
英文摘要:The problem of redundancy often occurs in mass data stored in distributed storage systems. Greater efficiency in storage and network bandwidth utilization can be achieved by employing de-duplication techniques to eliminate this problem. This article introduces the design and implementation of redundancy-removal systems in a distributed WAN environment. AegeanStore can eliminate redundancy prior to data being uploaded. This frees up storage space and resource use, and lowers the total cost of storage. Furthermore, disaster recovery features inherent in the distributed system are maintained, storage system scalability is enhanced, and overall performance of the network is improved.
英文关键字:distributed system; storage system; de-duplication
基金项目:国家重点基础研究发展(“973”)规划(2007CB311100)
由于数字信息的爆炸式增长,现今的大规模网络应用中所存储的数据规模,可以到达上百太字节甚至拍字节的数量级。而传统的存储系统,由于缺乏足够的可扩展性,无法适应日益增长的需求。以Amazon S3[1]为代表的广域网环境下的分布式存储系统凭借其规模的可扩展性、数据的可靠性、服务的可用性、系统的可管理性以及低廉的使用成本等巨大优势,已经在构建网络应用时被广泛认可。
广域网环境下的分布式存储系统将分布在广域网上的资源整合在一起,为网络应用提供存储服务平台。来自不同网络应用和用户的数据存储其中,这些海量的数据中存在着大量的冗余。这些冗余数据不仅在存储时占据了存储系统大量的存储空间,并且在被传输到存储系统的过程当中,浪费了大量的网络用户、网络应用和存储系统的网络带宽资源,使存储系统的资源利用率和整体性能受到严重影响。
本文提出一种在广域网环境下的采用冗余数据删除技术的分布式存储系统原型——AegeanStore。在AegeanStore中采用客户端相关的冗余数据删除技术。该技术通过客户端和服务器端的合作,不仅可提高存储设备的利用率,而且可减轻客户端和服务器之间的网络负载压力,从而进一步提高存储系统的可扩展性和整体性能并且进一步降低其成本。
1 冗余数据删除技术
冗余数据删除技术是将数据集中的冗余数据发现并去除的应用技术,可以分为两大类:相同数据删除和相似数据删除[2]。
1.1 相同数据删除技术
相同数据删除技术首先将数据划分为数据块,然后使用具有抗碰撞特性[3]的哈希函数计算每一个数据块的哈希值作为该数据块的数字指纹,再通过比较数据块的数字指纹来发现相同的数据块。目前,最常用的相同数据删除技术是基于内容的划块(CDC)算法[4],其流程如图1所示。
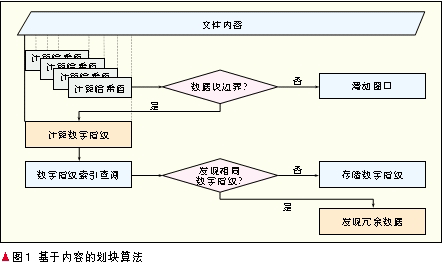
CDC算法存在3个参数,一是目标可变数据块的预期大小S,二是滑动窗口的大小W,三是一个小于S的自然数M。当使用CDC算法处理一个文件时,从文件头开始以每次一字节的步长向后滑动窗口,使用哈希函数计算滑动窗口内部的哈希值H;将H mod S与M进行比较,如果不同,则滑动窗口;如果相同,则发现数据块边界,然后用具有抗碰撞特性的哈希函数计算该数据块的数字指纹;最后,将获得的数字指纹到索引中查找,如果存在则发现冗余数据块,否则说明该数据块是新的,需要存储到系统当中。
1.2 相似数据删除技术
相似数据删除技术分为两个阶段,相似数据检测和相似数据编码:
(1)相似数据检测,首先要定义数据的特征值,该特征值的特点是保证具有相同或相似的特征值的数据具有相同或相似的内容。在提取数据的特征值之后,通过特征值的比较获得相似的数据。常用的相似数据检测技术包括基于Shingle的检测技术[5]。
(2)相似数据编码是在使用相似数据检测,获得具有相似性的数据集之后,在该数据集上采用的编码技术,用于减小该数据集所占用的存储空间。常用的相似数据编码技术包括基于Diff的相似编码技术[6]等。
2 AegeanStore的体系结构
AegeanStore体系结构如图2所示。AegeanStore由客户端、应用服务、文件系统服务、索引服务和数据块服务5个部分组成。
