
基于DSP的实时MPEG-4编码的软件优化设计
2009-02-06
作者:焦 晓1 马明罡2 朱光喜
摘 要: 结合开发工具TMS320C6201EVM板的结构和特点,阐述了在实现MPEG-4实时视频编码中,对算法的软件优化所做的工作。
关键词: TMS320C6201 MPEG-4 优化 并行处理
TMS320C6201芯片是TI公司新推出的并行处理的数字信号处理器。它的最高处理能力高达1600MIPS,即16亿万次每秒定点运算,是目前市场上所有的DSP芯片中速度较快、处理能力较强的DSP处理器。其应用前景十分广泛。本文利用C6201开发工具EVM(模拟评估)板,用软件实现实时MPEG-4编码。详细探讨了MPEG-4视频编码中的关键模块,并针对TMS320C6000的特殊指令结构,对软件优化的特殊处理做了较深入的研究。
1 开发工具的介绍
笔者采用的评估工具是TI公司的C6XEVM[2]。它的结构如图1所示。

C6XEVM除核心DSP之外,还提供了如下工具:一个64K×32bit、133MHz的z同步脉冲静态随机存取存储器(SBSRAM);两个1M×32bit、100MHz的同步动态RAM(SDRAM);内含基于PCI或外部XDS510支持的JTAG仿真;支持采样速率为5.5kHz~48kHz的立体声16位音频边界码;1.8V/2.5V直流电和3.3V直流电单板转换电压调整器;模拟5V直流电压的单板线性电压调整器;3个LED指示器(电压,2个自定义指示)等。
SBSRAM映射到DSP的CE0存储空间,把它用于程序自举。通常SBSRAM都工作在133MHz。当采用全速接口时,CPU时钟就等于SBSRAM的时钟;当采用半速接口时,SBSRAM的速度是CPU时钟速度的一半。
EVM提供的两个1M×32bit的字存储区间的SDRAM,每一个存储空间包含两个512K×2banks×16位的器件。它们映射到DSP的CE2和CE3存储空间,每一个空间使用16Mbit的地址空间。 SDRAM通常是CPU时钟速度的一半。
EVM提供的异步存储连接器允许给子板附加一个存储区间或者存储映射区间。扩展存储的界面被映射到DSP的4M异步CE1存储空间的低3M空间。CE1中扩展空间的地址从0x100000~12FFFFF,在MAP0和MAP1方式下为0x1400000~16FFFFF,CE1的最上面的1M字节可分配给板上外围。CE1存储空间的这种分配方式容许了板上器件和扩展器件的共存。
2 MPEG-4视频编码
MPEG-4编码是基于VOP的编码[3]。所谓VOP是指视频目标平面,即视频对象VO在某一时间的存在。VOP编码器的结构框图如图2所示。
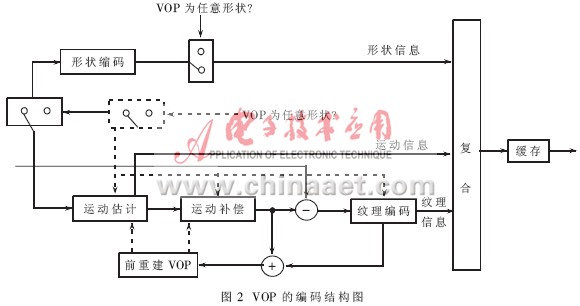
编码器主要由两部分组成:一是形状编码器;另一个是传统的运动估计和补偿及纹理VOP编码器。VOP可采用帧内编码(Intra-VOP,简称I-VOP)和帧间预测编码(Inter-VOP)。帧间预测编码又可以分为前向因果预测编码(P-VOP)和前后向非因果编码(B-VOP)。帧间预测编码消除了视频信息的时间冗余。对于VOP的编码,首先将各个VOP从上到下分成16×16大小的宏块(MB)。具体的形状、运动和纹理编码基于MB进行,所以一个MB的信息是形状、运动、纹理(Shape-Motion-Texture)的总和。进行MB编码时,再把它分成4个8×8块(Block)的亮度Y分量,和2个8×8块的色度Cr和Cb分量分别进行编码。然后对6个Block分别进行8×8DCT二维变换、量化和Huffman编码。
进行测试使用的图像是QCIF格式(176×144象素),图像数据从主机读入。通过CCS测得其各个模块所消耗的时间周期比率如下。
其各个部分占总运算量的比例分别为:

分析显示,运动估计和运动补偿模块及纹理编码模块是MPEG-4实现的最主要的瓶颈。所以在程序优化上所做的工作主要是基于这两个模块进行。
3 程序的优化考虑
