
文献标识码: A
文章编号: 0258-7998(2014)07-0044-04
运动估计是视频编码中的关键部分,同时也是较为复杂的部分。在运动估计中,运动搜索算法分为两大类:全搜索算法和快速搜索算法[1]。全搜索算法(FSM)是一种搜索策略最简单的算法,是将搜索范围中的每个块都搜索一遍,从而找到最佳匹配块。此算法简单可靠,易于硬件实现,但是计算量大,耗费的时间多。快速搜索算法是一种只对少数可能是匹配块的候选块进行匹配,从而找到局部的最佳匹配块。此算法计算量小,时间开销少,但是算法复杂度高,不易于硬件实现。
由于视频信号处理对实时性要求很高,而FSM需要计算所有的宏块,费时较长,因此,本文采取分层的方式[2],即在搜索区域中每隔一个像素选取一个像素点作为候选块搜索的起点(1、3、5…),利用多个存储器并联,将单个像素的读入/读出转换为一列像素的读入/读出,并结合大量的处理单元(PE)构成并行的处理器阵列进行数据处理,设计一种分层的二维阵列全搜索运动估计硬件电路,大大减少了计算量以及编码时间。
1 基本原理
对于运动估计分层二维阵列全搜索方式,大致有两种最基本的实现方法:(1)所有的PE阵列同时进行匹配,计算搜索区域内所有的候选块,这是一种高度并行的方式,处理速度快,对于16×16的当前块,只需256个时钟周期就可完成搜索,但是输入数据带宽大,控制较为复杂,不易于硬件的实现;(2)相邻的PE进行匹配时,无论是行还是列,各自都存在延时,如图1所示,本设计以当前块为16×16的宏块、搜索区域为32×32为例,同一行的PE1是在PE0工作2个时钟周期后开始工作,同一列PE8是在PE0工作32个周期后开始工作,然后以此类推。这是一种并行的流水线结构,数据流规整,易于操作,共需要494个时钟周期就可完成搜索,但是延时器过多,硬件资源消耗大[2-4]。
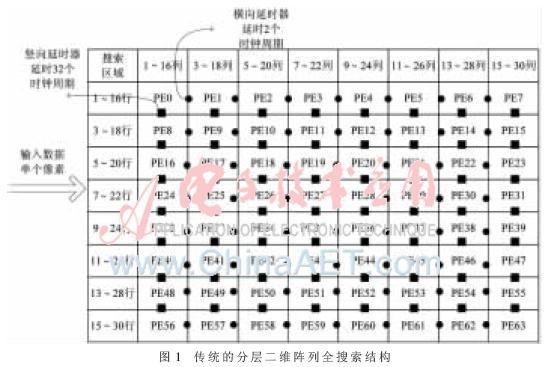
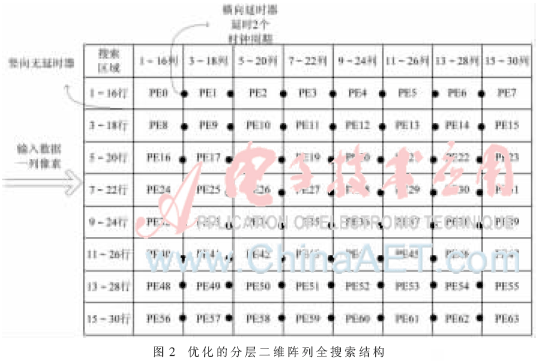
本设计提出的分层二维阵列搜索方式对以上两种方法作出了改进,如图2所示,列与列之间的PE是存在延时的,而行与行之间的PE是不存在延时的,比如第一列的PE最先同时工作,紧接着延时2个时钟周期,第二列PE也开始同时工作,然后以此类推,最先工作的PE,也最先结束工作。同时从图中还可看出,输入的数据为一个时钟周期输入一列的像素,而非单个像素,这样设计不仅使得延时器的个数减少了一半,节约了硬件资源,而且使得一个块的匹配只需16个时钟周期,再加上延时的14个时钟周期,那么完成搜索总共只需30个时钟周期,大大节约了编码的时间。
2 硬件电路设计
分层二维阵列全搜索运动估计硬件电路是以16×16的宏块为对象,32×32为搜索区域,采用了64个处理单元(PE),形成并行的流水线结构[5],它包括地址发生器、16×16的Ram0、32×32的Ram1、延时器、二维PE阵列、比较器和控制器7个模块。原理框图如图3所示。
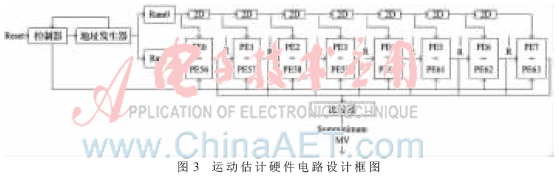
图3中地址发生器用于产生读与写的地址以及一些控制信号。7个延时器采用级联的方式连接,其作用是将当前块数据延时输出,第一个延时器(delay1)的输入连接Ram0的输出,延时两个周期;第二个延时器(delay2)的输入连接delay1的输出,又延时两个周期,然后以此类推。Ram0、delay1、delay2…delay7的输出分别作用于PE0~PE56(第1列PE)、PE1~PE57、PE2~PE58…PE7~PE63,这样形成了每延时2个周期,一些PE才开始工作,其余部分以下作详细的介绍。
2.1 存储器阵列设计
以Ram0为例,它是一个16×16×8 bit的存储器,用来存储当前块的数据。Ram0的设计是使用了Quartus II 的宏功能模块RAM[6],它是一个16×8 bit的存储器。因此,为了设计成一个16×16×8 bit的存储器,本设计采用16个16×8 bit的RAM并联。结构图如图4所示,16个RAM共用同一个读/写地址线,当读/写地址线从0000~1111变化,分别读出/写入Ram0的第0列~第15列。
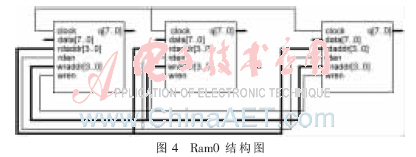
从图4中可以看出,Ram0的输入/输出端口都为16×8 bit宽,一个周期可以输入/输出一列16个像素的数据,这样一个16×16的宏块只需要17个周期就能完全读出。与单个像素的输入/输出相比,节约了大量的周期,加快了读入/读出的速度,能更好地满足实时性要求。
2.2 二维PE阵列设计
处理单元阵列是运动估计中的核心模块,它的运算量最大,占用硬件资源也最多。本设计采用了64个PE进行数据的处理,PE的内部结构如图5所示[7]。首先对当前块数据(C)和参考块数据(R)进行绝对值差值运算,然后将得到的差值与上一次计算所得的值SAD进行累加(ALU),并将累加的结果放在寄存器(REG)中,计数器作用于累加器,控制累加的次数,当累加次数达到16次时,输出匹配块的最终残差值SAD。

