
集群虚拟服务器的仿真建模研究
2008-06-05
作者:杨建华1,金 笛2,李 烨2
摘 要: 阐述了集群虚拟服务器的工作原理和三种负载均衡方式,通过实例讨论了虚拟服务器的仿真和建模方法,创建了测试和仿真系统性能的输入和系统模型,并依据Q-Q图和累积分布函数校验了其概率分布。
关键词: 集群 虚拟服务器 负载均衡 仿真 建模 概率分布
随着互联网访问量和数据流量的快速增长,新的应用层出不穷。尽管Internet服务器处理能力和计算强度相应增大,但业务量的发展超出了先前的估计,以至过去按最优配置建设的服务器系统也无法承担。在此情况下,如果放弃现有设备单纯将硬件升级,会造成现有资源的浪费。因此,当前和未来的网络服务不仅要提供更丰富的内容、更好的交互性、更高的安全性,还要能承受更高的访问量,这就需要网络服务具有更高性能、更大可用性、良好可扩展性和卓越的性价比。于是,集群虚拟服务器技术和负载均衡机制应运而生。
集群虚拟服务器[1]可以将一些真实服务器" title="真实服务器">真实服务器集中在一起,组成一个可扩展、高可用性和高可靠性的统一体。负载均衡[2]建立在现有网络结构之上,提供了一种廉价、有效和透明的方法建立服务器集群系统,扩展网络设备和服务器的带宽,增加吞吐量,加强网络数据处理能力,提高网络的灵活性和可用性。使用负载均衡机制,大量的并发访问或数据流量就可以分配到多台节点设备上分别处理。系统处理能力得到大幅度提高,大大减少用户等待应答的时间。
实际应用中,虚拟服务器包含的真实服务器越多,整体服务器的性能指标(如应答延迟、吞吐率等)越高,但价格也越高。在集群中通道或其他部分也可能会进入饱和状态。因此,有必要根据实际应用设计虚拟服务器的仿真模型" title="仿真模型">仿真模型,依据实际系统的测量数据确定随机变量" title="随机变量">随机变量的概率分布类型和参数,通过分位点-分位点图即Q-Q图(Quantile-Quantile Plot)和累积分布函数(Cumulative Distribution Functions)等方法校验应答或传播延迟" title="传播延迟">传播延迟等性能指标的概率分布,通过仿真软件和工具(如Automod[3])事先分析服务器的运行状态和性能特点,使得集群系统的整体性能稳定,提高虚拟服务器设计的客观性和设计的可靠性,降低服务器建设的投资风险。
1 集群虚拟服务器的体系结构
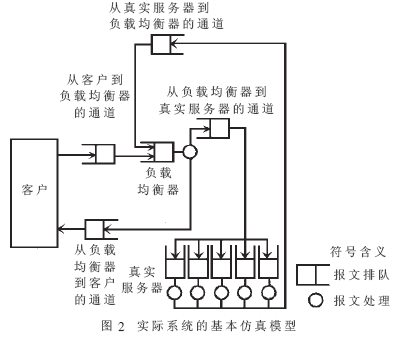
一般而言,首先需要在集群虚拟服务器上建立互联网协议伪装(Internet Protocol Masquerading)机制,即IP伪装,接下来创立IP端口转发机制,然后给出在真实服务器上的相关设置。图1为集群虚拟服务器的通用体系结构。集群虚拟服务器通常包括:真实服务器(Real Servers)和负载均衡器" title="负载均衡器">负载均衡器(Load Balancer)。

由于虚拟服务器的网络地址转换方式是基于IP伪装的,因此对后台真实服务器的操作系统没有特别要求,可以是Windows操作系统,也可以是Linux或其他操作系统。
负载均衡器是服务器集群系统的惟一入口点。当客户请求到达时,均衡器会根据真实服务器负载情况和设定的调度算法从真实服务器中选出一个服务器,再将该请求转发到选出的服务器,并记录该调度。当这个请求的其他报文到达后,该报文也会被转发到前面已经选出的服务器。因为所有的操作都在操作系统核心空间中完成,调度开销很小,所以负载均衡器具有很高的吞吐率。整个服务器集群的结构对客户是透明的,客户看到的是单一的虚拟服务器。