要想充分发挥TMS320C6201的运算能力,必须从它的硬件结构出发,最大限度地利用八个功能单元,使用软件流水线,尽量让程序无冲突地并行执行。并行执行的优点在于,在处理彼此之间没有承接关系的运算时,在CPU资源允许的情况下可以并行完成。但对于前后有承接关系或者判断、跳转频繁的情况就无法发挥其优势。一般循环体都满足并行处理的条件,并且循环体往往是程序中耗时最长的。因此在进行优化时将重点放在循环体上。
3.1 跳转指令的优化
DSP的指令多为单周期指令,但是转移类指令却通常要耗费较多的时钟周期,每个跳转都有5个延迟间隙,从性能上考虑是一项很耗时的工作, 因此应尽可能地减少程序中的分支。
事实上,通过对程序的分析,可以看到许多判断转移用简单的条件组合就可以得到实现。例如下面的小程序:
if(rcoeff[i]>(lim-1)) rcoeff[i]=(lim-1);
else if(rcoeff[i]<(-lim)) rcoeff[i]=(-lim);
可以改为:rcoeff[i]=MIN(rcoeff[i],(lim-1));
rcoeff[i]=MAX(rcoeff[i],(-lim));
还有一种常用的减少判断转移的方法是将循环展开。特别是对多重循环的控制,若外层循环较少,可将内层循环直排,把转移条件结合起来,以减少层与层之间的相互联系。
3.2 使用库函数
TI公司对TMS320C62XX的用户提供了功能强大的IMAGE LIB[4]库支持。在这个库中,包含许多常用函数,可以完成DCT/IDCT变换、小波变换、DCT量化、自适应滤波等功能。这些函数都是优化过的,完全能够实现软件流水,效率很高。
3.3 改写线性汇编
线性汇编语言是TMS320C6000中独有的一种编程语言,介于高级语言和低级语言之间。为了提高代码的性能,可以用线性汇编来重写影响速度的关键代码段。线性汇编中不需要给出使用的寄存器、指令的延迟周期及使用的哪个功能单元等信息,C6201强大的汇编优化器会根据代码的情况自动确定这些信息[5]。然而很多时候,为了提高代码的效率,必须指出使用哪个功能单元。使用线性汇编时要注意:对循环体进行优化时不能使用跳转到循环体外的跳转指令;计数器使用减计数等。
进行优化时,首先要确定循环次数。对于循环次数是变量的情况,优化器不能并行优化;其次,要尽可能使用双字或字存取操作。例如运动估计和补偿中的一个小程序段:
void MC_case_a(uchar ref[NUM_ROWS][NUM_COLS],
uchar curr[NUM_ROWS][NUM_COLS], const int r_x, const int c_x,const int r_y, const int c_y, const int size)
{
int m, n;
for(m=0; m for(n=0; n curr[c_x+m][c_y+n] = ref[r_x+m][r_y+n]; }} } 相应的线性汇编程序如下: .def _MC_case_a .sect ″.text″ _MC_case_a: .cproc ref, curr, r_x, c_x, r_y, c_y, num_cols .reg r_temp1, r_temp2, c_temp1, c_temp2 .reg p_r, p_c, np_r .reg lshift, rshift, count .reg r_w1, r_w2, r_w3, r_w4 .reg temp SHL r_x, 0x05, r_temp1 SHL c_x, 0x05, c_temp1 ADD r_y, ref, r_temp2 ADD c_y, curr, c_temp2 ADD r_temp1, r_temp2, p_r ADD c_temp1, c_temp2, p_c SUB num_cols, 2, num_cols MVK 8, count ; 循环次数为8 MVK 0xFFFC, temp AND p_r, temp, np_r AND p_r, 0x0003, rshift SUB.L 0x04, rshift, lshift SHL rshift, 0x03, rshift SHL lshift, 