
一款专用可编程语音压缩芯片的设计
2008-04-03
作者:韩大晗1, 崔慧娟1, 唐 昆1
摘 要: 基于SELP算法模型原理,设计了一款高质量多速率语音专用处理器芯片。芯片使用可重构" title="可重构">可重构体系结构和超长指令字系统设计方法,将复杂度高的子程序" title="子程序">子程序进行优化,能够显著提高指令并行度。仿真结果表明,在该芯片上实现语音压缩编码算法,执行效率高于相同工艺水平的通用DSP,并保持原有编码质量。该处理器能够实现多种类型的语音压缩算法" title="压缩算法">压缩算法,可以达到对语音算法的高保密性、低复杂度和易开发性。
关键词: 语音压缩 专用芯片 可重构体系结构 超长指令字
在通信过程中,为了适应多种应用目的,需要使用不同的语音压缩编码算法。如果利用DSP进行编程[1],存在编程难、保密性差、成本高等缺点;如果使用ASIC完成算法实现,只能用于实现单一算法,不能扩展到其他算法,难以进行二次开发[2][3]。
利用可重构体系结构[4],可以将各类语音算法常用的功能模块使用专用指令集逻辑化实现,而对算法的可变成分仍使用基本指令集编写,能大幅度降低程序量和编程工作量。片内FLASH(包括程序区与数据区)对外不可见,只能通过注入方式进行修改而不能读取。这样,既可以有效地达到算法的保密性,又能在固化的专用指令基础上方便进行算法的改进,同时保持专用芯片制造成本低的特点。基于此思路开发了一种可编程专用语音编解码芯片TR100。
1 SELP算法介绍
压缩算法采用实验室自行开发的基于SELP(Sinusoidal Excitation Linear Prediction)的多帧联合编码算法[5],在线性预测正弦激励模型的基础上,引入多帧参数联合矢量量化" title="矢量量化">矢量量化方法,进一步压缩帧间冗余,使语音谱包络信息和余量信号得到较好表示,在0.6kbps的极低速率下,获得了很好的重建语音质量,可懂度达到90%以上。

