
G.729编码流说话人识别研究
2008-07-25
作者:唐 晖1, 李弼程2
摘 要: 研究了G.729编码流说话人识别" title="说话人识别">说话人识别算法,提出了一种使用固定码书增益作为判决参数的G.729静音帧判决方法。将这一方法应用于低复杂度的G.729编码流说话人识别,去除压缩语音数据中的静音帧从而提高识别率。
关键词: 编码流 说话人识别 G.729 静音帧
因特网已经迅速成为了承载着话音、视频、数据的全球化的通信网络。在这些业务中,近年来最重要的趋势无疑是迅速增长的VoIP(Voice over IP)服务。随着VoIP电话业务的持续增长,越来越需要针对VoIP提供的各种交互式语音服务的实时在线说话人识别系统[1]。而且,安全司法部门迫切需要实时地对特定说话人进行识别。更准确地说,实时、针对大量用户的在线说话人识别系统相对于高延迟的离线说话人系统具有更广泛的应用前景,适合多种实际应用环境[2]。
然而,传统的自动说话人识别方法(ASR)不能直接应用于实时的VoIP通话中,这是因为ASR是建立在处理未经压缩的语音波形(PCM)之上的,但是语音在IP网络中传输时绝大多数情况下都是以编码压缩形式传输。在发送端,为了减少传输的数据量,发送者使用语音压缩标准对语音进行压缩;在接收端,在应用传统的说话人识别方法之前必须对压缩话音进行解压缩以获得原始语音波形的近似。由于这一过程具有很长的时间和系统资源消耗,这种处理方式很不适合同时监控大量话路的VoIP设备组件或网络嗅探器。
Motorola公司项目研究人员M. Petracca、A. Servetti和J.C. De Martin对在压缩语音上实现低复杂度的说话人识别进行了一系列试验性的研究[1,3,4]。他们的目的是,不经解码语音数据流,直接提取与说话人相关的压缩编码" title="压缩编码">压缩编码参数,实现识别模型的建立和说话人的识别,从而节约重要的系统资源,在VoIP设备组件或网络嗅探器上进行实时的说话人识别。参考文献[1]给出了该方法在各种编码器下的识别性能,且在给出的大多数语音压缩算法下得到了很好的识别效果。但是,对于VoIP中广泛应用的码激励线性预测压缩算法(G.729标准)其识别效果却不是很好,对14个说话人进行闭集识别,分析10秒、20秒、30秒的话音,系统的识别率只有77.0%、83.1%、87.7%。
本文应用参考文献[1,3,4]给出的低复杂度编码流说话人识别方法设计了G.729编码流识别算法" title="识别算法">识别算法,在十个说话人内进行闭集识别,分析10秒、20秒、30秒的话音,系统的识别率分别为72.3%、80.0%、86.9%。考虑到该方法是基于编码压缩参数的统计量的,而静音帧的存在会影响统计量的收敛速度并且会引入噪音,从而影响统计量的结果。针对这一问题,本文尝试去除压缩语音数据帧中的静音帧以提高系统的识别率。为了在编码流中准确地检测出静音帧,本文统计了G.729压缩语音中静音帧和语音帧在各个编码参数上的统计特征,发现静音帧与语音帧的固定码书增益数值大小相差很大。在这一发现之上,提出一种以固定码书增益均值乘以比率系数作为阈值的静音帧、语音帧选择方法。将这一方法用于G.729编码流识别算法中,分析10秒、20秒、30秒的话音,系统的识别率由72.3%、80.0%、86.9%提高到79.2%、89.2%、90.8%,同时识别所需的时间也得到了一定的缩短。
1 G.729编码流识别算法概述
1.1 编码流语音特征
由于语音处理中主要的特征变化比较缓慢,语音信号通常以10~25ms间隔进行参数化处理。对单个说话人提取出的特征向量通常可以看作是连续密度分布的取样。不同说话人的分布在整个说话人空间内是交叠的,但理想的情况下不同说话人之间又是可分的,这使得说话人识别成为可能。例如,代表着重音和音调信息的基音频率变化范围很大,但是一个人在一定的时段内基音频率的平均值是与所说文本无关的确定值[5]。
本文的假设是:在足够长的语音时段内,比特流中的编码参数值包含着可以区分不同说话人的特征。对G.729编码参数的分析可以看到,这些参数确实可以看作是说话人的特征。例如自适应码书标号几乎同基音频率成线性关系,并且与基音频率具有近乎相同的分布。
本文选择表征声道特征的前五级LSP参数、激励特征的自适应码书标号、增益能量的自适应码书增益和固定码书增益作为识别特征参数[6]。
