
Linux2.4与Linux2.6内核调度器的比较研究
2008-05-27
作者:叶 超1,2,郭立红1,邹荣士
摘 要: 调度器" title="调度器">调度器是内核负责分配处理器时间的子系统。本文主要研究并对比了Linux2.4和Linux2.6的调度器,分析了新调度器的不足并提出了改进建议。
关键词: Linux 调度 SMP 处理器亲和性
Linux的内核开发是一个漫长的过程,自2001年11月开发出2.5.0以来,Linux内核的发展十分迅速,作了很多重大的改进,性能也有了很大的提高。内核调度器的改进是最主要的进步之一,本文对比研究了Linux2.4和Linux2.6的调度器,全面剖析了Linux2.6对调度器的改进。
一个成功的调度器的基本要求可以概括为以下三点:
(1)减少花在调度上的时间,以增加花在执行程序上的时间;
(2)在多处理器" title="多处理器">多处理器系统上,保持处理器的负载平衡;
(3)对交互式应用有良好的响应速度。
但是,一个成功的调度器是很难设计好的, 因为一个真正投入运行的系统受到很多因素的制约。相对于Linux2.6,Linux2.4的调度器有很多的不足之处, 2.6版本的Linux内核使用了新的调度器算法,称为O(1)算法,它在高负载的情况下执行得极其出色,并且当有很多处理器时也可以很好地扩展。
O(n)算法,O代表order,括号里的数字代表最坏情况下算法效率的上限取决于算法涉及到的元素的个数,O(1)说明是一个常数,在这种情况下,每次调度的效率是一样的,与涉及的元素的多少没有关系,O(n)表示算法效率取决于算法涉及元素的个数。
1 Linux2.4的调度机制
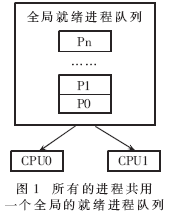
Linux2.4的调度机制可以用下面的" title="面的">面的算法来描述[3],示意图如图1所示。
for(each runnable process on the system) {
find worthiness of this process
if(this is the worthiest process yet) remember it
}
if(the worthiest process′timeslice is zero) recalculate timeslice
else run the most worthy process
所有的就绪进程都在一个全局的就绪进程队列中,这个队列没有任何有意义的排序;时间片重算算法是在所有的进程都用尽它们的时间片以后才重新计算。整个队列由一个读/写自旋锁(read/write spinlock)保护着,这样多个处理器可以并行访问,但同时提供写操作的互斥访问。
由算法可以看出,Linux2.4的调度算法可以说是一个O(n)算法,因为调度器挑选执行进程的开销是随系统中就绪进程的增长而线性增长的[1]。同时,当系统中有多个处理器时,访问就绪进程队列就成了瓶颈,性能也会显著的下降。因而有很多的缺点:
(1)每次调度时,调度器都要线性遍历" title="遍历">遍历这个队列,以找出最值得运行的进程执行:当系统负载很高的时候,可执行进程队列会很长,线性搜索的时间是线性增长的,这个时间会很长,当这个时间足够长的时候,有可能出现多个处理器选择了同一个进程的情况,这样,有些处理器会发现,他选择的进程已经分配了其他的处理器,而不得不重新选择,甚至出现选择运行进程的时间比实际执行进程的时间还要长的情况。
(2)当大多数的就绪进程的时间片都用完而又还没有重新分配时间片的时候,SMP系统中有些处理器处于空闲状态,这将影响SMP的效率。
(3)当空闲的处理器开始执行那些时间片尚未用尽而处于等待状态的进程(如果它们自己的处理器忙)时,会导致进程开始在处理器之间“跳跃”,实时进程或者占用内存大的进程在处理器之间跳跃会严重影响系统的性能。
(4)在一个有很多处理器的系统中,当进程用完它们的时间片以后需等待重算,以得到新的时间片,从而导致大部分的处理器处于空闲状态;这将影响SMP的效率。
因此,不难看出当系统中有大量的可执行进程时,选择一个进程去执行可能要花费较长的时间,系统中有多个处理器的时候,难度就更大了,这种调度,在多处理器或者系统负载比较高的情况下,性能受到影响。
2 Linux2.4调度器性能低下的原因
从上面的分析可以看出,造成Linux2.4调度器性能低下的主要原因如下:
(1)系统中调度算法属于O(n),开销是线性增长的;
(2)只有一个全局的就绪进程队列,对多处理器的伸缩性支持不好;
(3)处理器的亲和性不好,容易导致进程在处理器之间“跳跃”;
(4)时间片的重算循环制约了多处理器的效率。
Linux2.6做了很大的改进,它采用O(1)算法,它在高负载的情况下执行得极其出色,并且当有很多处理器时也可以很好地扩展,不但大大改善了对SMP的支持,同时也兼顾了单CPU或者双CPU系统的要求。
3 Linux2.6调度器的改进目标
为了改善Linux2.4的上述不足,linux2.6的调度器可以通过提供下列新的特性来改善调度器的性能:
(1)提供完全的O(1)调度算法,也就是说,不管系统中进程数量的多少,调度器中所有的算法都必须在常数时间内完成。
(2)应该对SMP有良好的可伸缩性,理想情况下,每个处理器应该有独立的可执行进程队列和锁机制。
