
基于HBM算法的高速反蠕虫引擎的设计实现
2008-07-08
作者:倪 嘉, 林 闯, 陈 震
摘 要: 基于网络处理器" title="网络处理器">网络处理器的特点,提出了一种新的多模" title="多模">多模匹配算法HBM算法。在Intel网络处理器IXP2400上,设计实现了高速反蠕虫病毒引擎" title="反蠕虫病毒引擎">反蠕虫病毒引擎。实验表明,引擎达到了千兆以太网的性能要求,具有较好的实际应用价值。
关键词: 网络处理器 反蠕虫病毒引擎 多模匹配算法 HBM算法
随着Internet规模的扩大,网络安全已经成为当前网络系统设计中的一个重要问题。为此,在当前的网络防火墙和入侵检测系统(IDS)中,除了需要进行协议分析、流状态检测外,还需要对网络分组的载荷进行特征匹配,以此来确定网络分组中是否含有蠕虫病毒代码。与网络带宽的飞速提高相比,反蠕虫系统的扫描引擎的发展还不成熟,开发千兆以太网环境下的反蠕虫系统还有难度。本文给出的对于网络分组载荷进行扫描检测的多模匹配引擎,正是一种适合高速环境下的反蠕虫引擎系统。
1 相关工作
反蠕虫引擎平台主要有两种:一种是采用全硬件定制的方式;另一种是采用软件实现的方式。采用硬件方式往往能够得到较高的扫描检测速度,但是不适合设计比较复杂的防火墙或IDS系统;采用软件方式的扫描引擎速度较慢,但是可以用来设计实现功能复杂的系统。
网络处理器[1]是一种介于全硬件定制和通用处理器之间的新型处理器,相对于前两种实现方式,网络处理器兼有他们的优点。一方面,它采用执行程序的方式,相比于硬件实现方式,可以完成较为复杂的处理功能。同时,也可以方便地添加和扩展功能模块,有效地移植和整合现有的程序功能。另一方面,它的硬件体系结构针对网络应用进行了优化,大大提升了分组处理过程,可以得到较好的性能指标,适合作为网络应用的开发平台[1,5,9]。
反蠕虫引擎的核心算法是多模匹配算法(multi-pattern matching algorithm)[2,4],即对于输入的字符串,扫描其是否包含预先给定的若干特征字符串之一,蠕虫携带的特征字符串也称为特征码(signature)。
多模匹配的主要算法之一是将BM算法[6]在多模匹配条件下进行扩展。BM算法是一种启发式算法,主要利用了失效字符转跳及好后缀转跳思想,如图1和图2所示。该算法思想是在每次匹配中,从右往左反向逐个比较字符,当发生匹配失败时,根据此字符的信息以及之前比较过的字符串后缀(即字符串最右部分)信息,最大程度地向后移动比较指针,从而减少无用的比较次数。在图1中,输入字符‘l’匹配失败,从失效转跳表Delta1中,找到‘l’对应项的值(该值为‘l’在“hello hi”中最右出现处到串末尾的距离),并将输入字符串向左移动相应距离。在图2中,输入串的‘do’和特征字符串末尾的‘do’相匹配,称特征字符串的‘do’为好后缀。转跳时,可以将输入字符串的‘do’移动到和特征串中的前一个‘do’相对齐位置。

BM算法思路推广到多模匹配中,由于匹配模式增加,Delta1表的每一项必须是字符块而不是单个字符(否则,所有值均接近0,无法给出好的转跳信息),这样就带来Delta1表空间增大的问题,同时原来的好后缀生成算法在多模匹配下也不正确,需要重新设计。
这类算法主要有WM算法[4]、Setwise BMH算法[7]、AC-BM算法[8]等。WM算法只对输入字符串的后缀进行一次比较,并没有很好地利用字符串的整体信息,也没有利用好后缀的可能转跳。Setwise BMH算法和AC-BM算法的失效字符转跳表(Delta1表)的组织空间往往很大,无法放入高速缓存之中,不适合在网络处理器上实现。为此,本文基于网络处理器的特点,提出了一种新的多模匹配算法,即HBM算法。
2 HBM算法描述
HBM算法同样使用失效字符转跳思想,所不同的是,将失效字符转跳表(Delta1表)进行散列压缩(允许碰撞),从而可以大大减少Delta1表的空间占用;同时,在多模匹配情况下改进好后缀转跳方式。与以上几种算法相比,HBM算法可以在空间要求大大降低的情况下,得到相近甚至更优的时间性能;同时,在网络处理器系统中,可利用高速缓存单元,得到更好的系统性能数据。其主要步骤如下:
