
基于IP-core的64位PCI接口设计与实现
2009-01-14
作者:王 伟, 符 权, 徐佩霞
摘 要:介绍一种Linux下的基于64位PCI总线和多片FPGA的高速计算平台的设计和实现,利用Altera公司的PCI软核——PCI_mt64构建此平台的PCI桥接口模块,设计出一种兼容总线宽度64位/32位、时钟66MHz的PCI规范的接口模块,以及与此相配合的DMA状态机,并给出Linux驱动的关键部分。
关键词: PCI_mt64; 现场可编程门阵列; DMA; Linux驱动
PCI(Peripheral Component Interconnection)总线接口是目前一种应用广泛、可兼容支持32/64位的局部总线接口,它同时支持多组外围设备,不受制于处理器,数据吞吐量大(32位时峰值高达132MB/s,64位时峰值高达528MB/s)[1]。连接到PCI总线上的设备分为主设备和从设备,接口设计成为PCI总线与设备进行数据传输的桥梁。但是,PCI总线协议十分复杂,不容易实现。目前实现PCI接口的有效方案有两种:使用专用总线接口器件和专用PCI软核IP-core。
目前,业界基于32位PCI总线使用较多的接口芯片是AMCC公司的S59xx系列和PLX公司的PLX系列。而对于64位的PCI总线,目前PLX公司的9656芯片虽然可以支持,但在设备本地端,9656芯片只能提供32位的接口,并不是完全的64位PCI接口芯片,数据的处理速度因此而受到限制。
另一方面,Linux操作系统是一种基于GNU通用公共许可证(GPL)架构下、源码公开的免费操作系统,继承了Unix稳定有效的特点,采用先进的内存管理机制,能有效地利用物理内存;与Windows相比,Linux在安全性、漏洞修补上都具有其独特的优势,因此,目前Linux在工业、政府部门都有着广泛的应用。
本文介绍一种在Linux操作系统下的、64位66MHz高速PCI的FPGA通用并行计算平台的设计与实现。该平台采用Altera公司提供的IP软核PCI_mt64[2-3],自行设计本地端64位桥接口;同时,采用多片FPGA运行不同的算法,并在FPGA内部实现算法的并行化,从而大大提高了PC机对大运算量的数字信号处理的能力。系统已成功应用到MD5 的快速解密。
1 系统设计的目的
目前信号处理对于实时性要求的提高,虽然也使CPU的运算频率日益提高,可以大大提高某些大运算量应用计算的速度,但是独占CPU资源并不是一个很好的选择;同时由于成本及其他因素的考虑,也不可能专门使用多台小型机进行计算。在这种情况下,将信号处理算法并行化,运行于高性能的FPGA,并通过适当的总线接口,可以达到既不占用CPU资源,同时又有多台小型机同时运算的性能。
本硬件平台的设计目的是将64位66MHz的PCI接口与FPGA结合起来,使得该硬件平台既可以保证数据量的高速吞吐和数据处理的实时性要求,又可以在运算处理过程中不占用CPU资源。另外,由于采用多片高性能FPGA,因此也可以选择在该平台上同时运行多个算法,如阵列信号处理中的DOA算法、波束形成算法等。
以下对端口的定义及说明均是基于实现该算法,而整个系统平台适用于多种大计算量的数字信号处理。
2 系统硬件架构
本系统利用1片Altera 公司的EP1S20F780C7芯片作为桥芯片,负责加载本地桥模块、配置算法FPGA、DMA操作、数据轮询下发以及运算结果上行接收和中断;采用4片Altera公司的 EP2S60F484C5作为数据处理芯片,可以加载不同的信号处理算法,从而实现平台的通用化。
在该系统架构中,PCI桥模块的设计实现、DMA状态机的操作流程和中断的处理是其中的重点和难点,下面分别予以说明。
2.1 PCI桥模块的设计
在本系统中,为了缩短开发周期,采用了Altera公司的IP软核PCI_mt64,这样系统的设计就规避了PCI局部总线规范和PCI配置寄存器的实现,而能够集中精力进行本地桥模块的设计。本地桥模块结构如图1所示,其基本设计思想如下:

