
基于Intel IXP2400和GP-CPU的NAT系统的设计和实现
2008-11-19
作者:司 靓1,2, 于晓娟3, 李昀
摘 要: 提出了一种基于可编程网络处理器IXP2400和GP-CPU的NAT/NAPT" title="NAT/NAPT">NAT/NAPT的实现方案,设计并实现了基于Intel IXP2400和GP-CPU所组成的具有安全防火墙功能的NAT系统。针对该NAT系统进行了性能分析,它能够支持六十多万并发TCP/UDP的连接容量与全线速为2Gb/s以太网连接速率,有效提高了NAT/NAPT的操作速度,克服了传统NAT实现方案中的性能瓶颈。
关键词: 网络处理器; IXP2400; NAT; NAPT; 微引擎
在现代通信网应用中,网络地址转换NAT(Network Address Translation)技术是IETF提出的有效解决IPv4面临的网络地址枯竭问题的方案之一,是为提高网络地址利用率、缓解IPv4地址枯竭压力而采取的一种有效策略。与此同时,为满足互联网络对高性能与灵活性的要求,网络处理器作为一种可编程的高速处理器应运而生,它是新兴的下一代网络设备的核心,它综合了GP-CPU(通用处理器)的完全可编程特性和专用处理器ASIC(Application Specific Integrated Circuit)的高速处理能力的优点,有效地兼顾了网络设备的功能灵活性和性能强大性。因此,不但提高了网络服务的处理能力而且还具有高线速处理性能,从而能够很灵活地适应网络的各种业务性能要求[1]。
对于传统的基于GP-CPU或ASIC的NAT处理复杂、负荷过重而造成的性能瓶颈,本文提出了一种基于IXP2400和GP-CPU的NAT系统的实现方案,成功地实现了基于有效的全局地址或用户配置的饱和度来执行NAT模式(包括静态NAT与动态NAT)与NAPT模式(Network Address Port Translation,网络地址与端口转换)的动态切换功能,最高效地实现了网络地址复用,同时大大提高了NAT/NAPT的地址转换能力,克服了传统的NAT网络应用方案中因数据帧头处理时间过长所导致的难以保持在NPs上一定的线速问题。
1 网络处理器IXP2400和NAT/NAPT的概述
1.1 网络处理器IXP2400简介
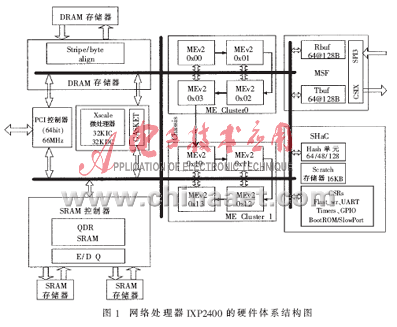
网络处理器IXP2400是用来执行数据处理" title="数据处理">数据处理和转发的高速可编程处理器,由一个Xscale Core(智能协处理单元,即32bit的嵌入式精简指令集处理器)、8个微引擎" title="微引擎">微引擎Microengines(简称MEs),以及标准存储接口单元和网络接口单元等部分组成。IXP2400的硬件体系结构如图1所示。IXP2400硬件体系结构的详细描述主要来自于参考文献[1]、[2]。
1.2 NAT/NAPT综述
NAT具体可分为三种类型:静态NAT、动态NAT和NAPT,分别用来支持IP地址转换以及IP地址与TCP/UDP端口数据转换。
NAT映射一个内部的IP地址到一个公网IP地址。当数据包穿过NAT时,不更换它的TCP/UDP端口号。NAT通常使用在一些具备公共IP地址池的NAT上,通过它可以进行地址绑定,即代表一台内部主机。NAPT 则是一种动态地址转换,它将一个由内部IP地址和TCP端口号组成的二元组映射到一个由外部IP地址和TCP端口号组成的二元组,从而允许多个内部IP地址共用一个合法外部IP地址[3]。二者都提供了一种机制:实现内网的IP地址与公网的IP地址之间的相互转换,并将大量的内网IP地址转换为一个或少量的公网合法的IP地址。因此,IP地址转换的应用势在必行。
2 基于IXP2400和GP-CPU的NAT系统的设计与实现
2.1 系统硬件的设计与实现
