
摘 要: 本体映射的关键技术是本体相似度计算。本文基于已有的V-Doc(虚拟文档)技术提出一种新的NV-Doc本体相似度计算方法,其中不仅用到了本体中实体自身以及其第一层相邻节点的信息,而且还充分利用了第二层相邻节点的信息。
关键词: 语义网;本体映射;虚拟文档;本体相似度
本体是共享概念化的明确具体规范,随着语义网的发展,本体的应用越来越多。用RDF[1]或OWL[2]书写的Web本体在语义网的出现和应用方面起到了很大作用,本体的数量也与日俱增。
Web的分布式特点使得大量的本体由不同组织开发,并且在很大程度上覆盖相同或者相交的领域,因此Web本体之间存在一定的相似性,但相关领域的不同本体之间也存在很大的异构性。
解决本体异构问题的最好方法是本体映射。本体映射的目的是架起异构本体之间的桥梁,在使用不同本体的Web应用之间建立互操作,从而实现语义网环境下数据的集成与管理。而本体映射的关键技术是本体的相似度计算,即计算两个不同本体中实体之间的相似度,当相似度值大于某个给定的阈值时,可以认为这两个实体之间存在着一定的语义关系。
目前,关于本体相似度计算方法的自动化程度不高,而且不能充分利用本体的各种描述信息。已有的V-Doc技术能够较好地解决这两方面的问题,但也存在一些不足。
基于虚拟文档的本体相似度计算方法V-Doc[3]将本体看成一个有向图,图中的每个节点对应本体中的一个实体,为每个实体自动建立虚拟文档,充分利用了节点自身和邻接节点的描述信息。但该方法也存在不足:节点的特征不仅与邻接节点有关,而且还与邻接节点的邻接节点信息有关,即实体的描述信息还应该考虑节点的第二层邻接节点的信息。针对其不足,本文提出一种新的基于虚拟文档的本体相似度计算方法NV-Doc。
1 V-Doc简介
1.1 虚拟文档的构建
虚拟文档是为了描述概念特点而建立起来的文档,为每一个节点构建虚拟文档,充分利用节点自身和邻接节点的描述信息。
定义1 (URIrefs描述):假设e是一个URIref,对e的描述通过与其有关的名字、标签、注释和其他自然语言描述信息组成,其定义[3]为:

1.2 相似度计算
本体中每一个实体(节点)的描述信息(语言学特征)通过该节点的虚拟文档表示。因此,两个本体中实体的相似度可通过计算与之对应的两虚拟文档之间的相似度而得到,即虚拟文档之间的相似度就是实体之间的相似度。虚拟文档之间的相似度通过在信息检索领域应用广泛的向量空间模型VSM(Vector Space Model)[4]方法计算。将两个待匹配的虚拟文档用向量空间中的一个向量表示,当然在相似度计算之前还要对文档进行预处理,如分词、去除停用词、提取词干等。向量空间模型中,关键词的权重使用TF/IDF技术[5]表示。由此可以得到一个N×W的矩阵X,其中N是虚拟文档的个数,W表示所有虚拟文档中token的总数。可以通过矩阵与其倒置矩阵的积得到虚拟文档之间的相似矩阵,最后规范化相似矩阵,使相似度值在[0,1]区间内。规范化后所得矩阵即为虚拟文档之间的相似度矩阵,每个值也代表了两个虚拟文档之间的相似度,从而得到与之对应的两实体之间的相似度。
2 NV-Doc
2.1 改进的虚拟文档
为RDF图中每一个节点构建虚拟文档,不仅用到节点自身以及相邻第一层的邻居节点信息,还用到节点第二层的邻接节点信息。
定义3 (改进的虚拟文档):假设e是一个URIref,e的虚拟文档NVD(e)的表示方程为:

2.2 简单示例
假设一个简单的本体片段模型如图1所示。
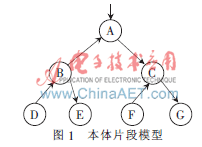
按照式(3)得到节点A的虚拟文档为:

