检测出语法上的克隆,也可以检测出语义上的克隆,提出了一个并行子图同构检测方法并使用MapReduce并行实现,实验结果极大地提高了该方法的运行速度。
关键词: 克隆代码;程序依赖图;同构匹配检测;Hadoop
在软件项目的开发过程中,由于能够降低开发者的工作量,“复制粘贴”也许是最常使用的操作。但这也带来了克隆代码的问题。
克隆代码的存在给软件维护带来了困难,当开发者试图修改代码时,他们很可能修改了克隆代码中的一处而忘记了别的地方,这显然会带来代码的不一致。为了避免这个难题,大量的克隆代码检测技术被提出。但问题在于克隆代码的精确定义本身就不明确,现有的每一种方法都有其对于克隆代码自己的定义。因此,同样的源代码,如果用不同的克隆代码检测方法检测,可能会得到完全不同的结果。
基于程序依赖图的方法能够探测语义克隆代码,而且它还具有一个其他方法所不具有的能力:能够探测非连续性的克隆代码[1]。非连续性的克隆代码是被其他代码或文件所分割开来的克隆代码,克隆代码中的代码并不是连续的。而开发者往往会在粘贴克隆代码后做一些修改,这样,基于程序依赖图的检测方法就能够检测出这种克隆代码。
但是基于程序依赖图的方法有一个很大的缺点,即运行非常缓慢。程序依赖图的同构检测是著名的图同构匹配问题,该问题为NP完全问题,需要指数级的时间复杂度,这导致了运行时间呈指数级增长。
本文提出了一种并行执行程序依赖图同构匹配的方法。通过使用这种方法,减少了这一特定问题的图同构匹配算法所需要的时间。并使用MapReduce这一流行的并行框架来并行该方法。
1 背景知识
1.1 程序依赖图
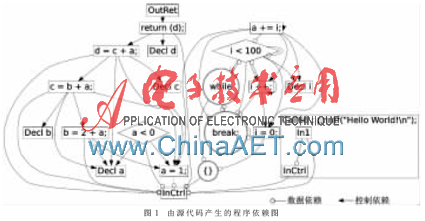
程序依赖图是一个有向图,该图的顶点代表了源代码中的代码,而边代表了两个顶点之间的依赖。在程序依赖图中只有两种边:代表控制依赖的边和代表数据依赖的边。以下展示了一个源代码的例子,图1为该源代码所产生的程序依赖图。
#include <stdio.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#define BUFFER_SIZE 1024
#define DELIM "\t"
int main(int argc, char *argv[]){
char strLastKey[BUFFER_SIZE];
char strLine[BUFFER_SIZE];
int count = 0;
*strLastKey = '\0';
*strLine = '\0';
while( fgets(strLine, BUFFER_SIZE - 1, stdin) ){
char *strCurrKey = NULL;
char *strCurrNum = NULL;
strCurrKey = strtok(strLine, DELIM);
strCurrNum = strtok(NULL, DELIM);
/* necessary to check error but.... */
if( strLastKey[0] == '\0'){
strcpy(strLastKey, strCurrKey);
}
if(strcmp(strCurrKey, strLastKey)){
printf("%s\t%d\n", strLastKey, count);
count = atoi(strCurrNum);
}else{
count += atoi(strCurrNum);
}
strcpy(strLastKey, strCurrKey);
}
printf("%s\t%d\n", strLastKey, count);
/* flush the count */
return 0;
}
1.2 MapReduce
MapReduce[2]是一个流行的编程模型,该模型能够通过一个运行在集群上的并行的、分布式的算法对大数据集进行处理。它提供了一个简单易用的并行算法编程框架,使用该框架的开发者只需要定义两个函数:Map和Reduce。原始数据被该框架转换成键值对,每一个Map进程每一次处理一个键值对(key,value):
Map: <k1, v1> → <k2, v2>
Map函数在集群中并行执行,MapReduce框架将所有相同的key的键值对传递给一个Reduce函数。Reduce函数产生最终的结果:
Reduce: <k2,v2> → <k3,v3>
2 程序设计算法
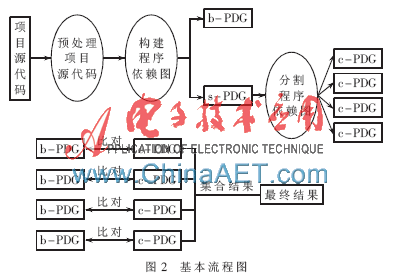
首先把源代码转换成以静态形式表示数据流和控制流的程序依赖图,将其记为s-PDG。程序依赖图的节点代表了源代码中的语句(声明、赋值、表达式、控制逻辑等),同时记录所有节点对应源代码的类别以便在后面的比对中使用。然后选择一段程序块所对应的s-PDG的子图,作为查找与图同构的样本,将这个子图记为b-PDG。随后对s-PDG和b-PDG进行比对,以检测除了b-PDG本身以外是否还有别的s-PDG的子图与b-PDG同构。如果有,则这个子图所对应的代码就与b-PDG对应的程序块为克隆代码。