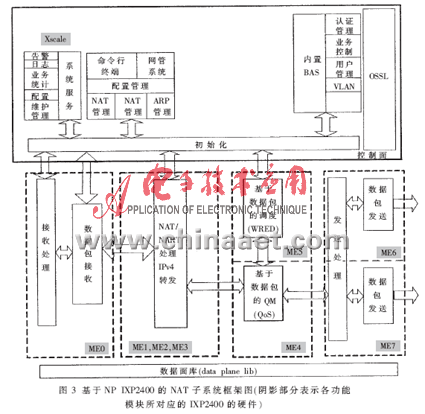
该系统设计的最终目标是要通过基于IXP2400和GP-CPU来实现具有安全防火墙功能的NAT/NAPT的应用方案。该系统的硬件体系结构如图2所示,其中,基于NP IXP2400的NAT子系统是实现整个NAT系统核心功能的重要组成部分,也是整个NAT系统取得高性能的关键之所在,其结构图如图3所示。
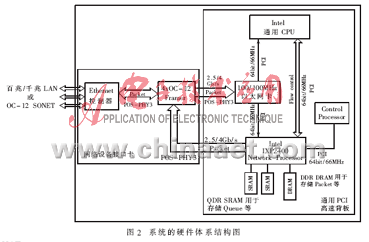
该系统的实现平台主要是由一片集成了时钟频率为600MHz的IXP2400的板卡、通用PCI高速背板、一片集成有GP-CPU的主板(即主机系统)、运行嵌入式VxWorks实时多任务操作系统、IDT公司的 PAX.Ware 2500i Media Interface Card、一个100/1000M以太网卡,以及Intel IXA SDK4.2[5]和相关的构建框架(Framework)等部件所组成。
基于IXP2400和GP-CPU的NAT系统能够提供线速4Gb/s的以太网实现方案[6],并同时支持IPv4的单播转发。作者通过编辑内核相关的代码,使GP-CPU具有第二到四层数据包过滤功能;同时通过Intel IXA SDK4.2编辑相关的微代码,并映射到NP IXP2400中创建一个NAT/NAPT功能模块,从而实现具有安全防火墙功能的NAT系统的应用方案。
2.2 NAT子系统的软件模块设计与实现
基于NP IXP2400的NAT子系统的数据流程示意图如图4所示。作者把NP IXP2400的8个微引擎分别对应地分成具体的功能模块: Packet RX模块、NAT/NAPT处理和IPv4转发功能模块、Queue Manger模块、Packet Scheduler模块以及Packet TX模块。在设计方案当中,接收、队列管理及调度这三个功能模块各占用一个微引擎,而数据包的发送模块要占用两个微引擎来发送数据包,其余三个微引擎用于NAT/NAPT和IPv4转发的数据处理阶段。在NAT/NAPT数据处理阶段中,微引擎的分配使用是通过微引擎内部的指令执行周期与时延" title="时延">时延周期的数据分析来决定的,这一点将在2.3节中进一步说明。
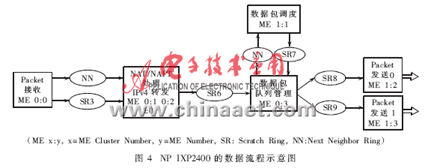
在NP IXP2400中NAT/NAPT的数据处理的详细模块,如图5所示。 在Xscale Core(即控制面)与微引擎之间的通信过程中,有两个Scratch Rings(SR0和SR1)按照优先排序的方式处理数据并控制数据包。作者所设计的NAT功能模块既可以通过手动配置运行静态NAT模式,同时也可以基于数据包运行动态NAT模式。
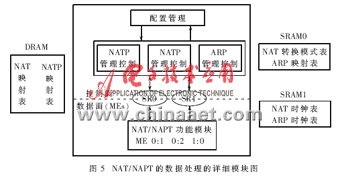
该NAT系统控制着NAT处理模式与NAPT处理模式的转换,这种控制机理的实现是基于有效的全局地址或用户配置的饱和度,确保内部网络用户对外部网络不间断的访问,并能够支持更多的网络服务。所以,Xscale Core与 NAT/NAPT MEs(图5)之间的通信是必不可少的,因为Xscale Core 管理控制着NBT(NAT/NAPT Binding Table,网络地址/端口转换映射表)而NAT/NAPT MEs 则是根据Xscale Core 所管控的 NBT 中所提供的信息来对数据包进行处理的。NAT子系统中NAT/NAPT模式的转换是根据SRAM0中存储的NAT转换模式表来实现的,如图5所示。在NAT子系统中运用这种模式转换方案可把模式转换带来的数据传输中断的影响降到了最低限。
2.3 NAT/NAPT功能模块的微引擎分配
