
前言
在目前的安全、数通及电信等诸多领域都可以看到基于多核处理器的设计,它们超强的处理能力使得以往繁复的系统得以减小体积,实现单板平台。然而,在享受处理性能提升的同时,结构设计人员却不得不忍受多核高功耗的折磨,动辄几十瓦甚至上百瓦的功耗成为多核进入更多领域的一个瓶颈。在目前绿色环保的政策下如何实现机房或设备的低功耗成为系统工程师必须考虑的一个重要设计因素。随着多核集成CPU数量的不断增加,单纯靠芯片工艺和代码优化来降低功耗越来越难,此时必须要从电路系统设计的角度来全盘考虑问题。
多核处理器在数据处理过程中的密集运算使得芯片的动态功耗不断增加,因此可将处理器的一部分负荷卸载到专用加速器中,以此来降低核心芯片的功耗。一方面它可以容许处理器工作在较低的频率上,大幅降低系统的总功耗,另一方面还可以通过释放处理器来提升整个系统的性能,或者增加高附加值的应用;最后还可以降低对处理器的要求,同时降低系统的BOM成本。
目前安全领域的DPI检测就是一个计算密集型应用,它要求扫描整个数据包,计算开销非常大。现有网络设备在实现此功能时大多采用软件方案,在独占一个CPU核的情况下也只能达到Mbps的处理能力。实验表明,通过加入LSI公司的Tarari DPI专用芯片可以使系统功耗大幅降低,而处理能力可提升至Gbps。本文将以Tarari为例介绍DPI技术以及相关实现。
DPI技术及芯片介绍
DPI (Deep Packet Inspection),即“深度报文检测”。所谓“深度”是和普通的报文分析层次相比较而言的,“普通报文检测”仅分析IP包的4层以下的内容,包括源地址、目的地址、源端口、目的端口以及协议类型,而DPI 除了对前面的层次分析外,还增加了应用层分析,识别各种应用及其内容,基本概念如图1所示。
|
|
|
图1 DPI的基本概念 |
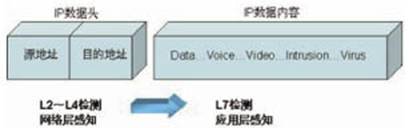
普通报文检测是通过端口号来识别应用类型的。如检测到端口号为80时,则认为该应用代表着普通上网应用。而当前网络上的一些非法应用会采用隐藏或假冒端口号的方式躲避检测和监管,造成仿冒合法报文的数据流侵蚀网络。此时采用L2~L4层的传统检测方法已无能为力了。DPI 技术就是通过对应用流中的数据报文内容进行探测,从而确定数据报文的真正应用。因为非法应用可以隐藏端口号,但目前较难隐藏应用层的协议特征。
Tarari系列芯片是实现上述功能的一款硬件加速器,它支持行业内标准的正则表达式,规则数可以达到上百万条,支持POSIX和PCRE。针对安全应用中所需的跨包检测,Tarari可以对400多万条数据的上下文进行处理。处理跨包的过程中Tarari会用内部缓存来自动记录跨包的上下文,包括正则表达式搜索树的状态、前一包的部分内容以及所选的指令。该系列芯片从第四代产品(T9000)开始采用ASIC设计,第五代产品则开始采用T10架构,产品目前包括T1000和T2000两个系列型号。各芯片间软件兼容,提供从250Mbps到10Gbps不同的速度等级,以满足不同应用的需求。
以T2000系列芯片为例,它外围存储采用低成本的DDR2 SDRAM芯片,无需TCAM或者RLDRAM等昂贵存储器。为了满足某些高性能场合的需求,T2000也提供扩展接口,方便实现性能升级。在系统接口方面T2000提供PCI、PCI Express等高速接口,每个PCIe通道都具有Gbps的有效吞吐能力,最高可以达到16Gbps。T2000最高可支持10G的单片峰值性能,通过级联两片T2000芯片可以提供16Gb/s的吞吐量。T2000 软件可同时监测多达四块16Gb/s PCIe电路板并提供负载均衡,从而为最苛刻的网络环境提供64Gb/s 的性能。T2000系列芯片的体积只有29mm*29mm,典型功耗为5W。
基于多核处理器的DPI平台设计
硬件平台设计
无论是Intel和AMD的x86架构,还是MIPs架构,无论是CISC还是RISC,Tarari都可以很好的支持这些主流的处理器技术。
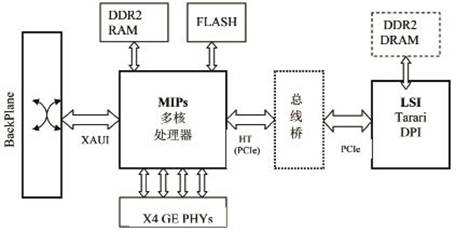
以某公司基于MIPs的多核芯片为例,图2所示为Tarari芯片与MIPs多核的设计框图。由于 Tarari芯片具有PCI、PCI-X以及PCIe接口,因此Tarari可以通过这些接口与满足条件的多核处理器直接对接。对于很多高速应用,如果PCIe接口类型不匹配,也可以在PCIe与处理器间搭接PCIe与其它接口的转换桥片。对于低速应用,Tarari可以实现无RAM操作,即无需外围的DDR2芯片,通过内部存储器就可以实现数据处理。