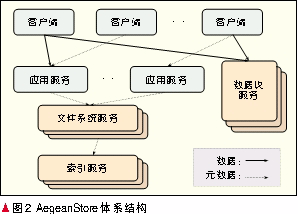
当客户端需要将文件数据存储到应用服务时,首先调用本地冗余数据删除工具,运行数据块划分算法,将要上传的文件分成数据块,并计算每个数据块的数字指纹,然后将这些数字指纹发送给应用服务;应用服务接收到文件上传请求后,记录应用相关信息,再将请求转发给文件服务;文件服务记录文件的元信息(包括文件属性,例如文件的大小、修改时间等,以及文件的冗余数据删除信息,如文件所有组成数据块的数字指纹等),再将请求转发给索引服务;索引服务进行块的数字指纹查询工作,将结果返回给文件服务;文件服务将结果通过应用服务返回给客户端;客户端按照返回结果,只将未出现在数据块服务中的数据块上传;最后,当所有新数据块都存储到数据块服务中之后,文件服务将新数据块的信息更新到索引服务当中。下面将分别介绍5个部分的设计与实现。
2.1 客户端
客户端是为某个应用服务开发,运行在使用该应用服务的用户的网络终端上的程序。程序通过响应用户输入并且同该应用服务进行消息交换,使用户能够使用该应用服务提供的服务。AegeanStore的客户端除了完成传统网络应用的客户端的响应用户输入、网络消息交换、身份验证、数据传输等任务之外,还要在冗余数据删除技术中,完成重要的任务:因为AegeanStore使用冗余数据删除技术的目标是减少冗余数据在网络传输时造成的浪费,所以冗余数据删除中的可变数据块划分和计算每个数据块的数字指纹等工作必须在客户端完成。在获得需要上传文件的所有数据块的数字指纹后,通过应用服务提供的网络接口,查询这些文件块是否已经在AegeanStore中存在,然后将新的数据块上传到数据块服务部分,完成数据上传过程;同时,客户端需要管理已经存储在本地的数据块的数字指纹,用于下载时减少冗余数据传输。
2.2 应用服务
应用服务是以AegeanStore提供的存储服务、开发框架和功能组件为基础,构建而成的网络应用服务。AegeanStore作为网络应用开发的基础平台,为了方便应用服务的开发,提供了应用服务的开发框架,使得应用服务的开发可以忽略网络应用中网络端口监听、工作进程派生、负载均衡和调度等问题,专心解决应用服务的事务逻辑,使应用服务的开发工作更加方便快捷。应用服务开发者只需要将自己开发的消息处理模块和消息序列化/反序列化模块注册到应用服务框架当中,即可被框架自动调用,进而提供网络应用服务。除此之外,AegeanStore还为应用服务的开发者提供用户管理、网络消息交换等常用的功能组件,从而提高在AegeanStore上开发应用服务效率,降低应用服务的开发和运营成本。
2.3 文件系统服务
文件系统服务为AegeanStore提供文件系统视图和文件管理接口。目前常用的提供公共存储服务的分布式存储系统当中,普遍使用的应用程序接口是Key/Value式的。虽然这种接口在开发应用服务时使用比较方便,但是与用户习惯的基于目录结构的文件系统式接口差异较大,导致大多数构建在Key/Value接口上的应用服务都要开发功能相似的文件系统视图。这些重复开发增加了应用服务开发的难度和成本,更重要的是,因为缺少存储系统内部信息的辅助,无法利用数据的局部性和网络的就近访问等优化技术,在Key/Value接口上构建的文件系统效率往往较低,对应用服务以及存储系统的网络和存储资源造成了严重的浪费。所以,AegeanStore为应用服务开发提供的接口是文件系统式的,以提高应用服务的开发效率,避免重复开发,并通过使用分布式B树、网络就近访问、代理访问等优化技术,提高存储系统的吞吐量。
2.4 索引服务
索引服务中存储了AegeanStore中所有数据块的数字指纹的索引,并提供网络查询索引接口,用来判断数字指纹所对应的数据块是否已经存在于AegeanStore当中。以SHA-1哈希函数计算出来的数据指纹为例,每个块的数字指纹大小为20 B,假设可变块划分算法所分的数据块的平均大小为4 kB,则索引服务中存储的数字指纹索引的数据规模为实际存储数据规模的0.5%。由于AegeanStore存储系统具有良好的可扩展性,其数据规模可以达到数百太字节甚至拍字节级,所以索引服务应该支持太字节级别的索引存储。
2.5 数据块服务
AegeanStore的数据块服务提供分布式的基于内容定位的存储系统[7],其提供的接口是Key/Value形式的。数据块服务由接口、一跳分布式哈希表(DHT)[8]和数据块存储节点3部分组成:当用户存储数据块时,以该数据块的数字指纹作为Key进行存储;首先到一跳分布式哈希表中,查找该数字指纹,因为数字指纹由数据块的内容决定,所以,如果该数字指纹已经存在于分布式哈希表当中,说明该数据块已经存在于数据块服务当中,无需再次存储;如果不存在,将数据块存入数据块存储节点,将数字指纹和所存储的位置信息存入一跳分布式哈希表作为索引。当用户读取数据时,给出数据块的数字指纹。块存储服务从分布式哈希表中查找是否存在这个数字指纹,如果存在则根据在其中获得的数据块位置从存储节点读取相应数据块并返回给用户,否则返回空。
