
2010年一季度,LSI发布了新一代多核媒体处理器或基带处理器:StarPro2704和StarPro2716(简称SP27xx)。LSI上一代多核媒体处理器StarPro2603和StarPro2612(简称SP26xx)已经在2G无线基带及语音媒体网关上成功应用。SP27xx相比SP26xx,在媒体和基带算法处理能力上有至少2倍的增强,同时在降低功耗方面加入了很多先进技术。针对运营商级和中小企业级的3G/4G无线基站、更高密度的语音媒体网关以及高清视频服务器等方面的应用,SP27xx均能提供业界领先的高性能低功耗的解决方案。本文首先介绍SP27xx的新特性,然后着重分析SP27xx在高清视频领域的应用。
SP27xx体系结构
SP2716是通过MCM多芯片封装工艺将4个SP2704的裸片封装成一个芯片,其处理能力是SP2704的4倍。相对于4个SP2704,SP2716大大放宽了对单板尺寸的限制,这使得用户能够更方便地扩展高端音视频业务。下文重点介绍SP2704的体系结构。
SP2704继承了SP2603的体系构架,由2个基本模块组成:媒体处理模块(MPB)和包处理模块(PPB)。媒体处理模块主要由4个SC3400e的DSP子系统组成,而包处理模块的核心是ARM11双核处理器系统。在这种单芯片DSP+ARM的多核处理器结构中,数据面和控制面分别由DSP和ARM来处理,使得DSP可以最大程度地利用其运算优势,同时不需要额外使用片外处理器来处理应用程协议,是最高效的音视频媒体网关结构。
SP2704拥有超大的片内内存,对于高密度语音网关和非高清视频应用,一般不需要使用片外存储区,这就最大程度地降低了成本和单板总功耗,减少了软硬件设计复杂度,也放宽了单板尺寸的限制。此外,SP27xx采用了业界领先的40nm芯片工艺,还引入了许多先进的低功耗技术。以语音网关应用为例,SP27xx的每通道功耗远远低于业界其他同类芯片。
1)DSP子系统(DSS)
SP2704有4个频率为750MHz的StarCore SC3400eDSP子系统(DSS)。相对上一代芯片SP2603,如果不考虑DSP内核能力的增强,SP2704的DSP处理能力可达SP2603的两倍。每个DSS还包含内存保护单元(MPU),256KB本地零等待RAM,32KB一级指令高速缓存,32KB一级数据高速缓存,512KB L2高速缓存,两个专用的2通道DMA控制器。
2)包处理模块(PPB)
包处理模块(PPB)是基于双核ARM11 MP的子系统,工作频率仅为DSS工作频率的一半。PPB主要负责整个芯片加载和管理(包括ARM和DSP),以及输入输出数据包的管理。PPB还包括:ROM用于存放ARM Boot代码,以及SPI/SSP、UART、NAND flash控制器接口,可为客户提供多种Boot方式。
3)丰富的片内内存和2个超高带宽总线
SP2704中有2个超高带宽总线矩阵:DSP总线矩阵和PPB总线矩阵,可用作数据处理功能模块的系统互连,以1/2DSP子系统时钟速率运行,带宽分别是128位和64位。SP2704拥有丰富的片内内存,除了DSP和ARM子系统内部的零等待RAM,还有一个6M的片内系统共享内存。共享内存分成12个存储块,不同的内核可以同时访问不同的存储块,真正达到了数据访问的高吞吐量、高可用性以及低时延。
4) 丰富的接口资源
SP2704拥有丰富的接口资源,可以满足各种音视频网关服务器应用:两个10/100/1000/2500Mbps以太网MAC,可配置为FE(SS-SMII)或GE(SGMII);TDM处理模块通过6个串行端口进行TDM流量的多路复用和解多路复用;10Gbps x4 sRIO接口(4个3.125Gbps Lane)或者配置为两个独立的x1SRIO接口;PCIe接口,可接到host或SP2704设备之间互联;32位DDR3接口工作频率高达1066MHz。
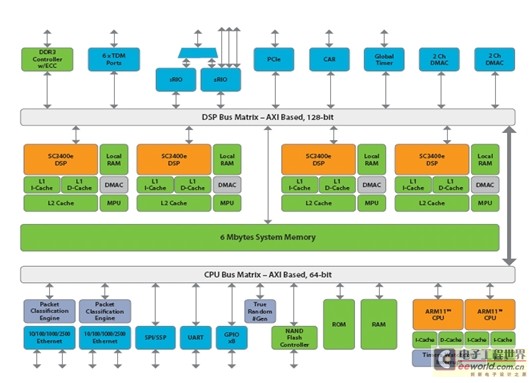
图1 SP2704媒体处理器体系结构。
SC3400e---基于SC3400的增强
SC3400e与SC3400后向兼容,SC3400e继承了SC3400的变长指令集(VLES)结构和12级流水深度。SC3400e的能力增强表现在以下几个方面:
1)实数和复数乘加能力的增强
SC3400e与SC3400的数据算术逻辑单元(DALU)都包含了4个乘加单元(MAC)。SC3400的MAC包含1个16位*16位的乘法器和1个40位的加法器;而SC3400e的MAC包含4个16位*16位的乘法器和2个40位的加法器,其加法器支持2个40位复数操作数的加/减法。实数乘加运算能力提高1倍,而复数乘加运算能力则是原来的4倍。
