
使用网络处理器来设计通信系统,所设计的系统结构,和设计时所采用的设计方法,与传统的方法相比都很不相同。影响最大的是设计工作的重点,设计人员的注意力将从硬件线路和通信协议的细节的考虑中,转向软件、服务以及最终用户的技术要求方面。也就是说,设计将是以软件为中心,以通信服务为中心,和以最终用户的技术要求为注意的集中点。设计公司将一改过去集中注意于硬件设计的传统,转而将注意力集中于用户所需要的服务方面,并考虑如何使用软件来实现用户所需要的服务。
这些变化与进展在相当大程度上应该归功于网络处理单元(NPU, network processing unit)的推动。在这种情况下,系统设计人员如果对于网络处理器能够运用自如,那么就可以充分了解网络处理器的作用,并且能够感觉到,与使用网络处理器随之而来的潜在自由空间。系统设计人员也才有可能最大限度地发挥网络处理器的潜能。
附图是系统原理图,它显示出网络处理器在系统设计中所处的重要位置。NPU一般位于物理层(MAC或帧调节器)线路和交换结构之间。在图中并串行/串并行转换器(SERDES)在NPU和交换结构造之间起接口作用。
NPU的运行速度有待提高
表1给出了在不同的数据传输速率条件下,网络处理器处理一个40字节的分组(最小的通信分组)所需要的时间。例如,在数据传输速率为1G位/秒时,网络处理器可以有360 ns 的时间来处理此分组。在这段时间内,NPU必须对分组进行检查,语法分析,以及必要的编辑和查表(有时对于分组的内容需要按照不同的策略采取不同的处理措施,有的继续向前传送,有的要送去排队,有的需要作标记;一般说来,对于一个分组可能要进行2到3种数据库的查表处理)。对于即使是比较低的传输速率1G位/秒,网络处理器也只有360 ns 来完成上述作业;如果传输速率为100G位/秒,对于每个分组就只有3.6 ns 的时间来进行处理了。
从目前情况来看,价格适中的SRAM,存取时间为10 nsec,有望提高到5 nsec。如果将一个10 nsec的SRAM用于1G/秒的数据流,在留给处理分组的360 nsec 时间窗口内,只能对存储器进行36次的存取。如果用于10 G位/秒的数据流,存取次数将减少到只能进行3次了;即使是采用5 nsec的SRAM,也只能进行7次存取。
从表1所给出的数据可以看出,为了有效地提高数据处理速率,只能将处理步骤分段,并采用流水线的方式来进行处理,或者采用多个处理机来并行处理(即多个处理机同时对不同分组进行处理)。这种解决办法,对于策略查表存储器,和内容寻址存储器(CAM)都适用。例如,对于40 G位/秒的数据流,采用10 nsec 的存储器,在允许的时间内一次存取也进行不了。这时,设计人员必须采用许多并行的存储器陈列。
网络处理器可以按照它们对于数据处理的速率来进行分类。在表1的中间部分列出了对于一定的数据速率,需要采用的网络处理器种类和数量。例如,对于2.5 G位/秒的数据流,需要使用3个1G位/秒的处理器来进行处理。而对于100 G位/秒的数据流,则需要144个这样的处理器。对于这样的数据流,也许改为采用12个OC-192处理器,或两个OC-768处理器更合适一些。
表1 对网络处理器处理速率的要求(以每分组40字节为例)
| 传输速率(G位/秒) | 可以用来处理分组的时间(nsec/分组) | 所需处理器的种类及数量 | SRAM存取次数(nsec) | |||||
| 1G位/秒 | OC-48 | OC-192 | OC-768 | 10 | 5 | 2 | ||
| 1 | 360 | 1 | - | - | - | 36 | 72 | 180 |
| 2.5 | 144 | 3 | 1 | - | - | 14 | 28 | 72 |
| 10 | 36 | 12 | 4 | 1 | - | 3 | 7 | 18 |
| 40 | 9 | 48 | 16 | 4 | 1 | 0 | 1 | 4 |
| 100 | 3.6 | 144 | 48 | 12 | 2 | 0 | 0 | 1 |
