
基于H.264帧间预测解码的研究及高效VLSI实现
2008-07-03
作者:杨海池,宋 锐,吴成柯,冯晓茹
摘 要: 在深入研究H.264帧间预测" title="帧间预测">帧间预测技术的基础上,采用三级流水线实现帧间预测解码的VLSI设计,并详细介绍了基于宏块" title="宏块">宏块分割的变块自适应循环控制单元,针对存储器的读写问题提出了一种交织存取方式,针对分像素插值" title="插值">插值提出了一种基于H.264标准的插值运算电路。通过仿真及在H.264解码器中的实际应用和测试,证明该设计工作稳定,能够满足H.264标准基本框架下4CIF格式图片30fps(帧/秒)实时解码的要求。
关键词: 帧间预测 VLSI设计 变块大小自适应 交织存取 插值运算
H.264[1]是联合视频工作组JVT(Joint Video Team)开发的最新一代视频压缩标准。与标准MPEG-2、MPEG-4和H.263相比,其总体结构为基于增强的运动估计" title="运动估计">运动估计与补偿加变换编码的混合(hybrid)编码模式,包含了许多新特征:如VCL层和NAL层分离、帧内预测、高精度运动估计、可变块大小运动补偿、多参考帧运动补偿预测、低复杂度16bit的整数变换和量化、去块效应滤波器和高效的熵编码等。这些新特征使得H.264/AVC能够显著提高编码效率且具有网络友好性,可有效用于各种网络和应用环境[2]。
作为视频压缩的关键技术之一,具有运动估计与补偿的帧间预测技术主要是利用连续图像之间的相关性,采取运动估计与补偿的方法来消除时间上的冗余。H.264解码代码的复杂度分析结果显示,计算量最大的部分是帧间预测模块、帧内预测模块和去块效应滤波模块。但这些部分的控制方式相对简单,适合用硬件来实现。本文在深入研究H.264帧间预测技术的基础上,尽量降低硬件资源损耗,采用三级流水线实现帧间预测解码的VLSI设计。
1 帧间预测技术研究
H.264帧间预测是利用已编码视频帧或场和基于块的运动补偿预测模式。与以往标准帧间预测不同的是,H.264增加了许多新功能[3],主要包括四个方面:
(1)可变块大小运动补偿:每个宏块(16×16像素)的亮度,可以按4种方式进行分割:1个16×16,或2个16×8,或2个8×16,或4个8×8,其运动补偿也相应有4种。而8×8模式的每个子宏块可以继续分割:1个8×8,或2个4×8,或2个8×4,或4个4×4。这种分割下的运动补偿,称为树状结构运动补偿。这些分割和子宏块大大提高了各个宏块的关联性。一般来说,小块可以提高预测的效果。
宏块的色度成分(Cr和Cb)则为相应亮度的一半(水平和垂直各一半)。色度块采用和亮度块相同的分割模式,只是尺寸减半(水平和垂直方向都减半)。例如8×16的亮度块其相应的色度块尺寸为4×8。
(2)高精度的运动补偿:帧间编码宏块的每个分割或子宏块都是对参考图像的某一相同尺寸区域进行预测得到的。两者之间的差异(MV),对亮度成分采用1/4像素精度,色度1/8像素精度。亚像素位置的亮度和色度像素并不存在于参考图像中,需要利用临近已编码点进行内插" title="内插">内插得到。
MV可由临近已编码分割的MV预测获得。预测矢量MVp基于已计算的MV和MVD(预测与当前的差异),并被编码和传输。MVp取决于运动补偿的尺寸和临近MV的有无。
(3)多参考帧运动补偿:H.264支持多参考帧预测(multiple reference frames),即可以有多于1个、最多5个在当前帧之前解码的帧作为参考帧产生对当前帧的预测。这适用于视频序列中含有周期性运动的情况。较之只使用1个参考帧,使用5个参考帧可以节省码率5~10%。采用这一技术,可以改善运动估计的性能,提高H.264解码器的错误恢复能力,但同时也增加了缓存的容量以及编解码器的复杂性。不过,H.264的提出是基于半导体技术的飞速发展,因此这两个负担在不久的将来会变得微不足道。
(4)去块效应滤波:基于块的视频编码在图像中存在块效应,主要来源于帧内和帧间预测和残余编码。去块效应滤波器(Deblocking Filter)的作用是消除经反量化和反变换后重建图像中由于预测误差产生的块效应,即块边缘处的像素值跳变,从而改善图像的主观质量,减少预测误差。在去块效应滤波时,应该根据图像内容判断是图像的真实边界还是方块效应所形成的边界(假边界)。对真实边界不进行滤波处理,而对假边界则根据周围图像块的性质和编码方法采用不同强度的滤波。
