
一种基于SQL语句分发请求的复制算法
2008-05-27
作者:王 巍,李 恪
摘 要: 为适应集群环境下数据量在100GB以下数据库访问频繁和响应速度较高的需要,提出一种架构于Linux虚拟服务器(LVS)基础之上、应用广泛且扩展性强的数据库集群服务器结构,并在复制技术的基础上进行改进,改变复制对象,给出了相应特定的复制算法,并且通过实验验证了系统的可行性。
关键词: 复制 负载平衡 集群 数据库
随着Internet业务量爆炸性的增长,使得传统的单一数据库服务器不堪重负。不断更新的硬件只会使整个系统的代价升高且收效甚微,并且还会造成资源的浪费。由此,基于集群的网络负载平衡策略应运而生并成为有效的新对策。
本文提出了一种构架于Linux虚拟服务器(LVS)基础之上的数据库集群服务器体系结构,用于解决数据量在100G以下且数据库访问频繁和对响应速度要求较高的需求。重点提出了与这种体系结构相对应的基于SQL语句分发请求的复制算法,并通过实验来验证算法的可行性。由于所采用的设备均是普通的PC机和交换机,所使用的系统平台是源码开放的Linux操作系统,并且系统是针对Anycast型[2]任务开发的,可以应用于绝大多数的网站和论坛,所以具有一定的推广价值。
1 数据复制技术
通常,服务器的数据分为两种:一种是结构化的数据库数据,另一种是非结构化或半结构化的文件[4]。这里只讨论结构化的数据库数据。
数据库集群的数据复制包括数据定位和数据更新。对于数据定位,目前有三种方式:
(1)采用分区方式,即对数据库中的数据进行划分操作,其保证了数据操作的高效率,但不能保证数据的高可用性和高可靠性" title="高可靠性">高可靠性。
(2)采用不分区方式,使得数据库在每个节点上都保存有副本,其保证了数据的高可用性和高可靠性,但数据同步困难。本文则是由此切入,提出一种新算法用以解决在保证数据的高可用性和高可靠性的情况下数据同步困难的问题。
(3)上述两者相结合,这样就需要动态的数据分配策略来管理这些数据,当然也可以通过手动管理方式来模拟此过程。
数据更新一般使用即时更新。
对于采取不分区方式的数据定位,其数据更新常用的算法有快照复制、基于主节点的对称复制、基于TOKEN的对称复制和混合复制。这些算法都各有千秋,但它们有一个共同的特点,即都是在节点之间或主节点与从节点之间拷贝数据。人们知道,任何情况下,对数据库的操作无非只有四种:增、删、改、查。对于这种基于负载调度请求的且不能识别请求内容而只把数据库当作文件来操作的算法,不但不能发挥数据库存取数据的优势,同时也为整个集群带来了额外的开销,所以不能说是真正意义上的数据库集群。
2 系统设计
为了保证数据的高可用性和高可靠性,同时又能提高数据更新的效率,充分发挥数据库本身的优势,本文提出一种新的思路,即在LVS基础之上,将其内网中传送的数据包变成SQL语句,通过数据接口,在各个节点机上对其各自拥有数据库进行读写操作。由于所传送的对象不是整块数据而是一条条的SQL语句,使得整个集群减少了更新时间并且增强了负载能力。
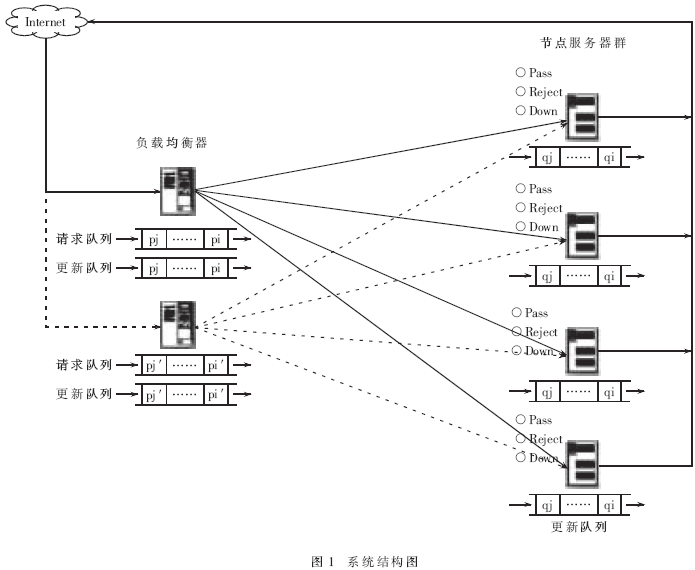
如图1所示,本系统是基于LVS的直接路由模式(DR)来构建的。其采用单工连接方式,节点服务器处理过的应答数据不再经过均衡器" title="均衡器">均衡器,而直接返回给客户端" title="客户端">客户端,这就是说,每个节点服务器都拥有能够到达客户端的合法IP地址,并且负载均衡器" title="负载均衡器">负载均衡器与各节点服务器必须有一块网卡与内网交换机相连。同时,为了使节点间负载平衡、节点内有序执行,在每个节点服务器上都设置有一个队列结构,用于保证操作的顺序性,并且在负载均衡器上设置有两个对列结构用于协调节点间查询和更新的操作。
3 基于SQL语句分发请求的复制算法
复制算法一般包括数据的定位和数据副本的同步两部分,本算法也是如此。
3.1 数据的定位