1.2 说话人特征描述
本文选择标准差" title="标准差">标准差(δ)和偏度(Skewness)作为说话人识别参数的统计特征描述。标准差和偏度的定义如下:

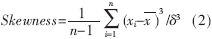
标准差反映总体的相对离散程度;偏度是描述变量取值分布对称性的统计量,偏度的绝对值越大变量的分布形态偏移程度也越大。
为了更有效地利用标准差和偏度统计量来进行识别,必须知道统计量在多长的统计时间内可以稳定下来,即根据该统计量得到的识别结果在多长时间稳定可靠。根据统计量稳定下来的最短时间来确定分析时间,避免由于统计时间过短使得获取的统计值不稳定或者由于统计时间过长造成不必要的识别延迟。因此,必须统计说话人语音在开始部分的统计量与整段语音之间的关系随时间的变化情况。图 1给出了1~130秒自适应码书标号的标准差和偏度与长时语音(半小时的语音)的方差和偏度之间的比率。
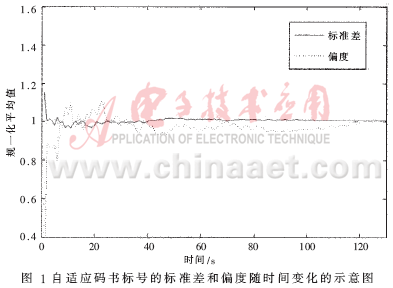
从图1中可以清楚地看到,40秒后标准差就收敛了,而偏度在120秒后才收敛。这一结果很重要,因为在120秒后就不需要观察统计量来反映出真实的说话人身份(需要统计模型),而在20~40秒间就可以获得足够多的信息来区分不同的说话人。
1.3 说话人区分性和特征参数选择" title="参数选择">参数选择
1.3.1 说话人区分性
通常用来估计参数的说话人识别性能的指标是该参数的说话人集间和集内标准差的比值,这一比值被称为F-ratio。参考文献[3]对GSM AMR压缩编码参数的F-ratio进行了计算,选择F-ratio最大的几个参数的统计量进行识别,发现该方法并没有取得很好的效果。这一试验说明在编码流说话人识别中,不能单一地以F-ratio的大小作为标准对编码参数进行选择。
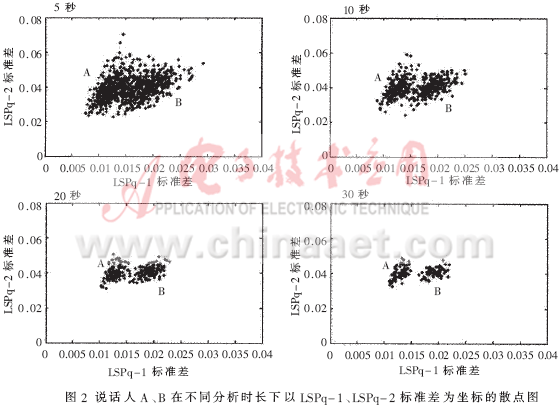
另一个衡量参数的说话人区分性能的方法是观察一对选择参数在一定时间段内不同说话人的散点图。图2给出了说话人A和B在5秒、10秒、20秒、30秒以LSPq-1标准差和LSPq-2标准差为坐标的二维散点图。
从图2中可以看到,随着分析时长的变大,同一说话人数据点的散布越来越小。在5秒和10秒的短时分析下存在一定的重叠现象,而在20秒、30秒的长时分析下,很明显不同说话人的数据点是分离的。该结果表明,可以使用编码参数的统计量的欧氏距离来区分不同的说话人。
1.3.2 特征参数选择
参考文献[3]使用了一种集合排除方法对每个特征的识别性能进行排序。该方法假设一个特征集的识别性能是与使用这个集所造成的错误率成反比的。算法的步骤如下:假设开始时特征的数目为N,计算这N个特征集的每个N-1个特征的子集的识别率。找到具有最高识别率的子集,则未包括的那个特征就被确定为这N个特征中识别效果最差的特征,下一次特征排序过程中排除这个特征。这一过程直到所有的特征都被排除出集合外才结束,特征的识别性能的排序就是特征被排除出集合的次序的倒序。
本文使用该特征参数选择方法在一个训练数据集下根据训练集下的识别率进行参数选择,将训练集中取得最高识别率的特征参数选择作为特征参数选择的结果进行识别。
1.4 说话人识别方法
识别是基于1.1节中选择的压缩编码参数的标准差和偏度进行的。首先计算每个说话人在训练集中120秒的统计量作为参考值,然后以同样的方法计算待测试集的统计量。计算待识别说话人特征统计量与每个说话人参考统计量之间的欧氏平方根距离,与待识别说话人统计量具有最小距离的参考说话人作为识别结果。
参考文献[4]把经过实验得出的标准差(δ)和偏度Skewness(ξ)的线性组合作为判决式,即:
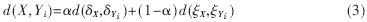
式中,d(a,b)是a与b之间的欧氏平方根距离,X是待分类说话人向量,Yi是第i个说话人参考向量,α是实验得到的比例系数(α=0.48),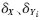 是待分类说话人第i个说话人参考向量经过特征参数选择后被选中的编码参数标准差组成的向量,
是待分类说话人第i个说话人参考向量经过特征参数选择后被选中的编码参数标准差组成的向量,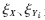 是待分类说话人第i个说话人参考向量经过特征参数选择后被选中的编码参数标准差组成的向量。