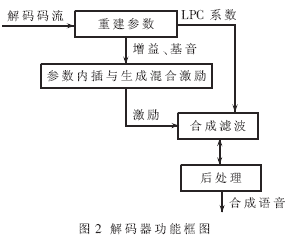
算法原理如图1和图2所示。输入8kHz采样率的语音信号以200个样点为一帧,首先经过预处理后进行线性预测分析,对每帧语音提取预测系数、基音周期、子带清浊音度和余量信号短时能量等参数。解码器端采用多带混合正弦激励,分别通过由清浊音信息调制的带通滤波器合成激励信号,而后进行合成滤波和后滤波产生合成语音。
在0.6kbps速率运行时采用多帧联合量化编码技术,将相邻的3个语音帧联合起来形成一个超帧。将预测系数转化成线谱对系数,采用基于模式的余量分裂多级矩阵量化P-RS-MSMQ算法来量化3帧联合的线谱对(LSP)参数。模式信息来自于带通浊音度参数量化结果,用在LSP参数的矢量量化算法上,能够提高量化性能。LSP参数量化分三个步骤:均值去除、模式预测和对LSP残差子矩阵进行多级矩阵量化。用于模式预测的系数矢量是基于超帧模式的转移,由前一超帧和当前超帧确定。预测的残差矢量就是余量LSP参数矢量。将当前超帧各子帧的无偏LSP预测残差矢量组成一个3×10的矩阵,然后分别进行三级矩阵量化,各级量化比特数分别为7、6、6、5。
根据不同的信道状况与质量要求,算法包括0.8kbps、1.2kbps和2.4kbps的三种速率压缩方式,流程与0.6kbps算法基本相同,仅增加对余量信号的提取与编码过程,其中需要进行512点FFT运算。
2 TR100芯片体系结构设计
芯片设计工作主频为20MHz,采用取指-译码-执行3级流水线设计。语音接口与PCM采样芯片连接,压缩数据接口使用RS232标准。内部结构如图3所示。
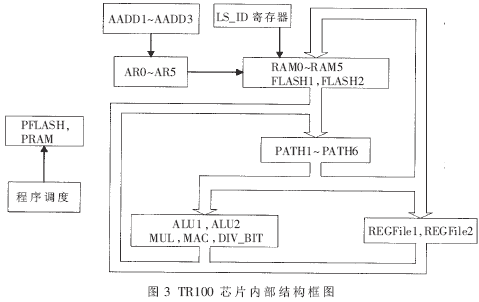
设计中采用了可重构体系的思想。所谓可重构体系结构,是指某一计算系统能够利用可重用的硬件资源,根据不同的应用需求,灵活地改变自身的体系结构,以便为每个特定的应用需求提供与之相匹配的体系结构。TR100芯片采用粗粒度可重构体系结构,基本的可重构硬件单元包括存储系统、运算单元、程序调度控制、寄存器和数据通路等类型。
存储系统包括FLASH和RAM两部分,为避免数据存储瓶颈,芯片内部包含2个16K×16位数据FLASH、5个2K×16位数据RAM,6个地址寄存器可以独立对各个存储器进行单周期" title="单周期">单周期读写操作,3个地址运算单元可以完成地址变换功能。
在运算单元设计上,芯片内部包括2个32位增强型算术逻辑单元ALU,能够完成以加减运算为中心、包括规格化、算术移位、四舍五入等辅助逻辑的复杂运算功能;1个32位乘法器MUL;1个40位乘累加器MAC;1个16位除法器DIV。除法运算需要10个周期,其他运算单元均为单周期执行。
程序调度控制包括程序存储器、2级硬循环、比较跳转部件、比较设置部件、调用/返回部件、溢出判断等单元。程序分两部分存储:程序FLASH存储功能相对简单、指令长度较短的部分,而程序RAM存储功能较为复杂、占用运算量较大、指令长度较长的部分。这种设计方法称为专用指令集设计,一方面保证了大多数语音压缩算法可以在TR100芯片上可重组实时实现,另一方面也因为完成了不同算法的通用模块而方便二次开发。
辅助系统包括一个二组多层寄存器,每组包括19个32位寄存器,两个寄存器组可以被同时访问; 6个32位选通器作为数据通路将存储系统与运算部件进行互联,在保证数据连接灵活性的同时可以有效减少数据线宽;存储器选通寄存器,用于设置指令访问不同存储器,以满足多次调用相同子程序而使用不同数据的要求。
小结一下该芯片的主要特性:
1. 50ns运算周期,20MHz主频;
2. 2个32位增强型ALU, 1个32位乘法器,1个40位乘累加器;
3. 6个地址寄存器,3个地址变换部件;
4. 双重硬件循环;
5. 38×32bit双寄存器组,支持分层窗口式访问;
6. 5×2K字数据RAM,2×16K字数据FLASH;
7. 2K×256bit程序RAM;8K×64bit程序FLASH。
3 超长指令字格式设计
为解决RISC体系结构下,随着并行操作能力增强而导致的内部控制逻辑趋向复杂的问题,在七十年代开始,超长指令字(VLIW)体系结构开始进入研究领域。它的目的是既能支持较高指令级并行性,又能使硬件控制逻辑比较简单[6]。
在针对语音编码算法的专用处理器设计中,VLIW方法是非常适用的。而VLIW体系结构能在低复杂度的控制逻辑水平上产生较高指令并行性,从而使芯片在低主频下就能够实现语音运算算法,这是优于通用DSP的方面。由于算法中对资源并行度要求较高的程序模块数量不大,可以通过全遍历所有运算量较大的模块,提取所有可用的指令并行模式,在硬件控制逻辑复杂度增加很小的前提下实现超长指令译码。
本文设计的VLIW指令系统包括两种形态:基本指令形态和专用指令形态。基本指令形态包括16位、32位、48位和64位四种指令长度,并行程度较低,用于设计对资源并行性要求不高的子程序。专用指令形态包括128位、192位和256位三种指令长度,并行程度较高,用于设计算法中时间复杂度较高、对资源并行性要求大的子程序。基本指令形态和专用指令形态均使用相同的指令格式,区别仅在于长度不同,这样就可以使用相同的译码器进行译码,从而简化了电路设计。在编解码程序运行过程中,基本指令模块直接从程序FLASH中取指,专用指令模块从程序RAM中取指,均能做到单周期取指-单周期译码-单周期执行(除法运算除外)。
具体指令格式如表1。

其中,CBLength惟一确定本条指令的长度;CBSF惟一确定本长度下选用的指令子格式;CBCFi为第i个算子段的控制域,其编码标识第i个算子编码段所对应的算子;OPi为第i个算子编码段编码,其含义由CBCFi惟一确定。指令格式中的算子是指由硬件资源确定的指令字中的最小并行单元。
4 算法程序向芯片指令的移植
各类语音编码算法中,会有一些子程序是通用的功能模块。表2是在TR100上实现这些常用程序的执行效率。