如上所述,基于本算法的系统结构中所使用的定位技术是基于定位服务器的方式。也就是说,从客户端发出的对数据库操作的任何请求都必须经过定位服务器的分发后,请求才能在节点服务器上得到响应。本系统中,定位服务器就是负载均衡器。
如图2所示,当负载均衡器收到客户端对数据库操作的请求后,首先要进行区分,即是SELECT语句还是非SELECT语句,当请求是SELECT语句时,则通过负载平衡算法[2]选择当前负载最轻的节点,然后将SELECT语句发送到此节点,在节点数据库中进行查询处理后直接将应答数据返回给客户端,而此时的返回数据包的源IP地址仍然是负载均衡器上的VIP地址(这是由LVS的直接路由模式决定的)。
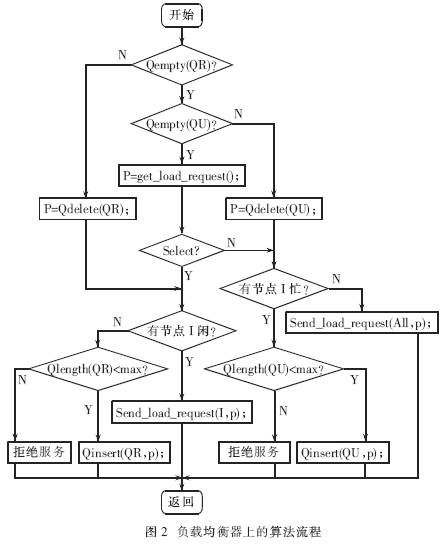
可是,当请求是非SELECT语句时,情况则有所不同,因为所有非SELECT语句均是更新语句,如INSERT、DELECT和UPDATE。此时,负载均衡器通过其所拥有的邻接表查找各节点的MAC地址,然后复制与节点数量相同请求包,再分别封装成帧并改写帧上的MAC地址,使每个节点都成为目的节点,接着将这批帧发送到内网。于是,每个节点服务器都将收到符合自己MAC地址的帧后,拆装、提取SQL信息,在节点数据库中进行数据更新,最后再将更新后的状态信息(如更新成功或失败)直接返回给客户端,同样此时的返回包的源IP地址仍然是均衡器上的VIP。
3.2 数据副本的同步
本系统在进行数据同步时,采用即时更新的同步技术。
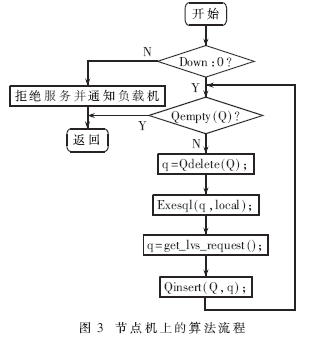
由于数据库集群服务器的数据库都是相对独立的,每台服务器都可以独立承担服务工作,且数据的复制度较高,不存在单点失效的问题,所以节点服务器的工作重点应是数据快速而稳定的存取,保持各节点间数据的一致性。因此,当有请求到达时,无论是查询语句(SELECT语句)还是更新语句(非SELECT语句),都先进入节点机上的操作队列,如图3所示,然后逐一顺序取出执行,这样可以保证对数据库操作的顺序性和一致性。
3.3 复制算法的实现
(1)负载均衡器上邻接状态表,请求队列和更新队列
可以看出,负载均衡器是这个集群系统" title="集群系统">集群系统的核心。均衡器是通过邻接状态表来管理集群中节点服务器的。邻接状态表是由节点名、MAC地址和状态构成。节点名是管理员预先定义的,用于区分各节点机; MAC地址是指节点服务器对应于内网的那块网卡的地址;状态是指当前节点机的状态(0为可操作,1为忙,2为停机)。当有请求到达时,均衡器首先区分请求中的是SELECT语句还是非SELECT语句,若是SELECT语句,则从邻接状态表中查找状态为0的节点,若为0的节点多于一个时,则通过负载平衡算法[2]选出负载最轻的节点进行分配;若是非SELECT语句,均衡器便查找状态不为2(即停机)的节点分发请求,若其中有节点的状态为1(即忙,也就是说此节点服务器上的操作队列已满),则将该语句入均衡器上的更新队列排队,直到所有运行节点均为不忙,才出队分发;若所有运行节点的状态均不为0,此时若带有SELECT语句的请求到达,均衡器便将该语句入请求队列,直到有状态为0的节点出现,才出队进行分发;当均衡器上的请求队列或更新队列均满时,均衡器将拒绝查询请求或更新请求,直到队列不满。
图2中,Qempty(Q)、Qinsert(Q,i)、Qdelete(Q)和Qlength(Q)是对队列的判空、入队、出队和求长度的操作,get_load_request()为取请求函数,send_load_request()为发送请求函数。
(2)节点服务器上的操作队列和信号机制
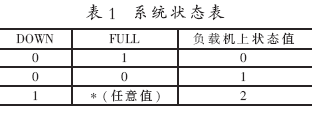
节点服务器的主要工作是对数据库的存取。引入操作队列就是为了保证对数据库操作的顺序性和一致性。这里,需要再引入两个信号量DOWN和FULL,用以监控节点机的状态。DOWN为节点机系统状态(0为正常,1为异常),FULL为操作队列状态(0为队列满,1为队列不满),它们分别与负载均衡器上状态值同步,其对照表如表1所示。