(1)每次比较的基本单位是若干个字符(在实现中取4个字符)组成的字符块。
(2)每次对一段输入子字符串的匹配是从右向左依次进行的。例如,子字符串“abcdef”需要先比较字符块“cdef”,再比较“bcde”,最后比较“abcd”。判断第i次字符块比较是否成功的条件是:该字符块在Delta1表中的值D1是否小于i(即D1
(4)算法使用两张启发式移位表:Delta1和Delta2,第(3)步中输入字符串的移动距离,取两者中的较大值。
(5)若某个子字符串的所有字符块均比较成功,则还需要和蠕虫特征码进行精确比较,才能确定其为特征码之一或是一次误判(false-positive)。
整个扫描过程并不复杂,算法的主要难点在于如何有效地构造两张启发式移位表Delta1和Delta2。下面对这两张表的构造做详细介绍。
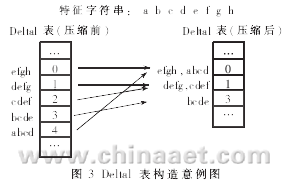
2.1 Delta1表构造
Delta1表的构造和原BM算法相比,不同之处在于:
(1)比较的基本单位变为字符块。
(2)字符块在Delta1表中的索引位置由散列函数值决定。
(3)如果两个字符块由于散列冲突而对应Delta1表的同一项,则此项存放两者中的较小“移位距离”。
例如,图3中“efgh”和“abcd”的散列值相同,它们就存放于Delta1表中的同一项,其值取较小的值0。
2.2 Delta2表构造
Delta2表的构造比较复杂,下面将给出其构造和使用方法。
在多模匹配情况下,不能像BM算法那样直接找特征串首部是否有和后缀相同的字串,而是要通过字符块在Delta1表中的值D1,来间接判断首部是否有好后缀。例如,在图4中,字串“xbcde”和后缀串“abcde”具有相同的特征(如图所示,从右往左数,第i个字符块的Delta1值D1

记特征字符串数为n,长度为L,块大小为b;记特征码为S0,S2……,Sn-1,为了便于描述,将任意字符串pattern=a0a1a2…aL-1,扩充记为pattern=…$$$$a0a1a2…aL-1,即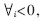 ai=$。其中$为假想字符,可为任意字符,同时任何含有$的字符块,其Delta1值定为D1=0。这里对所有特征字符串都作了这种扩充。
ai=$。其中$为假想字符,可为任意字符,同时任何含有$的字符块,其Delta1值定为D1=0。这里对所有特征字符串都作了这种扩充。
在给出Delta2表的构造和使用之前,先给出某个子字符串“相一致”,以及函数rpr(rightmost plausible reoccurrence)的定义。
“相一致”指的是在特征字符串中,某个子字符串和后缀子字符串,它们的首字符块有不同的特性,而其余对应字符块则有共同的特性,如图4所示。由于出现好后缀转跳时,后缀子字符串的Delta1值特性固定,因此定义特征字符串中的子字符串C=c0 c1…cn和后缀字符串“相一致”,要求满足条件(1):

式中,D1(ci ci+1…ci+b-1)为字符块ci ci+1…ci+b-1在Delta1表中的移位值。
定义函数y=rpr(Si,t),t∈[0,L-b-1],要求在特征字符串Si中,从位置t往左(不包括t),找到长度为L-t的最右的相一致的子字符串,记此子字符串为位置k开始的siksi(k+1)…si(k+L-t-1),则rpr(Si,t)=k+1。
Delta2表长度固定为L-b+1,记Delta2表的第t项的值为D2(t),则其值可由(2)式求得。
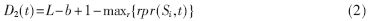
式中,0≤t≤L-b-1,maxr{rpr(Si,t)}表示对于r=0,1,…n-1,取这n个特征字符串Sr的rpr值中的最大值。
3 基于网络处理器的优化
本文将HBM算法在Intel网络处理器IXP 2400上实现,并针对IXP 2400的体系结构特点进行了优化。主要由网络处理器的XScale核心对蠕虫特征码进行初始化处理,组织两张启发式移位表;运行时主要由微引擎执行扫描工作,完成网络分组的接收、分类、扫描和转发功能。系统整体功能模块如图5所示。