| 200 | 1.8 | 288 | 96 | 24 | 4 | 0 | 0 | 0 |
除了实际处理分组需要时间以外,将分组从网络一方转移进来,和将数据转移到交换结构一方去也去要花费时间。表2给出的分摊时间是总时间的25%。以上数字对于MAC接口是很符合实际的假设,但是对于交换结构接口,由于分段(segmentation)的效率一般只有50%,因此在计算时需要留下100%的速度余度,才能跟得上通信线路的速度。
表2 对于网络媒体/交换结构接口的要求
| 媒体访问控制和交换结构的接口 | ||||||
| 25%的分摊 | 22位 | 64位 | 128位 | |||
| SDR | DDR | SDR | DDR | SDR | DDR | |
| 1G位/秒 | 39MHz | 20MHz | - | - | - | - |
| 2.5位/秒 | 98MHz | 49MHz | 49MHz | 24MHz | - | - |
| 10位/秒 | 391MHz | 195MHz | 195MHz | 98MHz | 98MHz | 49MHz |
| 40位/秒 | 1563MHz | 781MHz | 781MHz | 391MHz | 391MHz | 195MHz |
| 100位/秒 | 3906MHz | 1953MHz | 1953MHz | 977MHz | 977MHz | 488MHz |
| 200位/秒 | 7813MHz | 3906MHz | 3906MHz | 1953MHz | 1953MHz | 977MHz |
从表2可以看出,对于10G位/秒的传输速率,如果采用32位单数据速率(SDR)总线,则总线必须工作在391MHz。而对于40G位/秒的传输速率,假定采用64位SDR总线,总线必须工作在781MHz。表3总结了对分组缓冲存储器的要求。分组缓冲存储器至少必须具有3倍用通信线路的速度的传输速率(300%的速度余度)。表3中分门别类地给出了这一要求。例如,对于10G位/秒的传输速率,如果采用的是64位的双倍数据速率(DDR)缓冲存储器,则需要工作在313MHz以上的频率。
表3 对分组缓冲存储器的要求
| 分组存储器的界面 | ||||||||
| 300%速度余度 | 32位(MHz) | 64位(MHz) | 128位(MHz) | 512位(MHz) | ||||
| SDR | DDR | SDR | DDR | SDR | DDR | SDR | DDR | |
| 1G位/秒 | 125MHz | 63 | - | - | - | - | - | - |
| 2.5G位/秒 | 313MHz | 156 | 156MHz | 78MHz | - | - | - | - |
| 10位/秒 | 1250MHz | 625 | 625MHz | 313MHz | 313MHz | 156MHz | - | - |
| 40位/秒 | 5000MHz | 2500 | 2500MHz | 1250MHz | 1250MHz | 625MHz | 313MHz | 156MHz |
| 100位/秒 | 12500MHz | 6250 | 6250MHz | 3125MHz | 3125MHz | 1563MHz | 781MHz | 391MHz |
| 200位/秒 | 25000MHz | 12500 | 12500MHz | 6250MHz | 6250MHz | 3125MHz | 1563MHz | 781MHz |
网络处理单元(NPU)的结构问题
网络处理器和中央处理单元(CPU)不同。网络处理器需要对它所需要进行处理自行抽象提取。它必须能够识别字段(field),分组(packet),和数据流(flow)。它必须对于它所需要进行的处理功能,例如:语法分析,编辑,搜寻,和调度等,具有特殊的运算能力。
