
文献标识码: A
文章编号: 0258-7998(2014)01-0060-04
目前,诸多网络流量识别技术[1]是根据数据包的IP地址、端口和载荷对网络流量进行判断,但随着应用层协议种类在不断增加,网络流量逐渐庞大,加之网络代理、端口的动态变化策略和协议加密等技术的采用[2],使得网络管理愈加困难。如P2P通信通常采用随机端口[3],迅雷的数据传输复用在HTTP业务之上等,而且这些数据所占比重越来越大。因此,有效地保障网络安全,保证网络资源的合理管理就显得尤为重要。而传统的识别方式已不能有效地识别。从目前来看,各种应用层协议识别算法的研究已经取得了一些成果,但是还不足以解决当前所存在的问题。如将支持向量机方法应用于P2P流的识别领域[4],基于行为特征加权的P2P流识别方法研究[5],采用机器学习方法实现网络协议识别[6]等。这些方法基本上都引入了数理统计的思想,在一定程度上解决了传统端口和特征识别对加密协议难以识别的问题,但是效率仍然是制约其实际应用的关键因素。针对以上问题,在分析现有协议识别方法的基础上,结合用户对网络应用识别准确性、高效性和扩展性的要求,提出了立体化的网络应用层协议识别。
1 现有协议识别方法与存在问题
传统的协议识别方法主要有基于端口的识别和基于负载的识别两种[7]。随着Internet数据流量的不断增大、属性的不断变化,基于行为分析的协议识别算法也成为学者们研究的热点。就目前来看,不管是从最简单的端口识别到最繁杂的负载识别,还是最新的协议行为分析,都存在各自的不足,无法满足实际应用对协议分析的要求。
(1)基于端口的识别。根据分析数据包的端口号来识别协议[8]。这种算法最大的优点是效率高、能够准确识别标准协议,但是现有的很多协议使用的端口均是非知名端口、并处于动态变化中,因此基于端口的协议识别也就逐渐失去效力。
(2)基于载荷的协议识别。通过对数据包内容进行深度分析和检测,扫描协议特征,对数据流进行分类。典型的开源包如IPP2P和OPENDPI等,都是根据协议的载荷特征进行分类。基于载荷的算法仍然属于一元判别方法,从理论上讲,只要有足够的工作量,该算法即可以准确识别所有的非加密协议,但随着协议不断更新和加密协议的应用,这种方法工作量大,并且不能识别加密协议和大多数P2P协议。
(3)基于行为分析的识别算法[9]。利用协议规范的不同所造成的行为特征的差异区分协议。目前这种算法还在研究当中,但是从目前来看,准确性在70%~90%之间,而且效率较低,经常出现延时和丢包等现象。
2 立体化协议识别系统设计
为了弥补单一采用上述方法的缺陷和协议特征库更新难的问题,在基于Linux内核的环境下,秉承模块化的设计思想,结合上网行为管理系统,通过不断实践与测试,采用树形分类结构,加入表驱动的查找方法,改进DPI的统计识别算法和借鉴Linux驱动的加载模式,力求提高协议识别的准确性、高效性和可维护性。
2.1 系统识别方案
立体化的协议识别系统主要借鉴了树形分类思想,从上至下,由标准简单协议到繁杂协议逐层分类识别。其识别流程为:数据流首先进入数据包缓存,将五元组信息按照设定好的数据格式存储并做相应的处理;然后进入到协议识别分析器进行协议匹配,最终输出结果。
立体化协议识别系统主要包括初级层、中级层、高级层。在初级层主要是根据数据包的五元组进行分流,统计数据包的多元信息,方便快速识别;中级层以端口和首字节[10](载荷的第一位)的协议链为切入,协议特征库为依托,实现基于端口和载荷的协议识别,主要针对RFC标准协议和部分P2P协议,承担了70%左右数据包的协议识别;高级层主要是基于SVM机器学习的协议行为分析识别,实现对加密协议和P2P协议的自主学习识别。这部分一般占流量的30%左右,是识别的最后方法。立体化的协议识别流程如图1所示。