3 冗余删除技术的优化
将冗余数据删除技术应用于分布式存储系统将遇到两个问题。
(1)由于CDC算法开销过大,无法满足广域网环境中的分布式存储系统的客户端的异构性带来的计算性能瓶颈。
(2)由于分布式存储系统的高可扩展性,造成索引服务中数字指纹索引过大,从而带来的数字指纹索引查询的性能瓶颈。
3.1 CDC算法的优化
CDC算法中,无论在计算滑动窗口内的哈希值,还是获得数据块划分之后计算数据块的数字指纹都是计算密集型工作。在手机或上网本等运算能力较差的设备上,由于存在着性能瓶颈,制约了客户端相关的冗余数据删除技术的有效应用。
首先,在AegeanStore的客户端中,为了优化CDC算法的运行效率,在计算滑动窗口的哈希值时,采用了Rabin’s Fingerprinting[9]哈希函数进行计算。因Rabin’s Fingerprinting哈希函数具有可迭代计算的特性,滑动窗口时,只需要通过将滑动前哈希值、滑入字节值和滑出字节值进行复杂度为O(1)的计算,即可获得滑动后的窗口内部字节数组的哈希值。因为每个字节的数值最多有256种可能,可以通过预先的计算,将滑入和滑出字节相关的计算制成表格,之后,只需要通过查表和简单的位移操作和加减操作即可获得滑动后的哈希值,大大提高了CDC算法的运算效率。
其次,AegeanStore引入了双阈值双除数算法(TTTD)[10],对CDC算法进一步优化。TTTD算法规定了数据块大小的最小值Smin。每一个可变数据块从开始到Smin的区间内的数据不需要进行哈希值计算。TTTD算法是为了对付可变数据块划分结果中数据块大小差异太大而造成的冗余删除率较差的问题,经试验证明,Smin:S约等于0.85时,可以获得最好的冗余删除率。所以使用TTTD算法可以大大降低冗余数据删除的计算开销,提高AegeanStore客户端的运行效率。
3.2 索引服务的优化
AegeanStore的索引服务通过采用3种优化方法,改进索引服务的数字指纹查询效率,以提高冗余数据删除技术在分布式存储系统中的性能。
(1)基于文件的批量数字指纹查询
AegeanStore提出了基于文件的批量数字指纹查询协议,将相同文件的数据指纹列表,连同该文件的路径、大小等元数据信息,组织到同一个文件上传请求当中。经过这样的优化,既减少了AegeanStore客户端的网络请求数,增大了每个请求的数据量,提高网络资源的利用率;并且,让索引服务一次可以处理很多个数字指纹的索引查询,增加了索引服务的吞吐量;更重要的是,使同一个文件的数据块的数字指纹之间所存在的局部性得以保持,为索引服务进行预取和缓存等进一步优化创造了条件。
(2)基于Bloom filter的快速新数据块过滤
Bloom filter[11]是一种高效的利用有限的内存空间,以一定错误肯定率为代价,用于快速的判断某一个元素是否在一个集合中的概率性数据结构。在AegeanStore的索引服务当中,使用一台性能较好、内存空间较大的服务器来运行快速新数据过滤模块。一个存于内存中的Bloom filter作为该模块的核心数据结构。当接收到由请求节点转发来的基于文件的批量数字指纹查询请求之后,将其中每一个数字指纹送到Bloom filter中进行判断其是否存在于AegeanStore当中。如果判定结果为可能存在,则将其忽略;如果为一定不存在,则将这个数字指纹标记为新数据块;将标记后的数字指纹列表,返回给请求节点;最后,当数据块被成功上传到数据块服务之后,将其对应的数字指纹加入到Bloom filter当中。
(3)基于文件局部性的缓存和预取
文件局部性是指出现在相同文件中的数据块,再次出现在相同文件中的概率会比较高。文件局部性通过使用基于文件的批量索引请求被保存到索引服务当中,与某数字指纹具有文件局部性的其他数字指纹的列表称之为局部性列表。缓存和预取节点中的缓存的数据结构提供Key/Value式的接口,同样以数字指纹作为Key,以其局部性列表作为Value。当索引查找的数字指纹列表被分配到某个缓存和预取节点后,处理流程如下:对于每一个没有被标记为新的数字指纹,首先到缓存中查找该数字指纹,如果命中,说明该数据块已经存在于AegeanStore当中,将文件的数字指纹列表和缓存中局部性列表合并,并在结果中标记该块为存在;若未命中,则到DHT中进行查找,如果命中,将DHT中存储的局部性列表加入缓存当中,完成预取工作,之后的处理和缓存命中时相同;如果未命中,即该数据块不存在于AegeanStore当中,在快速过滤模块当中出现了错误的情况。
4 结束语
本文提出了广域网环境下的分布式存储系统原型AegeanStore。AegeanStore在提供互联网上的存储服务的同时,还为网络应用的开发提供了框架和通用的功能模块,以提高网络应用开发和运营的效率,并降低其成本。分布式存储系统中普遍存在的冗余数据,不仅浪费了存储系统的资源,而且造成了存储系统的性能损失。AegeanStore通过采用客户端相关的冗余数据删除技术,可提高对存储资源以及网络资源的利用率,降低运营成本,提高可扩展性以及整体性能。