在程序编制模型方面,网络处理器和CPU并没有根本的不同:它也是一个可以储存程序的微编码机。但是在数据的模型方面则有很大的区别。NPU处理的是一种恒定的连续数据流(一种数据流结构),因此不需要将数据从一个大容量存储器中移进移出。如上所述,网络处理器为了满足一定的数据速率,绝对地需要并行处理,或流水线(pipelined)结构,或者两种方式同时都需要采用。
另一个问题是网络处理器的可编程性能。一个极端是使它具有最大的可编程性,因而使它具有最大的灵活性,也可以在最大程度上适应未来的发展变化(即使它可以通过新开发的软件使系统改变或升级,而不是当要求改变系统时就更新硬件)。这种方式的缺点是,为了完成一项作业需要执行许多个指令,因而可能导致缺乏净空(headroom)。
另一种折衷方式,称为“适当程度的可编程性”。这种方式提供一定程度的可编程性以适应变化的需要,或者说使处理器具有一定的灵活性。但是它不能适应完全的重新编程的需要。和RISC型的CPU类似(RISC采用简约的有效指令集,以提高CPU速度);而NPU则通过提供适当的可编程性,使得系统设计人员能够牺牲某些灵活性,去提高运行速度,换取更多的性能净空。
对于运行在载体网络核心的交换机和路由器,速度的要求高于一切。这些在网际间工作的装置,不需要进行复杂的分组处理功能,只是要求将分组以最大的线速度向前传送。与此相反,在企业网的边沿,线速度明显地比较低,而交换机对分组的处理能力却要求相当的高。例如,对于多协议标记交换机,它处于网络的边沿,需要对某些数据流进行识别并相应地对某些分组予以标记。
交换机的设计人员可以根据这些不同的要求,以及交换机所处的位置,为预计在企业网边沿使用的交换机选择可以充分编程的NPU。而对于将应用在网络核心部位的交换机,则应该选择编程能力有限,但是具有较高速度的NPU。
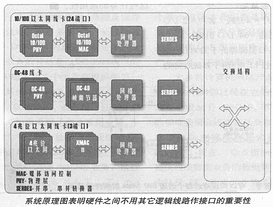
网络处理器的实现方式
网络处理器的实现方式大体上可以分为三种。一种是采用专用的ASIC或FPGA(后者往往功能不够完整,或者性能不够理想)。这种方式就是依靠“硬件”的方式,它具有最高的性能,但是灵活性也最差(因为设计决策是熔制在硅的体内)。此外,ASIC的开发过程比较长,一次性的、不可重复使用的投入的费用也比较高。
另一种方式是将许多个RISC CPU做在一块芯片上,采用对称多重处理的运行方式(使用微编码将通用CPU转变成为专用的网络处理器)。这种实现方式,由于NPU的一切行为几乎都是通过软件实现的,因此灵活性最高。这种方式所需要的开发时间比较短,它展现在设计人员面前的形象是设计人员十分熟悉的编程模型。然而,随着软件复杂性的增加,这种方式的费用也在增长。由于严重地依赖软件,这种方式实现的系统,与采用专用ASIC实现的系统相比性能较差,所消耗的功率也较多。
介乎上述二者之间的一种实现方式是流水线方式,它采用一些具有不同功能的专用处理器,组成“装配线”型式的数据流构造。采用流水线方式实现的系统,性能接近用ASIC实现的系统,而在编程的灵活性方面又和多处理器实现的系统相差不多。
衡量NPU技术水平的尺度
设计人员十分关心的一个问题是技术水平。衡量技术水平,可以从几个不同的层次加以分析。
* 在芯片层次,人们关心的问题是:在一个芯片上究竟可以容纳多大的处理能力?根据当前的技术水准,在一个芯片上可以做成10G位/秒的NPU。
* 在线路卡(line-card)层次,问题在于:一张线路卡可以安置多少块芯片?同样重要的是:使用一个小型交换结构或一个共用的总线,究竟可以将多少块芯片放在一个线路卡上,正常地并行运行?现在看来,可以在一张卡上安置足够的处理能力,使之达到100G位/秒的传输要求。
* 在机架或机箱层次,问题在于,一个机架或机箱,通过一个交换结构可以容纳多少张线路卡进行信息传递?现在看来一个机架实现数太拉(1012)位的传输能力是可能的。
* 在机房层次,问题在于,究竟多大规模的机架簇群可以连接在一起仍然能够进行有效的通信?目前在这个层次上,还没有把握说清楚,但是一些新建的机房已经把目标瞄准在数拍它(1015)带宽的水平。