负载均衡集群的实现方案有多种,其中一种是Linux虚拟服务器LVS(Linux Virtual Server)方案。LVS实现负载均衡的技术有三种:网络地址转换(Network Address Translation)、直接路由(Direct Routing)和IP隧道(IP Tunneling)。
网络地址转换按照IETF标准,允许一个整体机构以一个公用IP地址出现在Internet上。通过网络地址转换,负载均衡器重写请求报文的目标地址,根据预设的调度算法,将请求分派给后端的真实服务器;真实服务器的应答报文通过均衡器时,报文的源地址被重写,把内部私有网络地址翻译成合法网络IP地址,再返回给客户,完成整个负载调度过程。
直接路由的应答连接调度和管理与网络地址转换的调度和管理相同,但它的报文是直接转发给真实服务器。在直接路由应答中,均衡器不修改、也不封装IP报文,而是将数据帧的媒体接入控制MAC(Medium Access Control)地址改为选出服务器的MAC地址,再将修改后的数据帧在局域网上发送。因为数据帧的MAC地址是选出的服务器,所以服务器肯定可以收到该数据帧,从中获得该IP报文。当服务器发现报文的目标地址在本地的网络设备时,服务器处理该报文,然后根据路由表应答报文,直接返回给客户。
IP隧道是将一个IP报文封装在另一个IP报文中的技术。该技术可以使目标为某个IP地址的数据报文被封装和转发到另一个IP地址。用户利用IP隧道技术将请求报文封装转发给后端服务器,应答报文能从后端服务器直接返回给客户。这样做,负载均衡器只负责调度请求,而应答直接返回给客户,不需要再处理应答包,将极大地提高整个集群系统的吞吐量并有效降低负载均衡器的负载。IP隧道技术要求所有的服务器必须支持IP Tunneling或IP封装(Encapsulation)协议。
2 集群虚拟服务器报文延迟的确定
通过一个装有5台真实服务器并使用网络地址转换技术实现Linux虚拟服务器的实际系统[4],可以得到有关请求和应答报文的时戳(Time Stamp)文件。根据这些文件,能够计算出集群虚拟服务器的仿真和建模所需数据。
为了确定随机变量分布类型和参数,应该统计下列延迟:(1)从客户到负载均衡器的传播延迟(Transport Delay);(2)负载均衡器的应答延迟(Response Delay);(3)从负载均衡器到真实服务器的传播延迟;(4)真实服务器的应答延迟;(5)从真实服务器到负载均衡器的传播延迟;(6)负载均衡器对真实服务器的应答延迟;(7)从负载均衡器到客户的传播延迟。
在实际系统产生的时戳文件中,间接地描述了上述各延迟时间。文件包含的内容如下:
……
192.168.3.202 //IP地址
53295 //端口
1022834955.914398316 //时戳(秒)
1 //报文类型
2072754558 //序列号
192.168.3.202
53295
1022834955.914424877
4
2081793697
……
当一个服务请求到达集群虚拟服务器系统时,即产生带有惟一序列号的同步请求报文(Synchronized Request Package),将该报文转发到某一真实服务器,同时建立该服务器与客户端的连接,每个这样的连接都带有惟一的端口号;该服务器处理通过该连接的确认请求报文(Acknowledgement Request Package),直到服务器收到结束请求报文(Finished Request Package)。对每一种类型的请求报文,系统都给予一个相应的应答报文。因此,在不同的报文时戳文件中,如果两条记录具有相同的端口号、报文类型和序列号,则它们是同一个请求或应答报文,对相关的时戳相减即可得到集群虚拟服务器系统的仿真和建模所需的延迟数据。通过所编写的C++程序即可计算这些延迟。