为了保持数据处理达到2Gb/s的全线速,NAT/NAPT功能模块基于每个微引擎在处理数据包时,都要求在连续数据包的间隙内进行处理。笔者将NAT/NAPT模块的功能映射到微引擎上来执行,是通过估算有效指令执行周期与I/O" title="I/O">I/O时延周期来实现的。在以太网接口层,最小的链路层数据帧的大小为84B(最小的以太网数据帧是64B,再加上帧间的数据帧头是20B)。当线速为2Gb/s时,如果数据包的大小是84B,数据包的吞吐量将达到每秒钟处理2.976M个数据包。其中,连续两个84B的数据包的间隙为336ns。
PacketInterArrivalTime(ns)=PacketSize(Bytes)×8/DataRate(Gb/s)
上式中的帧间间隙可以被设置成子系统中处理器的时钟,并由下列公式推导得出。由于NAT子系统是基于IXP2400来实现的,而IXP2400的时钟频率为600MHz,因此,该处理器的时钟应为1.67ns。
PacketArrivalTime(ProcessorCycles)=PacketInterArrivalTime(ns)/ProcessorClockTick(ns)
所以,整个数据处理流程(如图4所示)中的任何一个处理进程都必须能够在特定周期(符合这种周期算法)内完成所要求的所有接收到的数据包的处理,而且,每个处理进程都应该能够达到每202个周期处理一个新的数据包的处理速度,以支持2.0Gb/s的全线速。
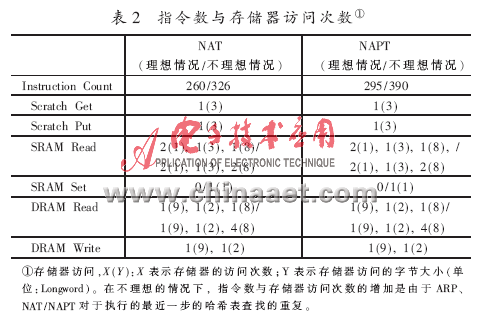
微引擎对数据包的处理包括:对内存储器和外存储器的访问,例如:Scratch Memory、SRAM、DRAM等。访问存储器的时延与相邻数据包之间的间隙是近似的,例如:SRAM存储器的访问时延大约是150 Cycles,而DRAM存储器的访问时延大约是250~300 Cycles[7]。每个微引擎内部有8个硬件线程(Context),采用多线程交换(Multi-Threading)技术时,由相应的硬件结构提供支持,由软件指令来控制,可以将存储器的访问时延隐藏在指令执行周期的后面,因此,提供一个I/O时延周期相当于数据包传输速率的8倍,即一个I/O时延周期总计为8×202=1 616 Cycles(即8倍的以太网传输模式上的IPv4数据包最短到达时间),这样充分发挥了微引擎的MIPS性能,提高了系统的并行处理能力。表1展示了不同的NAT/NAPT功能模块中的微引擎数量组合(1ME、2MEs、3MEs)所对应的有效指令执行周期与I/O时延周期的值的变化。如果使用两个微引擎执行NAT/NAPT处理,则上述两种周期的值要比只有一个微引擎处理时增加两倍,因为两个MEs具有16个硬件线程,这样可以并行处理16路数据包。表2展示了估算的指令执行次数和NAT/NAPT功能模块中存储器访问的次数。在不理想的情况下,根据每个存储器访问类型[7]的时延的数值计算得出,执行NAPT处理时的I/O时延周期大约为2 880 Cycles。 因此,单个微引擎的指令执行周期与I/O时延周期要小于两个微引擎的指令执行周期与I/O时延周期。所以,笔者设计此NAT/NAPT处理和IPv4转发功能模块应当配置三个微引擎并行工作,来支持网络所要求的数据处理速度。这一分析结果将在下节的软件仿真测试中被证实。

3 NAT系统的性能分析
这项仿真测试运用了IXP2400 Developer Workbench专用软件开发平台,通过编译微代码来实现数据的仿真。在测试当中,Workbench编译器使用的参数设置都是默认值。
3.1 最大连接速率/最大会话速率
该性能测试为系统的TCP会话处理性能和峰值速率性能的测试集合。在性能测试之前,ARP的映射条目与NAT/NAPT的转换条目采用动态配置的形式,关于最大连接速率与最大会话速率的测试:是通过固定的数据帧长度(84B)与60个客户机和一个服务器来完成的。这项测试结果表明了所设计的NAT系统完全能够以全线速处理数据包。
3.2 平均转发速率