3 实验结果及分析
3.1 实验数据
实验数据选用基于KAON2的开源资源Framework for Ontology Alignment and Mapping中所提供的Test Ontologies and Alignments。从中选用本体规模较小的russia1.owl和russia2.owl作为数据源,其中russia1中共有49个节点,russia2中共有51个节点。进一步的实验选用数据集OAEI 2005 benchmark tests中的五组规模稍大的本体作为数据源。 本文两次实验中各参数的取值不变:α1、α2、α3、α4的值分别为1.0、0.5、0.25、0.25,参数γ1、γ2、γ3、γ4的值分别取0.1、0.1、0.05、0.05。各参数的取值借鉴Falcon-OA[6]系统在程序中所给的参数值。对于实体的描述,第一层邻接节点一般比第二层邻接节点更有影响力,所以γ3、γ4分别取0.05、0.05,比γ1、γ2的值0.1、0.1都小是有道理的。
本文采用查准率和查全率的综合评估函数以及运行时间作为评价标准对实验结果进行评估。

3.2 实验结果及分析
本文主要的改进之处是提出新的算法来构建本体中实体的虚拟文档,虚拟文档间的相似度计算也是通过描述的方法实现,初步实验结果如表1所示。

初步实验结果:表明改进的算法虽然在运行时间上有所延长,但查准率和查全率都有所提高,而且这种时间消耗不是很大。
其次,为了再一次验证NV-Doc较V-Doc的可行性,对数据集OAEI 2005 benchmark tests中的五组本体进行实验,最后得到的实验结果如图2、图3所示。
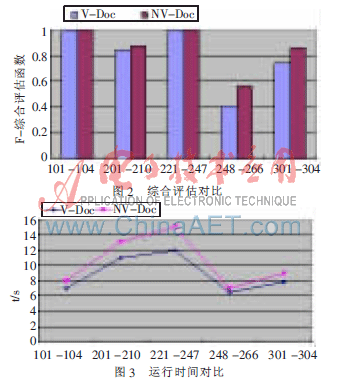
再次实验结果表明,NV-Doc能够取得比V-Doc更好的查全率和查准率,虽然在效率方面不及V-Doc,但从整体上来看,效率上的部分损失换来更好的查准率和查全率也是值得的。
本文针对计算本体中实体相似度存在的问题提出改进方法,充分利用实体自身和实体的第一层及第二层邻接节点的描述信息(即实体的语言学上的特征)。实验结果分析表明,改进后的算法在查准率和查全率方面优于原先的算法。下一步的研究工作是:一方面将此方法和其他计算本体相似度的方法有效结合,从而更有效地实现本体映射;另一方面是减少运行时间,提高效率。最后还要充分利用本体其他的描述信息,如本体的属性、关系、实例等。
参考文献
[1] KLYNE G, CARROLL J J. Resource description framework (RDF): concepts and abstract syntax.//W3C Recommendation 10 February 2004. Latest version is available at http://www.w3. org/TR/rdf-concepts/.
[2] Patel-Schneider P F, HAYES P, HORROCKS I. OWL web ontology language semantics and abstract syntax. W3C Recommendation 10 February 2004. Latest version is available at http: //www. w3. org/ TR/owl-semantics/.
[3] QU Yuzhong, HU Wei, CHENG Gong. Constructing virtual documents for ontology matching[C]//Proceedings of the 15th International Conference on W orld W ide W eb.Edinburgh,Scotland: [S.n.],2006.
[4] VIJAY V, RAGHAVAN S K, WONG M. A critical analysis of vector space model for information retrieval. JASIS, 1986: 37(5), 279-287.
[5] SALTON G, MCGILL M. Introduction to modern information retrieval[M]. McGraw-Hill Book Company,1984.
[6] Hu Wei, Qu Yuzhong. Falcon-AO: a practical ontology matching system[C]. Web Semantics: Science, Services and Agents on theWorldWideWeb, 2008: 237-239.