
文献标识码: A
说话人识别是从说话人的一段语音中提取出说话人的个性特征,通过对这些个性特征的分析和识别,从而达到对说话人进行辨认或者确认的目的。它可以分为两个范畴:说话人辨认和说话人确认。说话人辨认是辨认出待识别的语音是来自待考察的个人中的哪一个;而说话人确认则是特定的参考模型和待识别模式之间的比较,系统只做出“是”或“不是”的二元判决[1]。
Ville Hautamaki[2]等人提出了最大后验概率矢量量化(VQ-MAP)过程,它可以看作是GMM-MAP的一种特殊形式;Suykens等人[3]提出了最小二乘支持向量机LS-SVM的概念,而志平等人[4]将最小二乘向量机应用在说话人识别系统中,并取得了较好的效果。
VQ-MAP过程首先只依照均值对通用背景模型UBM(Universal Bakground Model)进行聚类,然后应用VQ-MAP过程来更新自适应参数,由此训练语音未覆盖到的部分就可以用UBM中说话人无关的特征分布近似,以减小训练语音太短带来的影响。将得到的自适应参数集作为最小二乘向量机的训练样本,在说话人识别中进行应用,取得了较好的效果。本文介绍了VQ-MAP和LS-SVM融合的说话人识别系统,并在说话人识别中进行了应用。
1 VQ-MAP过程
在说话人识别中,可以使用训练集中的发音数据对UBM进行参数自适应来得到发音人的模型。高斯混合模型在最大后验概率自适应(GMM-MAP)过程中需要更新3种参数:权值、均值向量和协方差矩阵。VQ-MAP过程是GMM-MAP的一种特殊形式,它只依照均值向量来得到新的自适应说话人模型。依照均值向量为参数用K均值聚类算法对UBM进行聚类,从而得到一组均值核心矢量:
2 最小二乘支持向量机[3-4]
Suykens等人[3]在SVM的优化函数中引入方差项,并将SVM中的不等式约束条件改为等式约束,提出了一种以二次等式约束条件为基础的改进型向量机即最小二乘向量机(LS-SVM)。这样LS-SVM的求解问题从标准SVM的二次函数寻优问题转换为线性方程求解问题, 解决了二次寻优算法费时且不易用于实时数据处理的问题,从而大大地简化了问题的复杂性[4]。
方程的最优性条件如下:

3 融合算法
3.1选择样本
设计1个SVM,分别标记这2个说话人自适应参数集为{+ 1,- 1}类,将每帧测试语音特征矢量输入到1个训练支持向量机中,对每帧矢量判别是哪一类,当所有的测试语音特征矢量判别完毕后, 采用投票方法判决,得票最多者就为目标说话人。
实验1:同一语音库下,随着说话人人数的变化,VQ-MAP和LS-SVM融合的说话人识别系统与基于LS-SVM的说话人识别系统中SVM训练时间进行对比,两个系统中LS-SVM均采用径向基核函数,取γ=0.125,结果如图1所示。
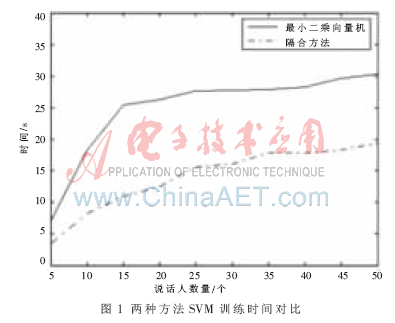
由图1可以看出,随着说话人数越多,所需SVM训练时间越长。当说话人数为50时,应用VQ-MAP和SVM融合的系统SVM训练时间仅仅是直接用LS-SVM训练时间的36.6%。这是因为直接用LS-SVM时,把每个说话人所有帧的特征向量都作为输入矢量来训练SVM,而在VQ-MAP和LS-SVM融合方法中,只把VQ-MAP自适应更新模型中的K个向量作为输入矢量训练SVM,大大减少了运算量,因而提高了识别速度。
实验2:同一语音库下,VQ-MAP和LS-SVM融合的说话人识别系统与基于LS-SVM的说话人识别系统识别率进行对比,比较结果如表1所示。
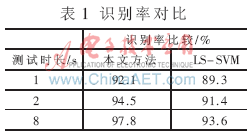
从表1可以看出,随着测试时长的增加, VQ-MAP和LS-SVM融合方法识别率不断提高,且明显高于LS-SVM方法。这是因为在VQ-MAP算法中,采用了均值矢量通过UBM进行自适应来得到说话人模型,在训练语音未覆盖到的部分就可以用UBM中说话人无关的特征分布近似,减小训练语音太短带来的影响,从而为提高识别率打下良好的基础。
本文介绍的VQ MAP和LS-SVM融合说话人识别系统,比直接应用LS-SVM训练效率提高了36.6%,且识别率也高于LS-SVM方法,尤其是在测试时长为8 s时,比传统的LS-SVM方法识别率提高了4.2%,为在说话人识别系统中使用多系统融合提供了新的途径,是一种行之有效的方法。
参考文献
[1] 赵力.语音信号处理[M]. 北京:机械工业出版社,2003.
[2] HAUTAMAKI V, KINNUNEN T, KARKKAINEN I. Maximum a posteriori adaptation of the centroid Model for Speaker Verification[J]. IEEE Signal Process. Lett.2008,15:162-165.
[3] SUYKENS J K, VANDEWALLE J. Least squares support vector machine classifiers[J].Neural Processing Letter,1999,9(3):293-300.
[4] 但志平,郑胜. 基于最小二乘向量机的说话人识别研 究[J]. 计算机工程与应用,2007(7):49-51.
[5] 赵虹,韦丽华.基于支持向量机的说话人识别研究[J].现代电子技术,2008(6):123-127.