3 系统仿真模型
上述的集群虚拟服务器实际系统的仿真模型如图2所示,在负载均衡器、各通道、5台真实服务器中通过或处理的均为请求或应答报文。
4 随机变量模型的确定
对具有随机变量的集群虚拟服务器进行仿真,必须确定其随机变量的概率分布,以便在仿真模型中对这些分布进行取样,得到所需的随机变量。
4.1 实际虚拟服务器的延迟数据概况
在实际虚拟服务器的负载均衡器、各通道和5台真实服务器中,对请求和应答报文都有一定的延迟。部分报文延迟的统计数据如表1所示。
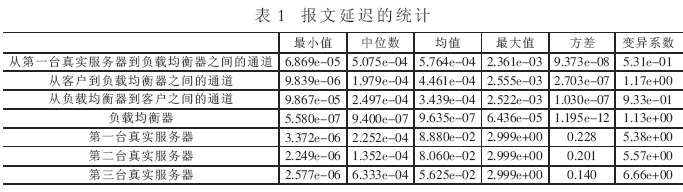
由表1中的数据可见,报文延迟的中位数与均值差异较大,所以其概率分布不对称;变异系数不等于1,导致概率分布不会是指数分布,而可能是γ分布或其他分布。
4.2 随机变量的概率分布
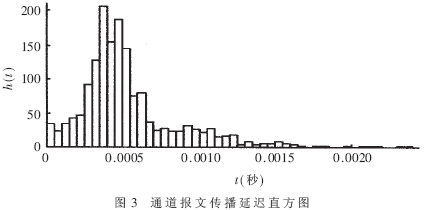
图3为第一台真实服务器到负载均衡器之间的通道报文传播延迟直方图,其中t为报文延迟时间,h(t)为报文延迟区间数。由图3可知,通道内的报文传播延迟数据近似服从γ分布或对数正态分布[5]。
描述γ分布需要两个参数:形状(Shape)参数α和比例(Scale)参数β,这两个参数与均值M、方差V之间的关系是非线性的:
M=αβ (1)
V=αβ2 (2)
描述对数正态分布也需要形状参数σ和比例参数μ,这两个参数与均值M、方差V之间的关系也是非线性的:

式(1)~(4)都可以通过最大似然估计MLE(Maximum Likelihood Estimator)方法[5]或最速下降法(Steepest Descent Method)求出。表2给出了用这两种方法求出的从第一台真实服务器到负载均衡器之间通道内的报文延迟概率分布参数。

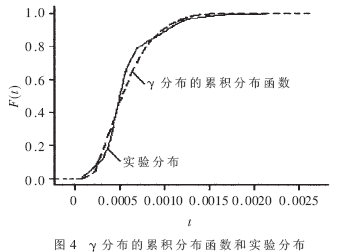
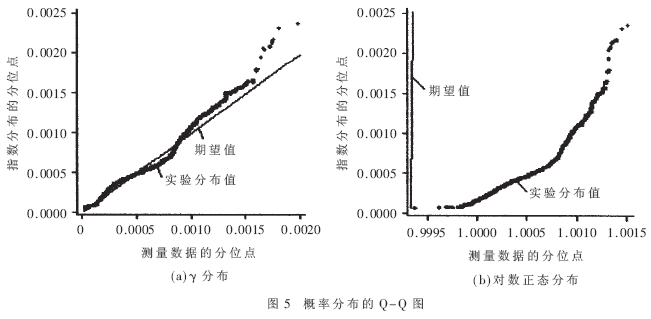
使用累积分布函数和Q-Q图可以校验并进一步确定上述通道内报文传播延迟的概率分布。取用表2中的参数,可以得到γ分布的累积分布函数,如图4所示,其中t为报文延迟时间,F(t)为报文延迟的累积分布函数。为作比较,实验分布也画在该图中。γ分布和对数正态分布的Q-Q图如图5所示。
由图4和图5可以看出,γ分布较好地拟合了该通道内的报文传播延迟数据分布。其他通道报文延迟直方图也有类似形状。经计算和分析,这些通道的报文传播延迟概率分布也近似服从γ分布。
根据表1中的数据以及相关的直方图都难以确定在负载均衡器和真实服务器中报文延迟的理论分布,因此,采用实验分布[6]作为其模型。
5 模型仿真
在建立了图1所示的集群虚拟服务器的系统仿真模型并确定了其随机变量的分布特性后,可以采用由美国布鲁克斯自动化公司(Brooks Automation)开发的仿真软件Automod输入该模型,并通过在Automod环境中编程进行集群虚拟服务器的仿真和分析。
在Automod的仿真过程中,可以直接利用软件提供的资源(Resource)作为各种报文数据处理的单元;系统各部分的报文排队活动可以直接通过排队(Queue)实现;建立一个负载产生器,等效为在Internet上使用虚拟服务器的客户。