2 帧间预测解码硬件实现
在本次H.264解码设计中,解码架构采用DSP+FPGA协同处理,DSP主要负责完成slice_data前所有处理过程,包括序列参数集、图像参数集及片头的句法元素的解析以及码流的处理,并存储片层及宏块层要解析的码流,承担整个解码器的协调和控制。而FPGA负责完成片层及宏块层各句法元素的解析,以及后续的解码重建,如帧间预测、帧内预测、反量化/变化、CAVLC解码及去块滤波等,充分利用了DSP和FPGA的优势[4]。
本文设计的帧间预测解码整体框图如图1所示,主要包括MV分量及参考索引获取计算、参考图像矩阵选择处理、分像素内插和加权预测处理三级流水线模块。

宏块流水线技术在硬件实现视频编解码过程中起到相当重要的作用。图1中, 当第一个宏块完成MV分量及参考索引获取计算转而进入第二级执行参考图像矩阵选择处理时, 第二个宏块便进入第一级执行MV分量及参考索引获取计算的环节中,大幅度提高了各个模块的利用率。这样做,虽然增加了一定的电路规模,但是大大提高了运行效率[5]。
图1中方框图表示处理模块,圆角框图表示存储器单元,其中纵条状的是DDR SDRAM(用于存储参考帧图像)和SDRAM(用于存储MV解析结果,B帧解码时需要参考),其余横条纹表示内部使用或者与H.264其他解码模块接口的SRAM。黑色箭头与H.264其他解码模块接口的存储器或者模块连接。
帧间预测的整体实现过程为:在每幅图像解码开始后,DSP内完成参考图像的管理,包括当前图像的POC值计算、上一幅解码图像的标记、当前图像标记命令的存储以及参考帧的初始化和重排,将重排好的参考帧列表信息写入列表信息存储器中。在片层(SLICE)解码开始后,将每幅参考图像的加权系数写入加权信息存储器中。宏块级解码开始后,采用流水线技术完成各个宏块的帧间预测解码处理。下面详细描述各个模块。
2.1 MV分量及参考索引获取计算
H.264/AVC使用两种熵编码方法,CAVLC(上下文自适应的可变长编码)和CABAC(上下文自适应二进制算术编码),两种都是基于上下文的熵编码技术。本单元采用乒乓机制接收CAVLC/CABAC解码得到的帧间预测残差信息,包括宏块编码方式(mb_type)、宏块分割(mbPartIdx,subMbPartIdx)、参考帧标识(predFlagLX)、参考帧索引号(ref_idx_lX)以及运动矢量差(mvd_lX)等等。然后,根据当前宏块在帧中的位置和小块在宏块中的偏移地址计算得到当前小块的左上和右上小块在帧存中的地址,从参考块信息存储器中读出参考小块的参考索引和运动矢量,并结合残差信息以及参考帧列表信息计算得到当前小块的绝对运动矢量,解析完成后将结果写入当前宏块参考信息存储器。同时将结果写入SDRAM,供B帧参考使用。
本模块循环控制由变块自适应循环控制单元完成,对一个宏块中的各个小块按照宏块分割进行变块自适应,在完成一个小块后进行判断,启动下一个小块运动矢量信息的预测。小块之间的跳转状态以及宏块分割如图2所示。其中,下方是宏块的各种分割,上方是各种状态跳转,指示线上标注的是分割宽高变量partWidth和partHeight。假设一个宏块分割为两个8×16,则小块状态跳转顺序为:0_0->0_2->END。
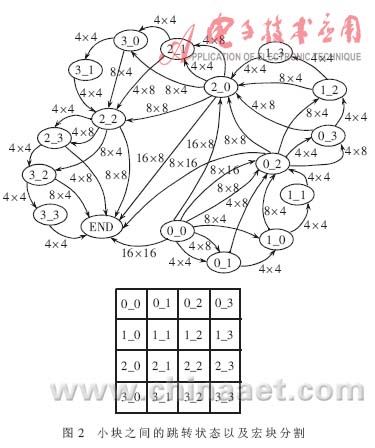
第二、三级变块自适应循环控制单元与之类似,不再赘述。
2.2 参考图像矩阵选择处理
本单元通过循环控制得到当前小块运动矢量信息,根据当前小块的位置信息和运动矢量等,计算当前小块对应的参考矩阵块在二维图像中的坐标,结合参考帧序列号等,计算得到参考矩阵块在参考帧存储器DDR SDRAM中的绝对读地址,从DDR SDRAM中读出参考数据。然后,根据数据的边界信息,从读取参考数据中抽取有效数据,进行进一步的组织和运算,并写入参考像素矩阵存储器。
参考矩阵选择处理不涉及复杂的计算过程,但对数据操作比较多,涉及到的存储器操作比较复杂。存储器的读写在H.264的硬件设计中是一大瓶颈,因此主要关注点在于存储器的高效读写和利用。为了满足实时解码的要求,DDR SDRAM位宽为32bit,参考帧数据按照交织的方式存入DDR SDRAM中,具体亮度交织存取方式如图3所示,其中MBx_y为第y行第x列的宏块。