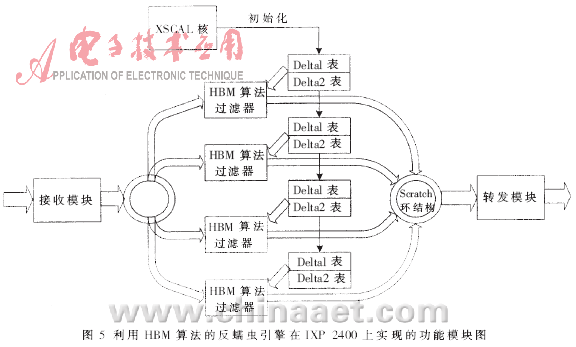
在IXP 2400上实现HBM多模匹配算法时,综合起来,主要的优化有:
(1)算法中的散列运算用逻辑操作完成,不需要复杂的乘除指令支持,适合网络处理器的指令结构。
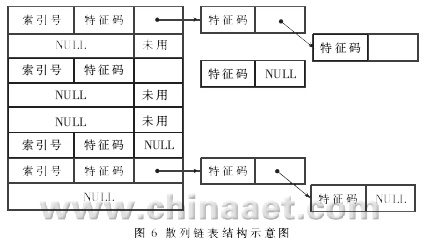
(2)将特征字符串组织成散列链表的形式,以减少精确匹配时的I/O" title="I/O">I/O操作次数。散列链表结构如图6所示。
(3)将两张访问频率较高的表Delta1和Delta2存放在I/O存取速度快的存储单元,将访问频率低的特征字符串集合存放在存取速度慢的单元,如表1所示。

(4)对于输入的分组载荷进行预读取功能,以减少I/O操作次数。即对于输入的分组载荷,每次从慢速DRAM中预读取最大的64个二进制字符,通过软件计算指针位置,从而有效地利用预读取的分组载荷,减少I/O访问次数。
4 实验测试与性能分析
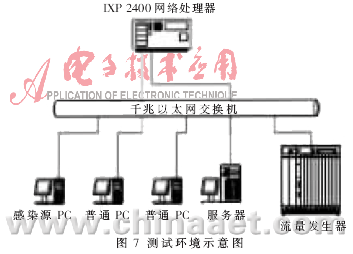
在测试床中对系统的有效性进行了测试。该测试床包括以下设备:千兆以太网络交换机(TP-LINK TL-SL2226P+,24+2G)、流量发生器IXIA 1600、ENP 2611实验板(含IXP2400网络处理器),以及携带蠕虫病毒的PC机、多台普通PC机和服务器。其配置环境示意图如图7所示。反蠕虫病毒引擎工作在监听模式下被动接收分组、检测并发出报警。
实验采用随机产生的固定长度特征码字,字长为32字节,特征码的数量为512个(注意:HBM算法也支持非固定长度的特征码字)。产生的以太网帧长度分别为118、246、…、1 398以及最大可能的1 518字节。分组中携带特征码字的比例(简称为命中率)为0%、20%、…、100%,特征码字在分组载荷中的出现位置随机决定。实验输入的分组数目为4 000。
Intel网络处理器IXP 2400的XSCAL核的工作主频为400MHz,每个微引擎(ME)的工作主频为400MHz,SRAM和DRAM的总线主频为100MHz。实验数据的吞吐率" title="吞吐率">吞吐率值均取于媒体总线(Media Bus)上,其时钟频率为104MHz。
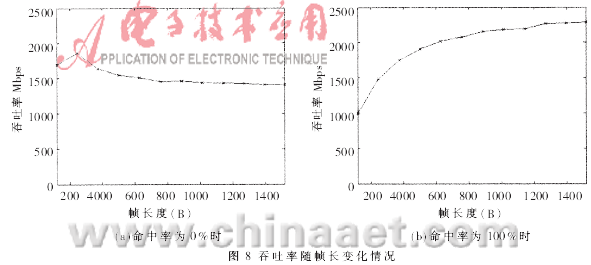
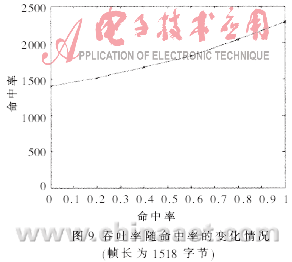
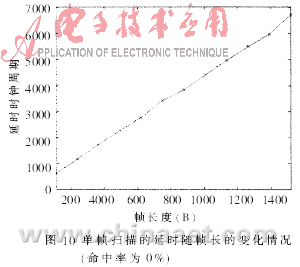
图8和图9反映了反蠕虫引擎的吞吐率性能。图8(a)是命中率为0%时的吞吐率随以太帧长度变化情况,即没有网络分组包含蠕虫特征码的情况,引擎性能最后稳定在1 400Mbps~1 500Mbps之间。图8(b)是命中率为100%时的情况,即每个网络分组都包含蠕虫特征码的极端情况。此时,一旦发现特征码即结束操作,剩余的载荷内容不必继续检测,吞吐率随着以太帧长度的增加而增加。图9为吞吐率随命中率变化情况,随着命中率的增加,每帧平均不需要检测的载荷数目增多,吞吐率增大。图10为不包含蠕虫特征码的网络分组通过反蠕虫引擎的延时情况,随着帧长度的增加,单帧处理的平均延时呈线性平稳增长。由以上性能数据可知:在IXP2400上采用HBM算法的反蠕虫引擎,已经达到了千兆以太网的吞吐率要求;同时,算法的吞吐率性能稳定,在蠕虫爆发时(即命中率大幅度提高),性能不会有大的下降。
网络处理器由于具有灵活的可编程特性,适用于高速的网络分组处理。本文采用Intel IXP2400网络处理器,设计和实现了基于深度包检测的反蠕虫病毒引擎。HBM算法是对经典BM算法的一个推广,算法的重点是以字符块为比较单位,重新设计Delta1表和Delta2表。同时根据网络处理器的存储器架构特点,以允许冲突的散列运算压缩Delta1表,合理存放相应的数据结构,减少了I/O开销。实验结果表明,HBM算法有效地提高了吞吐率,并且性能指标稳定,达到了高速网络环境下的性能要求。
参考文献