(1)桥模块要实现对I/O空间与Memory空间的管理、各种控制信号(包括中断)的产生和数据流的处理。其中,I/O空间定义一般寄存器和中断寄存器;Memory空间则包括了DMA寄存器和FIFO初始地址寄存器,其又包括以下子模块:Interrupt模块、FIFO管理模块和DMA引擎(FIFO、Memory空间实现方式)。其中FIFO管理模块又可根据功能划分为三个部分:桥FIFO(Bridge FIFO)、结果数据FIFO(Result FIFO)和FPGA配置FIFO(FPGA Configure FIFO)。
中断模块发出DMA传输的相关控制中断,如完成中断、算法运算结果的相关中断。在本系统中,算法结果中断分为三种,分别对应于运算有结果、运算中断查询和运算无结果,这三种类型中断由算法FPGA通过串行接口通知桥模块。由于串行命令的可编码,因此中断种类可以根据不同的算法、不同的场合而更改。
在桥模块中,最重要的部分是主从控制模块的实现,其功能是执行与PCI-core的交互、响应PCI中的控制信号,并发出相应的、符合PCI时序的主从控制信号。
(2)主从控制模块中,Local Target部分只负责对32位寄存器的读写,功能较为简单,不需要启动DMA操作,在Linux驱动中可以在IOCTL中通过writeX( )和readX( )两个函数对存储空间进行读写,也可以通过inX( )和outX( )两个函数对I/O空间读写寄存器。其中X表示数据类型:l表示long word,w表示short word,b表示byte[4]。
(3) Local Master要进行大数据量读写,需要兼容32/64位,同时与DMA模块配合完成DMA数据传输,因此功能较为复杂。具体说明如下:
数据上行:上行数据(解密结果)由算法FPGA通过串行通信发送至桥模块,并经过串并转换存入Result FIFO,同时通知中断产生模块产生中断。PC机接收到中断后即准备读取数据:PC机端设置DMA寄存器(ACR、BCR、CSR),然后本地端根据DMA寄存器CSR的设置启动DMA操作,完成Master写的流程。
数据下行:由于下行数据(穷举破解使用的密钥)数据量大,而本地端的存储空间有限,因此系统采用由PC机端设置DMA寄存器(一般设置为16KB),而本地端根据寄存器和存储空间状况,实现下列操作:启动DMA、申请PCI总线、第一次PCI数据传输、传输完毕后判断数据是否全部被传输,如未全部完成则再次申请PCI传输直到所有数据传输完成,此时申请DMA完成中断。这个过程即是Master读的流程。
在上下行的数据通路中,DMA的启动首先是由PC机端写入DMA控制寄存器(字节计数寄存器BCR,地址计数寄存器ACR)开始,再写入控制状态寄存器CSR中的启动位。主从控制模块检测到启动位置高后,即开始DMA主模式状态机的实现。
2.2 主模式下状态机的实现
主动传输时DMA状态机的实现如图2所示,其各状态说明(DMA状态机的编号与图2相对应,如表1所示。其中重要的状态转移条件说明如下:


(1) WR_BUSY转DONE:PC请求的数据全部传输完成,或上行FIFO空,或DMA从设备要求断开。
(2) RETRY转DONE:当申请再一次的PCI数据传输时,检查下一次需要传输的数据量是否满足PCI传输的要求,如条件不满足,转入DONE。
(3) RD_BUSY转DONE:PCI数据传输尚未结束,下行FIFO已满,或本次PCI传输结束,并且DMA_BCR要求的数据已全部传输结束,或DMA从设备要求断开
(4) RD_BUSY转RETRY:当本次PCI进入传输期、PCI总线要求重新申请时,或者当前PCI的数据传输结束,而未传完DMA_BCR要求的数据量。
(5) IDLE转LOAD:DMA_CSR寄存器启动位置位,DMA_BCR符合DMA传输要求,本地端下行FIFO可写或上
行FIFO内有数据。
2.3 DMA方式
Altera公司的PCI_mt64对进行内存读写的单次PCI传输数据量的限制:如果用总线Memory Read命令,则每次仅可以传输16个字节的数据;如果总线用Memory Read Multiple命令,则每次最多可以传输4 096B的数据。由于本系统的目的在于运行MD5快速解密算法,PC经PCI下发到设备的数据量是巨大的(GB量级),若由PC机端来进行多次写DMA寄存器然后启动DMA,则其软件耗时不可忍受;而当该平台应用于实时数据处理时,软件耗时必须尽可能减小。因此,需要设计一种新的DMA传输方式:即由PC机端写一次DMA寄存器,而由本地端进行多次DMA申请。
图3给出了当PC机申请16KB数据传输时,一次PCI传输即4 096字节传输完、等待7个时钟周期后(状态Retry,mst_state = 6),再次申请总线并开始PCI传输的过程。