在这项仿真测试过程中,当所有数据包的NMT查找采用一次地址冲突量(N-depth)匹配的方式时,以最小长度64B以太网帧生成于每个网络地址,而且NBTs 的查找模式以N-depth匹配方式被静态设置,所有的数据包都汇成一股数据流,执行NAT/NAPT处理的微引擎中的每个线程都会同时去访问NMT,这样就会引起DRAM存储器访问的冲突。当哈希冲突的次数不断增加时,DRAM存储器的负担就会增大而且DRAM存储器的访问时延也会大大增加,再加上等待数据读入线程的开销,执行NAT/NAPT处理的微引擎中线程将会产生过度的时延。图中曲线的走势说明:随着NBT查找匹配的一次地址冲突量的增加,将会导致平均转发速率逐渐地降低。
3.3 时延分析
将本NAT系统(包含:子系统中的NAT/NAPT功能模块)的时延与不具有NAT/NAPT功能仅仅只提供简单的数据包转发功能的系统的时延进行了对比。在对NAT系统的测试当中,ARP的映射条目与NAT/NAPT的转换条目采用静态配置的形式。通过对两个不同的系统的性能仿真测试结果进行对比,得出以下结论:①与不具有NAT/NAPT功能的系统的时延相比,具有NAT/NAPT功能的系统的时延要增加6%~30%。②时延的平均增长比率是根据数据包的大小的不同而变化的,也就是说,如果数据包的大小在64B~256B范围内,其时延的平均增长比率为25%;如果数据包的大小在512B~1 518B范围内,其时延的平均增长比率为9%。以上测试结果表明:基于NP的NAT/NAPT功能模块需要对数据包头进行深度地处理。
NAT技术,对于当前的IPv4网络中的地址耗尽和路由表的规模扩大是一个很有效的解决方案,因为网络扩大时它需要很少的改变,并能很快地实现地址复用。作者设计出一种基于IXP2400和GP-CPU的NAT系统实现方案,成功地实现了地址复用,并且微引擎的多线程交换技术与并行处理能力有效地提高了系统的NAT/NAPT模块数据处理的性能,解决了传统NAT实现方案中的性能瓶颈。
在未来的工作计划中,作者为了减少系统数据处理产生的哈希冲突次数,计划创建一个新的哈希函数来减少哈希冲突,还要重新设计哈希表的数据结构来提高存储器的利用率,最小化存储器的访问时延。
参考文献
[1] Intel. Intel IXP2400 Network Processor Hardware Reference Manual [M/CD] . USA: Intel Corporation, Oct.2004. [2] 张宏科,苏伟,武勇. 网络处理器原理与技术[M].北京:北京邮电大学出版社,2004,11:18~138.
[3] STEVENS R W. TCP/IP Illustrated, Volume 2: The Implementation[M]. Beijing: China Machine Press,April.2000: 63-560.
[4] Integrated Device Technology. IDTTM PAX.wareTM 2500i Evaluation System. 2004.
[5] Intel. IXP2400 and IXP2800 Network Processor: Programmer’s Reference Manual[M/CD]. USA: Intel Corpora-
tion, Jan. 2005.
[6] Intel. Internet Exchange Architecture Software Building Blocks Reference Manual [M/CD]. USA: Intel Corporation, Feb. 2003.
[7] LAKSHMANAMURTHY S, LIU K, PUN Y, et al.Network Processor Performance Analysis Methodology[J]. USA:Intel Technology Journal, Aug. 2002,6(3):19-28.