2.2 改进的端口和载荷识别方法
由于单纯采用端口和载荷识别有其局限性,属于一元判别,因此这里使用了将端口和首字节作为协议链进行二元匹配,同时生成哈希表。根据数据包的端口和首字节将数据包分为有端口有首字节(优先级最高)、有端口无首字节(优先级次之)、无端口有首字节(优先级其后)和无端口无首字节(优先级最低)4种情况。当有新的协议链要注册时,会按照优先级状态加入到协议链。如QQ的443端口0x00首字节的协议链:
{"tcp_qq_443_0x00",tcp_qq_443_0x00,exist_fiby,IP_TCP, most,0x00,443}
表明这是QQ的443端口,存在首字节0x00,属于TCP协议,优先级最高,挂载在443端口下。在协议链内部,结合协议特征库通过字符串、特征比对的方式进行进一步识别。如上述协议链的内部特征:
if((*(payload+1)==0xb0)||(*(payload+2)==0x2c)||
(*(payload+0)==0x2c))
{
return PRO_QQ;
}
当数据包通过时,首先通过表驱动对应到具体的端口首字节协议链,然后依据协议特征库比对,进一步准确识别。这样不仅解决了单纯采用端口和载荷识别一元信息单一的问题,而且提高了效率和识别的准确性。与此同时,系统已经收集了100多种协议特征,工作量浩大。为了以后维护升级方便,根据每一个具体协议特征,将其独立为C文件,组成一个协议特征库。具体实现如下:借鉴Linux驱动模块的加载方式,将每一种应用层协议以模块的形式定义,当需要注册使用时,通过包含进其头文件,加入注册函数,动态加载后即完成新协议的注册。通过采用这种方式,可以方便快捷地更改或添加协议特征库,从而实现协议库的升级,解决了协议载荷特征维护繁杂的问题,大大提高了系统的可维护性。
2.3 高级层识别方法
由于基于行为的识别方法具有机器学习的能力,是一个多维空间的统计判别方法,如何选择尽可能少的属性特征值是影响算法的重要因素[11]。目前针对P2P协议和加密协议,主要借助于支持向量机、神经网络和统计的方法,适合于粗粒度分类。
高级层识别方法算法的主要思想是:利用SVM的分类算法,统计在单位时间t内,相同IP通信的连接数M,高端口通信率H,发送包方差Q,流量占有率V,持续时间T这5个属性分别作为二分类训练,用于P2P和非P2P的分类;将双向连接率B、等长度数据包率S作为精确P2P训练属性,最终实现对数据包的准确分类。
2.3.1 属性选取
通过包属性来区分包类别,需要选取各个数据包中差别较大的特征。在实际网络环境中,随着带宽的不同及网络设备的差异,所提取的特征属性之间相互关联。因此,从易于分析、差异较大的角度考虑,选取了9种属性特征。具体特征如表1所示。

2.3.2 SVM的机器识别实现思路
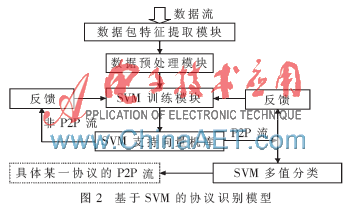
一对多SVM分类原理简单,容易实现,其基本思想为:k(k>2)类SVM分类,将类1视为一类,其余k-1类作为另一类,将k类分类问题转化成二分类问题[12]。协议识别问题本质是一个分类问题,协议识别模型是建立在通过大量已知流的属性数据得到的。一个具有良好性能的支持向量机的关键在于模型的建立、核函数的选择以及一些参数的选定。SVM的协议识别模型如图2所示,数据包特征提取模块主要负责从数据包缓存中获取数据,统计数据包特征值;数据包预处理模块负责过滤掉杂包、缓存并转换成SVM能够执行的标准格式;SVM训练模块完成数据的特征训练。SVM支持向量机库主要采用了台湾林智仁教授的LibSVM库,该软件属于开源的包,支持多种语言。基于SVM的反馈学习主要是通过设定一个识别的预设值,当识别率低于这一值时,将其放入反馈表中。总体而言,RBF核函数是一个普遍使用的核函数,能够适用于所有分布样本。在参数选择方面使用了python语言、gunplot以及LibSVM提供的tools交叉验证选择最优的c和g。
3 实验数据
3.1 实验数据收集
为了验证本文方法的实验效果,分别在不同网络环境下收集网络数据包。图3所示是实验网络拓扑图。为了保证采集数据包的纯净性,每次在IP地址为192.168.1.161的机子上只运行一款软件,通过Wireshark网络封包分析软件抓取各协议的数据包保存。