这样,在DDR SDRAM中,每个BANK内每个PAGE可以存储4个宏块亮度(或者8个宏块亮度,色度按照CrCbCrCb方式存储,便于读写和后端操作)。在这种存储方式下,读数据的起始地址,每行读取几个数据,读几行数据等信息均由小块位置解析模块给出。具体的DDR中数据的读地址由专门的DDR控制器产生,并根据要求将读取的数据拼接成所需格式,供后端读取和进行进一步的拼接和填充。
2.3 分像素内插和加权预测处理模块
本单元通过循环控制得到当前小块运动矢量信息,计算得到色度矢量。然后,按照要求从参考像素矩阵存储器(Luma_mem,Chroma_mem)中读出参考数据,分别对亮度和色度完成插值和加权预测,将结果存入预测像素结果存储器。
为了保证插值的运算效率,满足高清序列实时解码需要,本文设计了一个基于H.264标准的亮度插值运算电路。由于H.264中宏块采用树形分割,最小分割尺寸为4×4,所以在该结构中,每个宏块被拆分成16个4×4的亮度块,顺序被处理。
亮度插值运算单元数据通路如图4所示,插值运算单元每次参考9×9的输入数据和运动矢量信息完成分像素插值。首先,根据运动矢量进行判断,如果运动矢量的垂直和水平分量为整数,则表明插值预测像素已经实际存在,可以直接由输入数据得到。如果其中一个或者两个为分数,则要通过参考帧中相应像素内插得到。
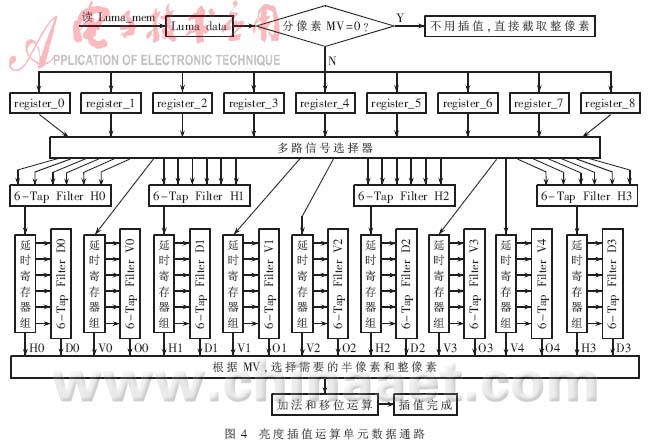
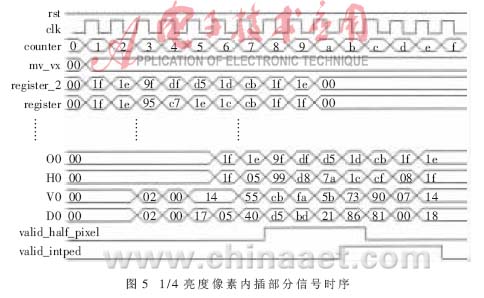
如图4所示,输入亮度数据根据多路信号选择器分配给不同的6-tap滤波器,在运算单元内部设置了几组延时寄存器组,用来缓冲需要输入到滤波器的参考像素值。在需要的半像素和整像素全部得到和对齐后,根据运动矢量选择对应位置的半像素和整像素,进行加法和移位运算,得到1/4像素精度的预测亮度像素值。图5给出了1/4亮度像素内插部分信号时序。
3 分析及实现结果
本文采用基于三级流水线结构的帧间预测解码VLSI实现结构,用Verilog-HDL语言进行寄存器级描述,并且在Modelsim6.0环境下进行功能仿真。仿真结果与标准算法软件计算结果相比较以保证其正确性,证明本文的设计是正确的。设计实现采用ALTERA公司的QUARTUSⅡ5.0开发软件,目标器件为StratixⅡEP2S60F1020C5,硬件仿真和验证表明该设计可以在60MHz频率下稳定工作。
统计显示,本文设计的三级流水结构中,除第二级参考图像矩阵选择处理与宏块分割、运动矢量以及DDR SDRAM读写相关无法具体确定外,第一级MV分量及参考索引获取计算、第三级分像素内插和加权预测处理均可以在900周期内完成。
通过仿真及在H.264解码器中的实际应用和测试,证明该设计工作稳定,能够满足H.264标准基本框架下QCIF格式图片30fps(帧/秒)实时解码的要求。
参考文献
[1] ITU-T Rec.H.264.Advance video coding for generic audiovisual services[S].March,2005.
[2] WIEGAND T,SULLIVAN G J,BJONTEGAARD G,et al.Overview of the H.264/AVC video coding standard[J].IEEE Trans.on circuits and systems for video technology,2003,13(7):560-576.
[3] 毕厚杰.新一代视频压缩编码标准-H.264/AVC[M].北京:人民邮电出版社,2005.
[4] 高玉娥.H.264解码器的系统设计及CAVLC的硬件实现[J].电视技术,2006(12):23-28.
[5] 吴子辉.H.264编解码器方案综述[J].电视技术,2005,(12):12-14.
[6] H.264 reference software,JM9.6[CP].http://iphome.hhi.de/suehring/tml/download/old_jm/jm96.zip,July,2005.