是待分类说话人第i个说话人参考向量经过特征参数选择后被选中的编码参数标准差组成的向量。
1.5 实验结果
本文使用863语料库,在10个说话人中进行闭集识别,每个说话人26段语音,用G.729编码器压缩编码模拟实际的VoIP声码器。其中每个人的13段语音作为训练数据进行1.3.2节中的特征参数选择,再使用选择的参数在其余的10人共130段语音中进行识别性能的测试。
1.5.1 特征选择实验
使用1.1节中所选的8个压缩编码参数的标准差和偏度共16个统计量作为初始特征集,采用1.4节中介绍的识别方法,使用1.3.2中介绍的特征参数选择方法在30秒的话音统计中得到特征统计量识别性能的排序如表1所示,相应的识别率如表2所示。
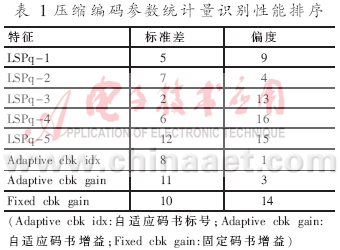
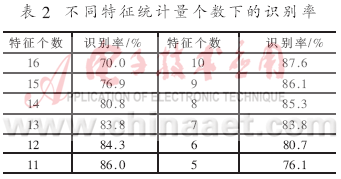
从表 1、表 2中可以看出,当特征统计量个数为10时,系统有最高的识别率。此时选择的识别参数为LSPq-1、LSPq-2、LSPq-3、LSPq-4、Adaptive cbk idx、Fixed cbk gain的标准差和LSPq-1、LSPq-2、Adaptive cbk idx、Adaptive cbk gain的偏度。
1.5.2 识别性能实验
使用1.5.1节实验中选择的10个特征统计量在测试集上进行识别,表 3给出了该方法在10秒、20秒、30秒话音统计下的识别率。
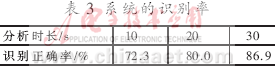
2 静音帧选择
由1.5节中的实验结果可见,未改进的G.729编码流说话人识别方法的识别性能并不理想,尤其在分析时间较短的情况下(10秒、20秒)。参考文献[1]给出的系统在14个说话人内进行闭集识别,使用的编码参数为LSP参数的前三级、自适应码书标号、相关自适应码书标号、第一子帧和第二子帧的增益,统计量选取的是离散系数和偏度,分析10秒、20秒、30秒的话音,系统的识别率也只有77.0%、83.1%、87.7%。然而,G.729压缩标准在VoIP中使用广泛,许多公司的VoIP设备使用的都是该声码器[2]。考虑编码流说话人识别方法是基于压缩编码参数的统计特征,而静音帧的存在会影响统计量的收敛速度并且会引入噪音从而影响统计量的结果。本文采用静音帧选择的方法去除静音帧以提高系统的识别性能。
2.1 静音帧的编码参数统计分析
对于静音段的检测,比较有效的语音短时特征有:短时平均能量和短时平均过零率[7]。在编码流无法得到语音的波形,如果采用传统的方法获得会造成很大的计算复杂度。为了在编码流进行静音帧检测,本文分析了G.729压缩编码参数在静音帧、语音帧中的分布特性以区分静音帧。
本文统计了自适应码书标号、自适应码书增益和固定码书增益在静音帧和语音帧中的统计分布,发现固定码书增益在静音帧和语音帧中的数值分布有很好的可分性。对一段30秒的语音进行人工的静音、语音分割,得到21.2秒的静音数据和8.8秒的语音数据,分别对静音、语音数据进行G.729编码压缩得到2120帧静音和880帧语音,统计静音帧和语音帧的固定码书增益大小的分布情况,结果分别如图3、图4所示。为了更好地示意,将语音帧中固定码书增益大于200的帧的固定码数增益值赋值为200。
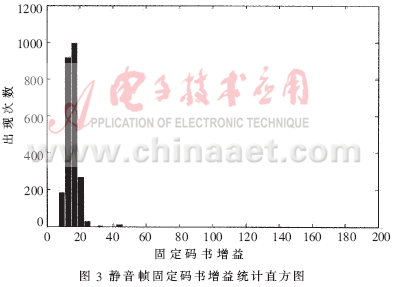
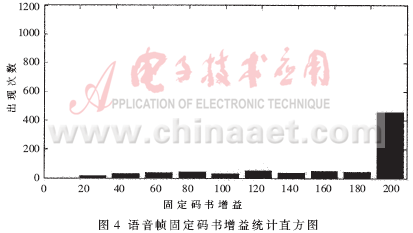
从图 3、图 4中可以清楚地看到,静音帧固定码书增益的值要远远小于语音帧固定码书增益值,可以考虑使用固定码书增益的数值来作为静音帧判断的标准。
2.2 静音帧的判断方法
由于不同的语音信号的能量之间的差异,固定码书增益的大小也会随之变化。因此,固定地选取一个判决门限作为静音帧和语音帧的判决标准是不合理的。本文先计算待识别说话人所有压缩数据帧的平均固定码书增益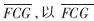 乘以比例系数(β)的值作为判决门限,第i帧的静音判决式如下:
乘以比例系数(β)的值作为判决门限,第i帧的静音判决式如下:
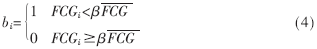