评价一个NPU不能只看单个NPU的工作能力,还要看它的互操作性。一个10G位/秒的NPU,并不一定比一个9G位/秒的NPU优越。它还决定于互操作性:如果9G位/秒的NPU,能够十分容易地和其它的NPU连接在一起,实现更强得多的交换能力,那么选用它,不失为明智的选择。
设计人员如何才能发挥多处理器的优势?不论是并行结构或者是串行结构,都可以采用;也可以采用混合结构,即串-并排列的结构。重要的问题在于需要考虑:负荷的平衡(注意不使任何一个NPU超载);作业的划分;保持分组流的顺序不乱;维持服务质量;以及对NPU之间通信业务量的控制。
衡量NPU性能的指标
如何正确地评估不同的NPU?关键的指标之一是:处理分组的速度(即每秒处理多少百万个分组或称为Mpps)。另一个指标是:在一定的分组传递速率下,处理每个分组时,允许进行的查表次数(一般每处理一个分组允许进行2次查表)。当然在进行处理时可以利用的存储器的规模也是一项重要指标。此外,及时不断的提高速度也是十分重要的。许多处理策略也需要进行周期性的更新。有些NPU具有能以很高的速度向前传送的性能,但是更新处理策略,或更改某些参数时,却需要耗用数毫秒,甚至数秒的时间才能完成。比较理想的NPU,更新策略,更改参数的时间最好在数微秒的时间范围内;这一点对于用在路由频繁跳变的场合特别重要。
“净空”也是需要的。净空可以看作是在保持线传送速度不降低的情况下,可能增加的处理功能(或可能增加的处理复杂问题的能力);处理复杂问题的能力(即在一个时钟周期内,用一个指令,包括转移这样的控制指令,可以完成多少处理功能)是另一重要的事项。
设计人员应该考虑的其它问题还有:等待时间,排队和调度的效率,分组存储(以及分段)的效率,在硅体内多重熔制的效率,芯片的大小,以及这些问题对于总体系统的影响(包括对于消耗功率和成本的影响)等等。
发展趋势
随着设计人员逐渐习惯于使用NPU进行系统设计,几种时尚可能会流行。下面列出今后几年将会出现的趋向。
* 今日的系统设计越来越趋向于从众多的制造商那里采购ASIC和IC。这些芯片中有许多都是各厂商自家独有的产品,与它们相关联的软件也都是各厂商自行开发的。它们之间往往缺乏互操作性。预计今后几年设计人员会越来越对商品化的IC感兴趣,并且NPU的发展毫无疑问将会进一步助长这种倾向的发展。在硬件方面的发展趋势是越来越多地采用现成的商品IC,软件也在朝这个方向发展,例如一些专门的协议栈开发商正在提供越来越多的商品软件部件。以这些ASIC和IC,以及商品软件部件为基础的增值服务业务也将会发展,并且可能成为交换机供应商引以为荣的特点和具有真正竞争力的象征。
* 在市场范围内,操作系统的供应商将会趋向联合和统一,设计人员采用标准操作系统的可能性会越来越大。
* 从长远看,可能会出现一系列标准的硬件平台,例如标准的机架,标准的背板等。设计人员可能会从许多厂商中选择一种线卡,买来插入标准机架。
* 在软件方面,可能会出现一些标准的软件集(操作系统,协议软件栈,管理控制软件等)。系统设计人员将利用这些即插即用的部件组成系统,并且增加一些可以提供不同服务内容的线卡。
如果这些趋向成为现实,标准接口问题将会成为十分重要的课题。例如,为了开发一种以太网的线卡,设计人员可能会选择一种物理层(PHY)芯片、MAC芯片、网络处理器以及并串/串并转换器等(参看附图)来进行设计开发。为了简化设计业务,缩短开发时间,这些芯片必须具有明确清晰的接口,应该使设计人员不需要再花费力气提供连接的逻辑线路,就可以完成任务。
NPU时代
网络处理器将成为网络中各个系统的重要组成部分,但是目前它还不很成熟。它们将在以下几个方面取得重大进步:在它们能够处理的分组的复杂程度和所具有的智能方面;在可以下载的程序规模大小方面;随着线速度的增加在每个时钟周期内能够处理的一个分组或多个分组的综合能力方面。
NPU 的性能正在按照统一的性能指标稳步提高。经过一段时间以后,使用网络处理器来设计开发通信系统的方法学,估计将会和软件的开发一样,也会出现并取得发展进步。