通过采用Automod的属性变量(Attribute Variable)可以解决负载均衡器的双方向报文处理功能的问题。负载均衡器使用轮转调度算法(Round Robin Scheduling),即假设所有真实服务器的处理性能均相同,依次将请求调度到不同的服务器。
验证仿真模型可以分别在实际虚拟服务器系统和Automod的仿真模型中从以下两方面进行对比:(1)在负载均衡器、各个真实服务器和通道中排队的应答或传播报文数量;(2)真实服务器及负载均衡器的CPU利用率。例如,当使用实际的应答或传播报文延迟数据时,在Automod的仿真模型中,如果设置一个较低的资源量,则在仿真过程中就会发现大部分的负载都被堵在真实服务器的排队中,即真实服务器处理报文的能力过低,无法与实际系统的状况相比;如果设置一个较高的资源量,则意味着服务器的并行处理能力增加,真实服务器的利用率提高,负载就很少或不会滞留在真实服务器的排队中。因此,在Automod中可以根据实际情况调整仿真模型的资源量大小。
如果在Automod中增加负载产生器的负载产生率,就等效为用户访问量增加,通过观察排队中的负载滞留比例,就可以发现系统的最大处理报文的能力以及系统各部分应答报文可能出现瓶颈之处。例如,将负载产生率增加一倍,虽然系统仍然可以处理所有的报文,但各台真实服务器的平均利用率将达80%左右。显然,这时系统应答报文的“瓶颈”为真实服务器,有必要在系统中增添一台新的真实服务器。
通过一个包括5台真实服务器的实际虚拟服务器系统,收集并计算了仿真和建模的样板数据。依据系统报文延迟的中位数、均值、变异系数和直方图等,确定了系统随机变量的概率分布;采用最大似然估计方法和最速下降法,得到了通道概率分布的具体参数;根据Q-Q图和累积分布函数进一步校验并最终确定通道的概率分布形式。使用Automod软件进行了仿真建模和编程,借助仿真结果可以发现虚拟服务器的最大处理能力和可能的“瓶颈”之处。通过及时定位系统“瓶颈”,可以有的放矢地进一步研究和改进系统,有效提高系统性能。所采用的仿真方法也可以用于其他领域的仿真建模或分析中。
在仿真模型中,负载均衡方式和调度算法还需要进一步增加,以便于比较不同的虚拟服务器系统。样本数据也需要进一步扩充,以避免报文延迟的自相关性。
参考文献
1 Schroeder T,Goddard S,Ramamurthy B.Scalable web server clustering technologies[J].IEEE Network,2000;14(3):38~45
2 Yong M T,Ayani R.Comparison of load balancing strategies on cluster-based web servers[J].Simulation,2001;77(5):185~195
3 Nikoukaran J.Software selection for simulation in manufac-turing:A review[J].Simulation Practice and Theory,1999;7(1):1~14
4 Chepurko A.Instrumenting a cluster-based web server for performance measuring[D].Erlangen-Nuremberg University,2002
5 Law A M,Kelton W D.Simulation modeling and analysis (Third Edition)[M].McGraw-Hill Inc,2000
6 肖田云,张燕云,陈加栋.系统仿真导论[M].北京:清华大学出版社,2000