式中,bi表示第i帧是否是静音帧,通过实验得到,当β=0.5时,判决得到很好的效果。
3 加入静音帧选择的说话人识别实验
将本文给出的静音帧选择方法应用于本文给出的G.729编码流说话人识别算法,去除静音帧。在与1.5.2节中同样的特征参数选择和测试集合下,分析10秒、20秒、30秒的话音,对比未使用帧选择方法的识别结果如表 4所示。图 5为对比未使用静音帧选择方法的性能分析图。
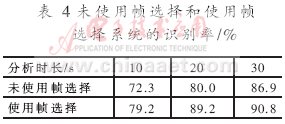
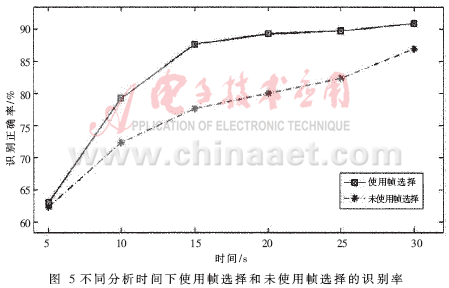
静音帧选择的方法不仅可以提高系统的识别率还可以提高系统的识别速度,减少说话人识别所用的时间。使用微机配置为:CPU Pentium 4 2.8GHz、内存512MB,在与1.5.2中同样的实验条件下分析30秒的话音未使用帧选择方法系统耗时175.9秒,而使用帧选择方法系统耗时120.4秒,系统耗时较未使用帧选择减少了31.5%。
本文使用低复杂度压缩域识别算法设计了G.729压缩域说话人识别方法,并使用固定码书增益作为判决参数设计了静音帧判决方法,从而提高了系统的识别性能。实验结果表明,静音帧选择的方法不仅提高了系统的识别率还减少了识别所需的时间,收到了很好的实用效果。该静音帧识别方法也可以运用到G.729压缩标准下的其他需要使用静音判决的场合。
参考文献
[1] PETRACCA M, SERVETTI A, DEMARTIN J C. Performance analysis of compressed-domain automatic speaker recognition as a function of speech coding technique and bit rate[C]//Proceedings of IEEE International Conference on Multimedia and Expo (ICME), Toronto, 2006:1393-1396.
[2] AGGARWAL C, OLSHEFSKI D, SAHA D, et al. CSR: speaker recognition from compressed VoIP packet stream[C]//Proc. IEEE Int. Conf. on Multimedia & Expo, Amsterdam, 2005: 970-973.
[3] PETRACCA M, SERVETTI A, DEMARTIN J C. Optimal selection of bitstream features for compressed-domain automatic speaker recognition[C]//Proc.14th European Signal Processing Conference, Florence, 2006.
[4] PETRACCA M, SERVETTI A, DEMARTIN J C. Low-complexity automatic speaker recognition in the compressed GSM-AMR domain[C] // Proc. IEEE Int. Conf. on Multimedia & Expo,Amsterdam, 2005: 662-665.
[5] MARKEL J D,DAVIS B.Text-independent speaker recognition from a large linguistically unconstrained time-spaced database[C] //IEEE Trans. Acoustics, Speech, and Signal Processing, 1979, 27(1):74-82.
[6] ITU-T G.729-1998 Coding of speech at 8 kbit/s using conjugate-structure algbraic-code-excitedlinear prediction(CS-ACELP)[S]. Genevese:ITU-T,1998.1996.
[7] 王炳锡.语音编码[M].西安:西安电子科技大学出版社,2002.