0x03, lshift loop: .trip 8 LDW *np_r++[1], r_w1 LDW *np_r++[1], r_w2 LDW *np_r++[num_cols], r_w3 SHRU r_w1, rshift, r_w1 SHL r_w3, lshift, r_w3 SHL r_w2, lshift, r_w4 SHRU r_w2, rshift, r_w2 OR r_w1, r_w4, r_w1 OR r_w2, r_w3, r_w2 STW r_w1, *p_c++[1] STW r_w2, *p_c++[num_cols] ADD p_c, 4, p_c [count] SUB count, 1, count [count] B loop .endproc 优化前,在CCS(Code Composer Studio)上测得的C程序段消耗时钟周期为574;而优化后的线性汇编所耗时钟周期数为58,效率显著提高。 3.4 存储空间的考虑 DSP存储空间的配置十分重要。因为DSP对不同的存储单元的访问速度是有区别的,对片内寄存器的访问速度最快,对片内RAM的访问速度比片外RAM的访问速度快。因此合理地配置和使用存储空间,对系统整体效率影响很大。应该尽可能地把访问比较频繁的常数表和代码段装入片内RAM,如果过大,则把其中一部分装入片外存储器。 同时,还要考虑存储bank的冲突。由于C6201DSP使用交叉存储方案,将存储器分成4个或8个bank,每个bank都是单口存储区,因此每个周期只允许一次访问,在一个周期内对一个bank进行两次访问将产生存储器阻塞。存储器阻塞导致所有流水线操作停止一个周期,用来从存储器读取第2个数据。解决的办法是对代码段进行修改。 3.5 其他优化方法 除此之外,还有一些比较基本的方法,如: ·为了提高算法的实现效率,减少运算的实际开销,尽可能把需运行时计算的参数做成查找表或常数数值,从而将运行时的计算转化为编译时的计算。这不仅适用于一些比较规整的参数表,对于一些并不规整的运行时计算,特别是比较耗时的计算(如浮点除),也要尽可能使其表格化。 ·浮点数定点化,在编写MPEG-4的模拟算法时,为了方便,C语言中一般既有整型数,又有浮点数。由于使用的是定点芯片,所以有必要把所有的浮点运算改为定点运算。 ·使用字访问2个16位数据,将其分别放在32位寄存器的高16位和低16位字段。这样可以使程序读取数据的速率提高一倍,从而大大提高执行效率。 ·使用移位指令替代乘除操作,移位指令只有一个时钟周期,比之乘除运算则可以节约许多时钟周期。 最初的C代码在EVM板上执行,处理速率仅为0.8帧/秒。通过上述方法优化源程序后,可在C6201的EVM板上实现实时的MPEG-4编码,处理速度为30帧/秒。 DSP芯片的使用范围已越来越广。特别在移动通信领域中,软件无线电、智能天线等新技术的实现都需要强大的数字信号处理的支持。TMS320C6000系列能够满足这方面的需求。本文结合在其在MPEG-4编码中应用的实例,具体阐述了TMS320C6000的软件优化开发方法。工作中不可避免地存在某些不足,尚待进一步探讨。 参考文献 1 任丽香,马淑芬,李方慧.TMS320C6000系列DSPs的原理与应用[M].北京:电子工业出版社,2000 2 TI公司.TMS320C62x Multi-channel Evaluation Module User’s Guide[M].1999 3 Noordwijkerhout MPEG-4 Video Verification Model[S], Version16.0ISO/IEC TC1/SC29/WG11 N3312 March,2000 4 TI公司.TMS320C62x Image-Video Processing Library Programmer's Reference[M]. 2000 5 TI公司.On the Implementation of MPEG-4 Motion Compensation Using the TMS320C62x [M].1999