可以看到,整个压缩算法中运算量较大的模块,如滤波器、点积、矢量量化等,TR100的运行效率均明显高于DSP,甚至能够达到2倍以上。这是由于对于运算、存储单元访问密集的模块,硬件体系结构中各个独立的ALU、乘法器、乘累加器与7个存储体在指令系统中也有相应的指令格式进行并行访问,保证可以单周期进行两加两乘运算同时可以向存储器中进行两读一写的操作。而对LPC参数计算与转换、数学函数等虽然运算量不大、但各种语音算法都要使用的模块,TR100的运行效率也与DSP基本相当。这就保证了在TR100芯片上移植各类语音算法时,受程序执行效率的限制较小,而可以专注于算法功能的开发。同时,芯片的注入功能可以对基本指令与专用指令进行修改,开发者如果需要对现有专用指令进行扩充,可以很方便地进行注入更改。
下面以加权矢量量化为例,说明芯片的运算效率。在低速率语音算法中,由于线谱对系数常使用多帧联合矢量量化,使得码本的维数与规模都大为增加,导致搜索码本的运算量非常巨大。在本文SELP算法中,600速率使用的多级LSP码本最大是30维×128个的规模,搜索时需要计算全部码本与当前系数的最小加权距离:

循环内需要进行减法和2次乘法。对于一些有并行功能的DSP,使用流水线方式进行循环内的操作。由于指令宽度的限制,循环体内至少需要3个周期才能完成操作。
在TR100芯片中,专用指令集长度可以达到256位,因此能够将循环体内的操作使用一条指令:
REPEAT 30
ALUR1=R2-R3 || MULR=R1*ALUR1 ||
ALUR2=ALUR1*MULR || LD1 *(AR1+) ||
LD2 *(AR2+) || LD3 *(AR3+) ;
循环开始前进行数据准备,循环内只要将所有运算和取数操作并行起来即可正确完成求加权矢量误差的计算。在循环体内的一个操作周期相当于每秒87万次运算。与通用DSP的实现相比,本芯片可以在循环体内减少5次运算,对矢量搜索模块的优化超过4MIPS。
5 芯片性能
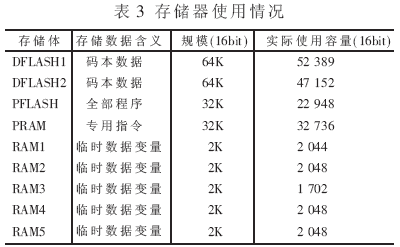
存储器的使用情况如表3,需要注意的是数据FLASH中存储的是4个速率的不同码本,因此规模较大。
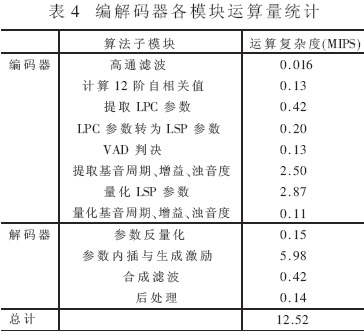
600bps速率算法各子模块的运算量如表4。
与C54x系列DSP实现结果相比,TR100芯片完成编解码的运算复杂度为12.5MIPS,明显低于C54xDSP所需要的40MIPS。TR100芯片需要9.7K字变量存储空间与28K字码本存储空间,与C54xDSP所需的变量存储空间与码本存储空间相当。
为了验证芯片编解码工作的正确性,对比了浮点C程序、定点C程序以及芯片仿真三种情况下各个参数的重建误差。表5中列出了三种情况下的各种结果,采用91 280帧中国军标语音测试数据,可以看出芯片运算结果达到了计算机C程序仿真的水平。

对于语音压缩算法,由于基本算法模型相同,因此可以使用相同的专用处理器结构进行设计,在保证各类算法均可实现的前提下,提高运行效率。减少运算复杂度的意义在于能够降低芯片功耗和工艺要求。即使不同算法有各自专用的处理模块,也可以很方便地通过注入新的专用指令来进行修改。与DSP实现相比,专用处理器的运行效率更高,开发难度更低,保密度更好,更容易降低芯片规模。
参考文献
1 贾志科, 崔慧娟, 唐 昆等. 低速率语音编解码专用芯片的设计[J]. 清华大学学报,1999;39(5):73~76
2 McDonough J , Chang C , Kantak P, et al. A single chip QCELP vocoder for CDMA digital cellular[A]. Proceedings of IEEE Custom Integrated Circuits Conference[C]. New York, NY: IEEE, 1994;211~214
3 Byun K J, Hahn M, Kim K S. Implementation of 13 kbps QCELP vocoder ASIC[A]. Proceedings of AP-ASIC′99: The First IEEE Asia-Pacific Conference on ASICs[C]. Piscat-away, NJ: IEEE, 1999;258~261
4 王昭顺, 王 沁, 曲英杰. 可重构计算机体系结构[J]. 北京科技大学学报,2001;23(4):386~388
5 李军林, 崔慧娟, 杜 松等. 0.8kb/s高质量声码器算法[J]. 清华大学学报,2003;43(1):12~15
6 王 沁. VLIW体系结构微处理器设计考虑. 微计算机信息,1999;15(5):6~7