5 参考文献
[1] Amazon Simple Storage Service (Amazon S3) [EB/OL]. [2010-06-16]. http://aws.amazon.com/s3/.
[2] 敖莉, 舒继武, 李明强. 重复数据删除技术研究综述 [J]. 软件学报, 2010,21(5):916-929.
[3] Cryptographic Hash Function [EB/OL]. [2010-05-25]. http://en.wikipedia.org/wiki/Cryptographic_hash_functions.
[4] DENEHY T E, HSU W W. Duplicate Management for Reference Data [R]. Research Report. RJ 10305 (A0310-017). San Jose, CA,USA: IBM. 2003.
[5] BRODER A Z. Identifying and Filtering Near-duplicate Documents [C]//Proceedings of the 11th Annual Symposium on Combinatorial Pattern Matching(CPM’00), Jun 21-23, 2000, Montreal, Canada. Berlin, Germany: Springer-Verlag, 2000:1-10.
[6] HUNT J W, MCILLROY M C. An Algorithm for Differential File Comparison [R]. Computing Science Technical Report 41. Stanford, CA, USA: Stanford University, 1976.
[7] TOLIA N, KOZUCH M, SATYANARAYANAN M, et al. Opportunistic Use of Content-addressable Storage for Distributed File Systems [C]//Proceedings of the 2003 USENIX Annual Technical Conference (USENIX’03), Jun 9-14, 2003, San Antonio, TX,USA. Berkeley, CA, USA: USENIX Association, 2003: 127-140.
[8] GUPTA A, LISKOV B, RODRIGUES R. One Hop Lookups for Peer-to-peer Overlays [C]//Proceedings of the 9th Conference on Hot Topics in Operating Systems (HotOS’03), May 18-21, 2003, Lihue, HI,USA. Berkeley, CA, USA: USENIX Association,2003: 7-12.
[9] BRODER A Z. Some Applications of Rabin's Fingerprinting Method [M]//CAPOCELLI R, DE SANTIS A, VACCARO U. Sequences II: Methods in Communications, Security, and Computer Science. Berlin, Germany: Springer-Verlag, 1993: 143-152.
[10] ESHGHI K, TANG H K. A Framework for Analyzing and Improving Content-based Chunking Algorithms [R]. TR 2005-30. Hewlett-Packard Labs. 2009.
[11] BRODER A, MITZENMACHER M. Network Applications of Bloom Filters: A Survey [J]. Internet Mathematics, 2004,1(4): 485-509.
尹玉冰,清华大学高性能计算研究所在读硕士研究生,主要研究领域为存储系统。
孙竞,清华大学高性能计算研究所在读博士研究生,主要研究领域为分布式系统。
余宏亮,清华大学高性能计算研究所副教授、博士,主要研究领域为并行与分布式系统,曾作为主要成员参与和负责了5项国家级基金项目的研究工作,已在国内外重要学术刊物和会议上发表论文30余篇。