3.2 准确性与延时分析
3.2.1 应用准确性分析
通过上述数据收集,对常见的几种P2P与非P2P协议包进行了测试。其中,包总数指经过Wireshark过滤后纯净包的总数据包个数;识别数指经过协议分析后,能够返回正确识别结果包个数。表2为协议识别系统对一些协议包的分析结果统计。通过分析发现,对于标准协议识别率高于流媒体和P2P下载,这主要是因为机器学习分类方式是一种粗粒度分类方法,容易受到网络环境的影响。

3.2.2 网络延时分析
实验中,利用Linux下TC对数据包打标命令,对某一条数据包打标,同时返回其经过协议模块一(端口载荷识别)和模块二(机器学习识别)的标签;然后计算其经过系统分析后所花费的时间,得出每一协议延时量的平均值并统计出分别经过模块一和模块二的包总个数。系统延时如表3所示,其中,包总数指的是实验中所分析数据包的总个数,占有率指数据包分别经过模块一和模块二包个数占统计包总个数比值。可以看出,由于标准协议只经过初级层和中级层的分析,因此延时量相对较小;而需要进行机器学习方式识别的P2P和流媒体协议,其延时量比较大,这主要由于SVM不断学习反馈导致。但进入高级层识别数据包相对较少,基本在容忍范围之内。

3.2.3 对比分析
为了验证本文方法在识别率和效率两方面的提高,实验对一些常用协议分别采用端口识别法、载荷识别法、传统统计识别法和本文方法进行测试对比。从准确性上进行比较,如图4所示。可以看出,基于端口的识别正确率接近于0,基于载荷的识别对HTTP和QQ登录识别较高,而对采用加密的迅雷和FTP较低,而本文所采用的方法都高于它们。从效率上比较,如图5所示,在相同的网络环境下,端口和载荷的识别消耗时间都不会很大,统计的方法延时较高,而本文的方法介于两者之间,因此该识别方法是行之有效的。

应用层协议识别作为计算机网络研究的一个热点,但其又必须兼顾准确性、实时性和维护性的设计要求,系统在传统的协议识别的基础上,通过添加基于机器学习的行为特征分析提高P2P协议分析的准确性,并采用表驱动的方法尽可能地改善系统运行效率。通过借鉴Linux驱动的模块加载方式,将端口和首字节作为整体自动挂载到协议链,将每一种应用层协议以协议链的形式完成加载,提高了特征库的可维护性。总之,通过不断的改进与完善,基于立体化的应用层协议识别系统已被成功应用。但就目前来看,单独的协议分析作用是有限的,它必须配合于其他模块才能更好地发挥作用。为了使协议分析应用范围更广、效率更高以及更加准确,下一步工作将会结合审计和流控,继续改进对加密协议、非标准协议的识别。
参考文献
[1] 陈伟,胡磊,杨龙.基于载荷特征的加密流量快速识别技术[J].计算机工程,2012,38(12):1-4.
[2] 徐莉,赵曦,赵群飞,等.利用统计特征的网络应用协议识别方法[J].西安交通大学学报,2009,43(2):43-47.
[3] 魏永,周云峰,郭利超.OpenDPI报文识别分析[J].计算机工程,2011,37(S1):98-101.
[4] 盘善荣.基于SVM的P2P流量识别方法研究[D].湖南:长沙理工大学,2009.
[5] 崔燕,汪斌强,陈庶樵.基于行为特征加权的P2P流识别方法研究[J].计算机工程与设计,2009,30(20):4805-4807.
[6] WU Amei,Dong Huailin,Wu Qingfeng,et al.A survey of application-level protocol identification based on machine learning[C].Proceedings of the 2011 International Conference on Information Management,2011.
[7] 刘元勋,徐秋亮,云晓春.面向入侵检测系统的通用应用层协议识别技术研究[J].山东大学学报(工学版),2007,37(1):65-69.
[8] 陈亮,龚俭,徐选.应用层协议识别算法综述[J].计算机科学,2012,34(7):73-75.
[9] 王明丽,傅彦,高辉.基于行为特征的P2P协议识别[C]. 中国计算机网络安全应急年会信息内容安全分会,2008.
[10] 牟乔.准确高效的应用层协议分析识别方法[J].计算机工程与科学,2010,32(8):39-45.
[11] 陈佳.应用层协议快速识别的研究与实现[D].北京:北京邮电大学,2010.
[12] 李卫星.基于SVM的机器学习识别P2P流的方法的研究与实现[D].北京:北京邮电大学,2010.