图2所示电路的工作流程如下:当有数据包从GE接口进入MIPs多核处理器,处理器会通过PCIe接口或者HT桥片将其送入Tarari内容处理器,此时Tarari会通过内部的多个引擎对数据与规则集进行比对匹配,因为匹配规则在处理期间已经调入Tarari芯片的内部缓存,并且数据在处理过程中并不会进行任何形式的存储,所以匹配过程延时很小。匹配结束后,评估结果同样经过PCIe或者HT总线送回处理器,上层软件根据结果来决定对报文的处理。
|
|
|
图2 基于MIPs多核的DPI平台设计 |
规则集编写及调用
Tarari支持丰富的正则表达式语言和各种常用结构,可以在确定速度的情况下并行处理超过100万条规则,它通过专利技术综合了DFA和NFA的优点,支持各种复杂的正则表达式。
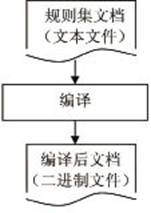
如图3所示,正则表达式内容处理的第一步是编译规则集,然后将其调入Tarari硬件系统。规则集可以一次全部编译,也可以只编译更新部分,即增量编译。被编译的规则文本文件在编写时需要符合语法,编译结果是一个可以被调入Tarari硬件系统的二进制文件。
|
|
|
图3 规则集的编译过程 |
全部编译的好处是可以进行字符级的压缩,对于许多应用来讲,这意味着可以大幅减小编译输出的二进制文件大小,特别是对于诸如反垃圾邮件等基于文本的应用,全部编译同增量编译相比可以减小编译结果。字符集压缩必须要检索起始状态条件下的所有规则。因此,某一个规则的更新就会改变二进制指令在所有规则集上的生成方式。所以在这种模式下任一规则的更新都会要求所有的规则被重新编译。
IDS/IPS类应用倾向于将8比特字符的256个可能数值都明确地用规则表示出来,因此字符集压缩对此类应用来讲作用较小,所以适合采用增量编译。采用增量编译的优势在于不会特别增加字节数。另外,为了进行包分类,这类应用通常使用很多的起始状态条件,这也适合采用增量编译。有起始状态条件的规则集使用增量编译因为不需进行字符集压缩,所以可减小第一次的编译时间;依赖于规则改变的数目和复杂度,第二次以及随后的编译时间也会大幅缩短;并且减小了存储记录的需求。
如果规则集没有起始条件,那么最好还是使用全部编译的方式,因为全部编译具有字符集压缩的优势。
DPI在UTM平台上的应用
目前企业网都面临着入侵防御、防病毒和防垃圾邮件等三个主要的安全问题,UTM的出现使得通过一台设备来解决上述安全问题成为可能。但这同时也带来了性能瓶颈,因为对不间断的数据流进行处理,并根据不同的恶意威胁对包进行深度扫描的计算量非常庞大,即使是多核平台也很难达到预定性能。在这种情况下,专用的加速引擎Tarari就可以帮助UTM设备在安全能力和处理性能间达到均衡。
Tarari可以从主处理器上卸载内容处理任务,利用专用硬件来加速评估过程,最后再将评估结果送回主处理器上的安全应用程序。
对于入侵防御,UTM设备可以检测输入报文的所有内容,并将内容提交给Tarari的正则表达式处理引擎,由它来加速与攻击模式的比较过程。匹配结果返回主处理器后,入侵防御应用程序会决定如何来处理攻击包。
对于防病毒保护,数据流以文件形式通过UTM设备进入正则表达式引擎,引擎在线速情况下会将文件与病毒特征数据库进行评估匹配,并对可疑内容进行启发分析。评估结束后,主处理器上的防病毒应用程序就可以对感染文件进行预定处理。
对于防垃圾邮件应用,输入流作为Email通过UTM设备接入正则表达式引擎,引擎会将内容图案与垃圾邮件特征数据库进行评估对比,识别出问题信息。主处理器上运行的反垃圾邮件应用程序读出返回值后可以应用不同策略来处理这些信息。
当UTM平台有了Tarari的加速,它可以真正实现对数据报文、信息和文件的深度检测,以对网络提供安全保护。
总结
通过软件的方式也可以实现DPI检测功能,但这种方式性价比较低,功耗较高。比如在3GHz的Xenon四核平台上,每核只能实现60Mbit/s的吞吐量,而此时功耗为90W;采用最低端的T1000芯片可以实现250Mbit/s的吞吐量,而功耗不足2W。
Tarari与软件方式相比还有一个明显的优势,在于它基于硬件的跨包检测能力,相对于用软件来检测跨包威胁,比如入侵、恶意攻击等,Tarari的硬件处理速度远远超出了软件的处理速度。
Tarari芯片内部检测引擎的理论处理速度超过目前芯片的I/O吞吐率,因此,这些额外的处理能力使得LSI公司有能力在不远的将来推出更快更高效的产品。目前T1000系列芯片LSI采用了90nm工艺技术,随着LSI向65nm工艺的推进,Tarari系列的功耗将会更低,处理性能将会得到更大的释放。