[1] CHEN Z, LIN C, NI J.AntiWorm NPU-based Parallel Bloom filters in Giga-Ethernet LAN[C]//IEEE International Conference on Communications:Network Security and Information Assurance Symposium, 2006.Istanbul:IEEE Press,2006:2118-2123.
[2] SONG H,LOCKWORD J.Multi-pattern signature matching for hardware network intrusion detection systems[C]//: Global Telecommunications Conference Nov,2005:GLOBECOM’05.St. Louis: IEEE Press, 2005:5.
[3] KIENZLE D M, ELDER M C. Recent worms: a survey and trends[C]//Proceedings of the 2003 ACM workshop on Rapid Malcode, October, 2003. Washington: ACM Press,2003: 1-10.
[4] WU S, MANBER U. A fast algorithm for multi-pattern searching. Technical Report TR-94-17[R]. Department of Computer Science, University of Arizona, 1994.
[5] LIU R, HUANG N, KAO C. A fast pattern-match engine for network processor-based network intrusion detection system[C]//:Information Technology: Coding and Computing 2004: Proceedings of ITCC 2004 International Conference. Las Vegas: IEEE Press, 2004:97-101.
[6] BOYER R, MOORE J. A fast string searching algorithm[J]. Communications of the ACM, 1977,20(10):762-772.
[7] FISK M,VARGHESE G.An analysis of fast string matching applied to content-based forwarding and intrusion detection. Technical Report CS2001-0670[R]. University of California-San Diego, 2002.
[8] COIT C, STANIFORD S, MCALERNEY J. Towards faster pattern matching for intrusion detection, or exceeding the speed of snort[C]//. Proc. of the 2nd DARPA Information Survivability Conference and Exposition:DISCEX II. Piscataway: IEEE Press, 2001:367-373.
[9] XU B, ZHOU X, LI J. Recursive shift indexing: A fast multi-pattern string matching algorithm[C]//Proc. of the 4th International Conference on Applied Cryptography and Network Security:ACNS 2006. Singapore: Springer,2006.