SC3400e的实数和复数MAC运算能力可概括为:每周期可完成8个16位实数乘加运算,性能是SC3400的2倍;每周期可完成4个16位(16位实部,16位虚部)的复数乘加运算,性能是SC3400的4倍;每周期可完成8个8位(8位实部,8位虚部)的复数乘加运算,性能是SC3400的8倍;每周期可完成4个32位*16位的实数乘加运算,性能是SC3400的2倍;每周期可完成4个(16位*16位+16位*16位+40位)的实数点积运算。如果设置了饱和模式,A=sat{sat{A+BxC}+DxE},则性能是SC3400的2倍。
2)在COF和控制代码效率方面的改进
SC3400采用先进的动态分支预测机制,可有效减少COF(Change of Flow)的延迟。例如,某条JMP指令已经在分支目标缓冲(BTB)中,实际执行只需要1个周期,而不是6个周期。SC3400e在原有的分析预测机制的基础上,完成了多方面的改进。
在SC3400e中,硬件循环和COF共同使用n个BTB,突破了SC3400中只支持4层嵌套的零开销硬件循环的限制。而且,SC3400e还改进了硬件循环误判的开销,就算硬件循环条件不成立,开销也只有3个周期,而在SC3400中这样的开销最多达6个周期;在SC3400e中,提高了短循环的执行效率,同时短循环不再占用BTB;SC3400e支持4个返回地址寄存器,相对SC3400中的一个返回地址寄存器,减少了子程序返回的平均延迟。总体看,相对SC3400,SC3400e控制代码的效率提高了0.25倍。

图2 高清视频编码及解码的多核功能分配示意图。
3) 查找表的性能提高
在SC3400e中,带有线性地址修改的指令1个周期就能完成。查找表的性能提高了0.5倍。
4) SC3400e中改进的视频加速指令
SC3400e中改进的视频加速指令主要包括:用于半像素插值的插值指令,性能提高1倍;用于运动补偿的Add-and-Sat指令,性能提高1倍;1个周期完成位插入或位抽取操作。对于位流与字节之间的pack/unpack及其他位流处理算法,性能提高1倍。
SP2704二级缓存的使用
SP2704支持二级缓存(L2 cache):其中一级缓存(L1 cache)分成32k指令缓存和32K数据缓存,二级缓存可灵活用于片外程序和数据的缓存。对于高清视频编解码的应用,需要使用DDR3存储器来存储大量的视频数据。这时,一般会配置二级缓存映射到DDR存储空间。同时,如果再配置L1 cache缓存L2 cache的数据,对缓存进行合理的优化,会使片外的视频数据读写效率更高。
L2 cache还可以配置成共享内存,如果L2 cache配置成共享内存,6MB共享内存的空间就扩展为8MB。对于不需要放置片外存储器的应用,一般会把L2 cache配置成共享内存,进一步增加数据和代码的片内存储空间。
分层的多核编解码器构架
对于H.263或H.264的高清视频编码,一个DSP核无法完成1路图像的编码/解码,因而需要由多个核协作完成,这就涉及到多核之间任务分配的问题。LSI目前采用灵活的多层编解码构架,以片(slice)为基本单位对图像进行分割,每个核处理一个或多个片。这样,可以在多核之间扩展,也可以通过sRIO、PCIe等高速互连总线在多器件之间扩展。
以1080P(1280*720)H.264的解码和编码为例,如果一个SP2704处理1路30fps 1080p H.264解码,多个SP2704协同处理1路30fps 1080p H.264编码,SP2704#1解码后的YUV4:2:0的图像数据提供给SP2704#2来进行编码,参考帧数据将存放在DDR3存储器中,如图2所示。
多核分层编码器
在协同处理1路图像的多个核中,一个核作为主核,其他核为从核。主核除了要负责一些slice的编解码之外,还要处理负荷平衡、场景识别及速率控制这样的公共任务。其他从核将只是对分配的slice进行处理。
多核分割可以减少高清视频编码的延迟,而动态负荷平衡功能可最大程度减少延迟。SP2704内部的4个DSP核可以通过6M的共享内存和DDR3片外存储器来共享视频数据:当前图像存放在6M的共享内存中,通过L1数据cache缓存片内共享内存的图像数据,参考图像存放在DDR3外部存储器中,通过L2 cache来缓存DDR3中的图像数据。从而使得视频数据访问的速度达到最快。
SP2716中的2个SP2704之间可以通过PCIe共享DDR3存储器,这样可减少2个SP2704之间的数据交互,从而简化了软件开发的复杂度,还将整个硬件设计所需的DDR3设备数量减少了一半。此外,多个SP2704器件之间通过sRIO接口来传输或共享视频数据,这些SP2704都连接到sRIO开关上。每个器件都可以自发地写入到其他任何一个器件的I/O空间。
多核解码器
H.264解码涉及串行操作和并行操作。熵解码包含一系列串行操作,无法分配给多个内核并行处理,因而将由主核处理,其他并行操作可以分配到各个从核来处理。LSI分层解码器的基本原理是:由主核负责熵解码,再把熵解码后的数据分配到各个从核来处理。其他从核读取数据后进行后续处理,例如逆量化、逆变换等;对于P宏块还要从DDR3中读取参考帧数据并进行运动补偿。最后进行循环滤波,并把得到的宏块数据存入DDR3的当前帧中。