图3中,Qempty(Q)、Qdelete(Q)和Qinsert(Q,q)是对队列的判空、出队和入队的操作,get_lvs_request()为取请求函数,Exesql(q,local)为SQL执行函数。
4 系统实现与测试
4.1 系统实现
本集群系统性能测试环境如下:
(1)基于6+1台PC的集群服务器,即一台作负载均衡器,剩余6台作节点服务器。PC机的基本配置为:CPU PⅢ 900MHz,内存为384MB,硬盘为40GB。
(2)交换机为24Port 10/100Mbps Fast ethernet Switch。
(3)软件配置:
操作系统:Linux 7.2 内核为2.4.18。
集群中间件(SSI):使用JAVA开发的基于SQL语句复制的数据库集群算法。
数据库为:MySql 3.23.49。
网络协议:TCP/IP。
(4)测试软件:WebBench。
4.2 测试与分析
为使测试更具对比性,选用两种算法进行,一种是基于SQL语句复制的算法,另一种是基于快照复制[3]的算法。
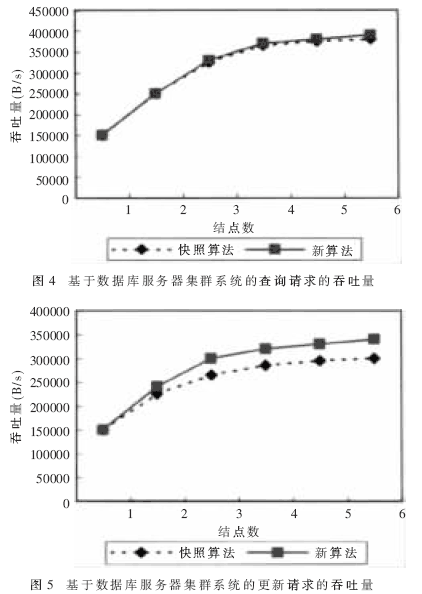
(1)测试基于数据库服务器集群系统的查询请求的吞吐量。
(2)测试基于数据库服务器集群系统的更新请求的吞吐量。
从以上结果可以看出,在测试查询请求的情况下,虽然基于SQL语句复制的算法略高些,但两者相差不是很大,如图4所示。在测试更新请求的情况下,差距很明显,如图5所示,由于基于快照复制算法的系统,所有的更新都在一台主节点上进行,然后再将更新数据分发到其他备份节点。这样,虽然能够保证数据的一致性,但主节点很容易形成新的瓶颈,使得在节点增多的情况下,主节点负载过大。然而,基于SQL语句复制算法的系统,由于所传送的为一条一条的语句,并非整块数据,所以在节点服务器上对其处理的速度就比较快,并且内部的网络传输影响甚小,从而使集群整体的更新速度得到提高。
本文提出了一种新的基于SQL语句请求分发的数据库集群服务器的体系结构,对于研究和开发数据库集群服务器,特别是集群环境中的数据同步管理,具有一定的指导意义和参考价值。
目前系统处于测试阶段,还需要不断完善。例如在网络协议方面,TCP/IP协议虽然是一种很好的协议,但在相对距离较近、且同构的集群系统中,其网络开销自然不容轻视;还有,由于本集群采用的是集中式分配器作为整个上行数据的入口点,所有的负载分配工作都集中在负载均衡器上,当负载均衡器出现故障或负载过重时,将直接影响到整个集群系统的性能;另外,系统的容错性和安全性等问题都需要进一步解决。
参考文献
1 Zegura E W,Ammar M H,Fei Zongming et al.Application-Layer Anycasting:A Server Selection Architecture and Use in a Replicated Web Service.IEEE/ACM Transactions on Net-working,2000;8(4)455-466
2 Hui L,Qinke P,Junyi S.Node-Agents Based Clustered Database Server.Mini-Micro Systems,2003;24(2)225-229
3 邵佩英.分布式数据库系统及其应用.北京:科学出版社,2005
4 Content manage 8.1,IBM.http://www-900.ibm.com/cn/soft-ware/products/db2/index_solution.shtml
5 Shah S.Linux管理员指南.北京:机械工业出版社,2001
6 毛德操,胡希明.Linux内核源代码情景分析.杭州:浙江大学出版社,2001