(3)应该提高SMP 的处理器亲和性,但是同时也应该有在负载不平衡" title="不平衡">不平衡的时候在处理器间迁移进程的能力。
4 Linux2.6的调度机制
新的调度器都实现了这些目标,具体方法是,基于每个 CPU 来分布时间片,并且取消了全局同步和重算循环[2]。
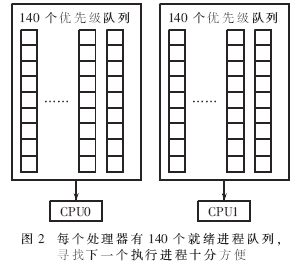
每个进程有两个数组,活动就绪进程队列数组和不活跃就绪进程队列数组。每个数组中有140个就绪进程队列(runqueue),每个队列对应于140个优先级的某一个。由一个位图来指示哪些队列是空的,哪些不是空的,每个队列都是先进先出的(FIFO)。这样,在挑选进程的时候,只要通过find_first_bit找到第一个不为空的队列,并取队首的进程就可以了。
如果一个进程消耗完了它的“时间片”,就进入不活跃就绪进程数组的相应队列的队尾。当所有的进程都“耗尽”了它的“时间片”后,交换活跃与不活跃就绪进程队列数组的指针就可以了,不需要任何其他的开销。
这样,不管队列中有多少个就绪进程,挑选就绪程的速度是一定的,所以称为O(1)算法,该算法可描述如下,示意图如图2所示。
get the highest priority level that has processes
get first process in the list at that priority level
run this process
这个算法有很多的优点,简述如下:
(1)每个处理器都有独立的就绪进程队列,各个处理器可以并行地运行Scheduler程序来挑选进程运行,不同处理器上的进程可以完全并行地休眠、唤醒和上下文切换。
(2)进程只映射到一个处理器的就绪进程队列中,不会被其他的处理器选中,因而也就不会在不同的处理器之间跳跃。
当然,处理器有时确实需要在处理器之间迁移进程,例如负载不平衡的时候,每个处理器每200ms检查一次其他的处理器是不是处在负载不平衡的状况下,就绪进程队列为空的处理器会每1ms检查一次。
但是这种情况并不是频繁的发生,所以处理器的亲和性基本能得到保证。
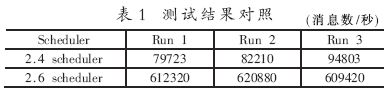
新的调度器的性能确实有很大提高,一个服务器在多个处理器间传送大量的消息的测试结果如表1所示。从表中可以看出,使用新的调度器,在同样的时间内系统能作更多的事情。
5 Linux2.6调度器的不足
新的调度算法在以下几个方面有待改进。
首先,尽管处理器的速度在很快的发展,但是存储体系的速度发展却是相对比较缓慢,对存储器的操作时间往往形成瓶颈。
调度器给处理器分配进程的时候应该考虑进程的相关性。考虑这样的一种情况:两个进程频繁的通过管道或者共享内存通信,测试表明,它们在同一个处理器上工作会更好,因为不用涉及到把数据从一个处理器的cache里拷贝到另一个处理器的cache里。而目前的调度器不能保证将这样有着密切联系的进程分配到同一个处理器上。同样的问题也存在于设备的相关性。
其次,仍是进程迁移问题,因为在处理器间迁移不同进程的代价是不尽相同的,所以在迁移进程的时候,应该适当考虑进程的特点。
迁移进程的时应考虑进程的大小(这里是指占有内存资源的大小),迁移进程的时候,并没有考虑到进程占用内存的大小,迁移大的进程到其他的处理器会较严重的影响系统的性能。试想出现这样情况:处理器A把它惟一的大进程迁移到了处理器B,而处理器B上的所有进程都是大进程,存储资源原本就紧张,这样一来,处理器A上的进程存储资源就很丰富,而处理器B 则更加糟糕。目前,Linux2.6调度器在迁移进程的时候还没有考虑进程的大小。
最后,当系统检测到需要迁移进程以平衡负载的时候,是不是真的非平衡负载不可呢?当系统的负载不平衡且很轻微的时候,是不一定需要平衡负载的。假设有这样情况:有六个进程要求同时执行完毕,但是系统中只有四个处理器。这样,总有两个处理器有两个进程,而其他两个处理器只有一个进程。这就出现问题,因为系统总是不平衡的,导致总有进程在同处理器间迁移,这也就形成了跳跃。
6 对Linux2.6调度器的几点改进建议
同一个任务队列的进程和同一家族的进程尽量映射到同一个处理器上,因为这些进程之间需要频繁通信的可能性是最大的;还可以动态地调整进程与处理器的映射,当监测出两个处在不同的处理器上的进程频繁通信的时候,就利用每200ms检查负载平衡的计划将它们调整到同一个处理器上。
可以在每个进程的就绪进程位图中存储一些大进程的标志信息,跟本处理器中大进程占的比重来迁出或者迁入大进程。
设置一个调节负载平衡的处理器负载阈值load_threshold,在load_balance函数中检查系统欲调节负载的处理器的实际负载,没有超过事先给定的 threshold,就不对这个处理器作真正意义上的负载平衡调节。
参考文献
1 毛德操,胡希明.Linux内核源代码情景分析.杭州:浙江大学出版社,2001
2 Hagen W.Real-Time and Performance Improvements in the 2.6 Linux Kernel.Linuxjornal#134,2005;(6)
3 Love R.Introducing the 2.6 Kernel.Linuxjornal,#109,2003;(5)