2.3 数据比较器设计
数据比较器作用于PE之后,对PE最终输出的各个数据比较大小,从而得到当前块与搜索区域参考块的最小残差(SAD)。它的硬件结构图如图6所示。
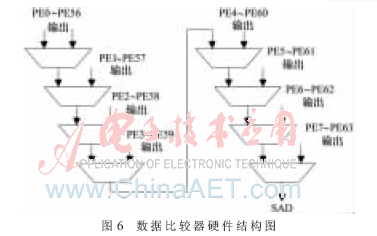
从图6中可以看出,此模块是采用8个数据比较器级联的方式,PE0~PE56(第一列PE阵列)的最终输出最先比较大小,得到这一列阵列的最小值;紧接着过2个时钟周期,PE1~PE57的最终输出与之前得到的最小值进行比较,又得到一个最小值。同理可得,延时14个时钟周期后,PE7~PE63的最终输出与上个比较器的输出进行比较,得到最终的最小值SAD。
2.4 控制器设计
控制器的工作过程可以分为两个部分:控制Ram的读写、控制PE是否工作。具体工作过程:在复位结束后,在时钟的触发下产生写信号,开始对Ram0、Ram1写数据;延迟一个周期产生读信号,开始对Ram0、Ram1读数据;又延迟一个周期产生enable0使能信号,它作用于第1列的PE,表示第1列PE有效,开始工作;接着,延迟2个周期产生enable1使能信号,它作用于第2列的PE,表示第2列PE有效,开始工作;以此类推,enable2……enable7都是在之前的一步延迟2个周期后产生的。工作状态转移图如图7所示。

3 整体验证结果及分析
本文设定时钟频率为100 MHz,即时钟周期为10 ns,输入数据宽度为8 bit,16×16当前块所有数据为2,32×32搜索区域数据除7~22列的1~16行(PE3计算区域)外,其他区域全为3,而PE3计算区域只有一个数为3,其余为2,部分仿真结果如图8所示。从仿真图可以看出,最小残差值(SAD)的输出用了35个时钟周期,其中PE阵列的输出用了30个时钟周期,其余的用于控制和比较。sum0(PE0的SAD输出)、sum8…sum56第1列的PE阵列首先输出结果,每个时钟周期输出1列,经过16个时钟周期,最后累加输出最终结果;sum1、sum9…sum57第2列的阵列延时2个周期输出结果,然后以此类推。

观察仿真结果可知,最匹配块为PE3计算的区域(sum3=1),残差最小值SAD为1,与设定数据的理论计算相符,从而验证了设计的正确性。
此硬件模块采用Verilog HDL硬件描述语言,使用Quartus II 8.1进行综合与仿真,实现了分层二维阵列全搜索的硬件设计。结果表明,在工作频率为100 MHz时,相比于传统的方法,节约了不少时钟周期,对于30 f/s的情况,完全可以得到满足。
本文采用分层的二维阵列全搜索方法,设计了基于FPGA分层的二维阵列全搜索硬件电路,并对此硬件电路进行了分析,完成了各个子模块的设计,最后对整个模块进行了仿真,实现了复杂度和编码速度的良好折中。由于本设计采用的是分层搜索方法,精度相比传统全搜索有所降低,如果想进一步提高精度,可以以分层搜索得到的最佳块为中心,对其相近未搜索的几个像素点进行细搜索。实际上,得到最终高精度的匹配块,也减少了近一半的工作量,提高了搜索效率。
参考文献
[1] 贾克斌,刘鹏宇.基于H.264的视频编码处理技术与应用[M].北京:科学出版社,2013.
[2] 何春芬.基于FPGA的H.264帧内预测与帧间预测设计[D].重庆:重庆大学,2009.
[3] 和王峰.AVS运动估计模块硬件架构设计[D].哈尔滨:哈尔滨工业大学,2008.
[4] 吴燕秀,王法翔.适用于AVS的高性能整像素运动估计硬件设计[J].电子技术应用,2013,39(1):40-42.
[5] 胡文安.AVS视频编码并行算法的研究与实现[D].成都:电子科技大学,2010.
[6] Michael D.Ciletti.Verilog HDL 高级数字设计[M].北京:电子工业出版社,2005.
[7] 李本斋,吴从中,陈家银.H.264运动估计硬件加速器的设计[J].电视技术,2010,34(S1):79-81.