经典的算法在检测子图同构时只能顺序执行,本文所要做的是将s-PDG切分成多个小图,然后并行子图同构检测。在论述切分s-PDG的方法之前,先给出会在切分中使用的伪圆的定义。
在图G=(V,E)中,任给A∈V,以A为圆心,以一个正数为半径,对于任意节点B∈V,如果AB之间的最短路径长度(对于边无权值的图,最短路径长度为最短路径所经过的节点的个数)小于半径,则B位于该伪圆中。当计算最短路径时忽略边的方向。
按照参考文献[3]中提出的方法切割s-PDG:
(1)根据s-PDG节点的种类分别计数。
(2)取出s-PDG中数量最少的节点的种类,将其记为种类l。然后选取出b-PDG中属于种类l的节点。如果b-PDG中没有种类l的节点,则变更种类l为s-PDG中第二少种类的节点。如果种类l仍然在b-PDG中没有节点,则继续变更种类l为s-PDG中第三少种类的节点,直到b-PDG中存在种类l的节点。
(3)计算s-PDG中所有这些种类l的节点与其他节点的距离,将最大值定为伪半径。
(4)以上面计算出的伪半径,以s-PDG中种类为l的节点为圆心,可以得到一些伪圆。这些伪圆就是切割s-PDG的最终结果。将它们记为c-PDG的集合。
在查找同构子图的过程中必须检查节点的种类,对应的节点必须有同样的种类。所以同构子图必须有种类为l的节点。考虑到b-PDG的尺寸大小,在s-PDG中的节点如果距步骤(4)中选取的圆心距离过大,则这些节点不可能处于同构子图中,因此可以把这些节点切除不再考虑。
该算法的基本流程如图2所示。
3 算法的实现
使用JavaPDG[4]生成整个项目的程序依赖图。JavaPDG是一个静态的Java字节码分析器。这个工具能够产生各种不同的对源代码的图形展示,例如系统依赖图、程序依赖图、控制流图和函数调用图。
使用Hadoop[5](一个MapReduce框架的开源实现)来并行这个子图集的同构匹配。
使用Igraph[6]来检测子图同构匹配。Igraph是一个针对图的操作的开源软件包,由于Igraph是用C语言写成的,必须通过Hadoop流来将这个软件包用于并行同构检测。
4 实验与评价
通过对两个开源项目的检测来评价本文的算法,结果如表1所示。通过代码行数和对应程序依赖图的节点和边的个数来对比项目的大小。将经典PDG匹配算法与以3台机器组成的集群上并行为例的本文算法所消耗的时间进行了比较。

结果显示,本文算法极大地提高了同构匹配的性能,经典的程序依赖图同构匹配算法需要花费几个小时,而本文并行算法仅仅花费几分钟。这是因为并行算法移除了程序依赖图中的部分节点,而且并行了同构匹配的过程。
本文提出了一种提高基于程序依赖图的克隆代码检测性能的方法。把程序依赖图分割成若干个小图并使用Hadoop并行执行子图同构检测,使得算法的性能得到了提高。使用两个得到广泛使用的开源项目来测试本文算法,测试结果显示该算法显著地提高了克隆代码检测的性能。
参考文献
[1] BELLON S,KOSCHKE R,ANTONIOL G,et al.Comparison and evaluation of clone detection tools[J].IEEE Transactions on Software Engineering,2007,33(9):577-591.
[2] DEAN J,GHEMAWAT S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM, 2008,51(1):107-113.
[3] LI J,ERNST M D.CBCD:cloned buggy code detector[C]. ICSE 34th International Conference on Software Engineering, 2012:310-320.
[4] SHU G,SUN B, HENDERSON T A,et al.JavaPDG:a new platform for program dependence analysis[C].In Proceedings of the 6th IEEE International Conference on Software Testing,Verification and Validation, Testing Tools Track,Luxembourg,2013:18-22.
[5] Hadoop.The apache software foundation[EB/OL].[2013-09-10].http://hadoop.apache.org/.
[6] CSARDI G,NEPUSZ T.The igraph software package for complex network research[C].InterJournal,Complex Systems, 1695.2006.