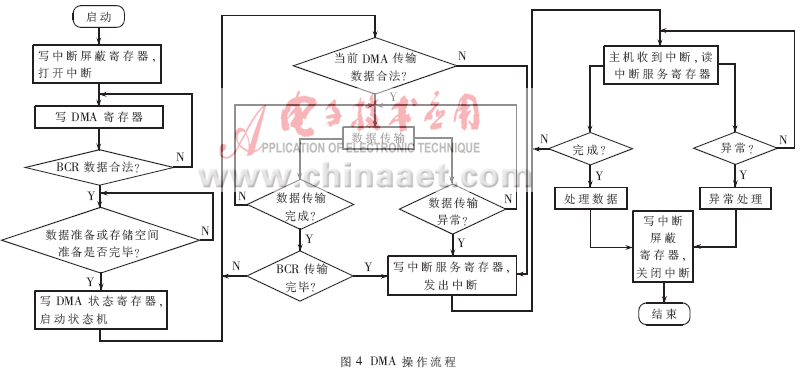
链式DMA可以认为是一组DMA的进行,并且每次DMA的数据包大小和地址可以不同[5]。同样这里采用的DMA也可以认为是一组DMA的进行,与链式DMA的区别在于DMA的读写地址必须是连续的,而相同点在于与每次传输的数据包的大小也是可以调节的。在DMA数据地址是连续的情况下,与链式DMA要写入多次DMA描述符相比,本系统采用的DMA方式只需要写一次DMA描述符,因此可以更有效率地完成DMA操作,其操作流程参如图4所示。同时由于本系统状态机中已存在的LOAD状态,若该状态用于从DMA描述符FIFO中读取描述符,则本文的DMA状态机也可以用来实现链式DMA。
2.4 Linux中断处理
Linux对于中断的处理与Windows是不同的,比较灵活,下面作简单介绍。
Windows中断处理,首先在中断响应函数中对PCI中断做判断,如果是本设备的中断则做简单操作(非数据处理),然后调用DPC(延时过程调用)例程,在中断处理函数中做中断处理中未完成的操作,如将数据由内核缓冲区拷贝到用户缓冲区。
对比Windows,Linux的中断设计采用顶半部和底半部两部分实现:顶半部相当于中断响应函数;底半部相当于Windows中的延时过程调用;Linux的底半部可以使用多种方式实现,使用tasklet或者workqueue即可以实现操作。
普通的Linux中断函数为void Demo_interrupt(int irq, void * dev_id, struct pt_regs * regs),如需要实现底半部(bottom half)时,首先使用顶半部中断处理函数:
Irqreturn_t Demo_bh_interrupt (int irq, void * dev_id,struct pt_regs * regs) {
/* …… */
Tasklet_schedule(&Demo_tasklet); //调用Demo_do_tasklet
/* …… */
Return IRQ_HANDLED; }
底半部函数:void Demo_do_tasklet (unsigned long)。
在使用tasklet之前,首先需使用DECLARE_TASKLET(Demo_tasklet, Demo_do_tasklet, data)申明tasklet,但也可以使用struct work_queue Demo_wq申明work queue(工作队列);申明之后需要将后半部处理函数Demo_do_tasklet ( )放入工作队列中,可以使用下面的函数:INIT_WORK(&Demo_wq, Demo_do_tasklet, NULL)。工作队列的后半部函数与tasklet相同。
3 设计结果与实测性能分析
使用VHDL编写代码,利用逻辑分析仪对运行在实际硬件上的PCI桥代码进行分析,图5为逻辑分析仪上所截得时序图、PCI关键信号(包括被动模式和主动模式的)。

使用Altera的Quartus II 7.1对程序进行设计综合,PCI接口最低时钟频率为80MHz。综合生成网表文件,下载到FPGA,经过实际测试,系统运行正常,其桥模块占用4 913逻辑单元和557 056位的存储单元。用安捷伦1 681AD型逻辑分析仪分析测试PCI关键信号,其结果:系统每传输16KB数据的总时间为164.487μs,数据传输时间为130.975μs,系统开销为33.512μs,效率为79.5%。而与普通非链式DMA传输16KB数据的总时间比较,以32位66MHz频率的PCI系统为测试平台,可以得到如表2所示的结果。

从表2可以看出,本文所设计的DMA方法之所以效率会比传统的非链式DMA的方法要高,在于软件响应的时间大大缩短,当要传送的数据量越大时,DMA的平均数据率就会越高。
本文设计的系统平台已经成功地应用于MD5的解密。通过实际性能的测试,基于IP-core的64位接口设计完全达到了预期的性能目标,并且该平台可以满足大运算量、实时性要求高的数字信号处理算法的要求。下一阶段的工作,将在该平台上实现阵列信号处理的算法,以达到高速实时处理,减少资源耗费的目的。
参考文献
[1] Altera Corporation. PCI local bus specification revison 2.2. 1998.
[2] Altera Corporation. PCI megacore function user guide. 2003.
[3] Altera Corporation. PCI-MT64 megacore function reference design. 2003.
[4] CORBET J,RUBINI A,HARTMAN G K. Linux device driver 3rd. O′Reilly, 2005.
[5] 张浩,徐宁仪,周祖成.基于PCI Core的链式DMA控制器设计. 计算机应用, 2005,(3).