
摘 要: 提出了一种基于概念网络和主题概念树的文本分类算法。该算法可以根据关联度传播模型对未知文本中的一些概念进行一定程度上的语义复合。
关键词: 概念网络 主题概念树 文本分类
文本自动分类是指对用自然语言写成的文本按照一定的主题进行分类。随着信息技术的发展,特别是因特网的发展,使得大量的文本资料需要进行搜集和管理,从而使文本自动分类技术应运而生。文本自动分类技术在网上信息定位、档案管理、资料搜集等方面有着广泛的用途,研究自动文本分类算法具有重要的价值。由于传统的基于关键词的分类方法和基于统计的分类方法没有考虑文本语义和上下文方面的信息,因此有较大的局限性。近来,人们把语义信息用于文本分类,取得了较好的效果。本文试图用一种新的工具,即概念网络和主题概念树来解决文本分类的问题,它在一定程度上考虑了上下文对文本归类的影响。
1 概念网络和主题概念树
1.1 概念网络
概念网络是中国科学院自动化所综合信息系统研究中心在理论和实践的基础上对人工智能研究的一种探索,是面向多领域并以解决人工智能基础问题为目标所开发的知识表达框架体系。它从认知心理学的角度解释了思维活动的基础结构,提出了思维活动的心理模型假说。概念网络将概念作为意义的基本表达单元,依靠概念之间的各种关系形成意义主体相互作用的网络。从概念网络的构造方式来说,概念网络本身是一个知识表达框架体系。
概念网络理论使用属性、关系和行为三个元素组来表达概念的内涵。属性是描述概念自身的固有特性,包括属性类型、属性名称和属性值,用来刻画不同概念之间的区别;关系体现概念之间的联系,在关系的作用下,由简单概念组成复杂概念,由具体概念得到抽象概念。关系的内容包括关系的类型、关系的主体和关系的客体;行为的内容包括行为的名称、行为的类型、行为产生的前提条件和满足前提条件下的作用。行为的结果是改变特定语义环境下,概念网络中相关概念的状态。行为是将概念网络和其他语义网络区分开的标志,也是整个概念网络认知的源动力。
利用在概念网络理论框架下开发出的概念网络平台——概念网络管理中心(CMC),可以很方便地完成搭建领域知识概念网络的工作。概念网络平台提供了概念的管理、概念关系的管理、概念行为的建立、概念检索等与概念网络有关的处理。目前它已经将内核组件化,可以方便于其他系统调用。在概念网络平台上,可以装载某个专业领域,并定义领域中各个概念的属性、行为以及概念与其他概念之间的关系。
1.2 主题概念树
主题概念树是针对传统的主题词分析法或整词匹配法提出的。它以概念网络中的知识表达方法为基础,把与某个主题概念相关的概念组织成一棵树,称为主题概念树。它把原来分散的无关联的词汇在概念的层次上联系起来,从而解决了文本内容分析的语义基础。主题概念树中每一个叶节点都由一个概念或复合概念组成,由概念组成的叶节点如“雷达”、“细菌”等,而复合概念如“无线网络”、“纳米材料”等。这样,在一篇文章中,如果并不经常出现“纳米材料”这样的词汇,而是常常讨论纳米和材料方面的内容,则仍然会在“纳米材料”这样的节点上取得比较高的关联度。主题概念树的树杈有二种类型,它们代表了上位概念与下位概念之间的关系:一是父-子继承关系,二是属主-成员的隶属关系。由于这二类关系的性质不同,故它们的上位概念受下位概念的语义影响也不同。
以“计算机”为例,可以建立如图1所示的主题概念树。

从图1中可以看到,每一个叶节点都是一个概念(如:计算机,软件等)或复合概念(如应用软件,支撑软件等)。主题概念树是在概念网络的基础上,根据分类的主概念生成的。它的生成过程为:(1)建立某个领域的概念网络;(2)确定分类的主概念,与概念网络建立连接;(3)分别取主概念的m层成员概念节点、下位概念节点、语义场概念节点(现在主要考虑同义和近义概念),把它们存储到一张表中,这就是主题概念树。层数m是个经验值,考虑到概念网络的构造和文本分类的实际需要,一般层数m取为4。
2 分类算法
分类算法的核心是判断未知文本与主题类别在内容上的相关程度。本算法中,首先用概念网络对主题概念进行概念扩展,构建主题概念树。对未知文本先进行子模式化,再进行分词处理。根据关联度计算模型求每个概念节点的基础关联度。然后,根据“词义互相激励原则”计算句中、句间的概念激励,对前一步计算得到的关联度进行修正,得到最终的关联度,并以此为分类标准对未知文本进行识别。对未知文本关联度的计算可分为图2所示的几部分。
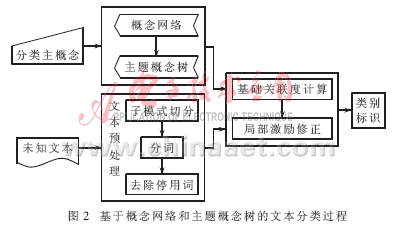
相关定义:(1)概念容量:文本经过词切分和去除停用词后的概念总数。(2)关联度:表示某个概念节点与未知文本之间的相关程度。(3)子模式:指未知文本中任意完整的标题或句子。(4)激励值:表示子模式对未知文本属于某个主题类别的贡献。
2.1 关联度计算
基于概念网络和主题概念树的文本分类算法的步骤是:首先对未知文本进行子模式化和分词,然后利用概念网络进行概念定位,作初步统计后根据关联度计算模型计算基础关联度、主题概念树上复合概念的关联度和关联度在语义树上的传播。
引入符号表示:未知文本Ti中包含Ni个概念和z个子模式,第j个子模式记为Sj。主题概念树中所有概念和复合概念组成集合D。Rk为主题概念树中第k个概念Ck的基础关联度,nk为Ck在Ti中出现的次数。用Rc表示复合概念的关联度,Rb表示复合概念的约束概念的关联度,Rl表示复合概念的核心概念的关联度。Ru表示上位概念的关联度,Rx表示下位概念的关联度,Rxi表示第i个下位概念的关联度。
(1)概念节点的基础关联度计算模型。在文本中,若某主题概念及其相关概念节点出现的次数越多,则文本与该概念的相关度就越大;当分类概念的呈现次数相同时,文本中的概念容量越大,则该概念节点与文本之间的相关度就越小。它们之间存在着线性关系,即关联度计算的基本公式:
![]()
未知文本在分词处理后,每个词与主题概念树中的概念节点之间可能存在三种关系:相等、相关或不相关。鉴于这三种不同的情况,在进行基础关联度计算时应作不同的处理。本算法采用的加权策略如表1所示。

以上述计算机的主题概念树为例,对概念节点“计算机”来说,如果在未知文本中出现“微型机”,则给“计算机”的呈现次数加0.8。而如果未知文本中出现“软件”这个概念,则将“计算机”的呈现次数加0.5。
(2)复合概念的关联度计算模型。复合概念的关联度Rc可由参加复合的子概念的基础关联度计算得到。以概念约束为例:

(3)主题概念树上语义关联度的传播。主题概念树上的语义关联度的传播模型主要考虑父-子继承关系的语义关联度传播与属主-成员的隶属关系的语义传播。父子继承关系语义计算模型来自于形式逻辑关于概念的定义:概念=属+种差,这里属就是上位概念,种差就是下位概念的属性。因此,继承型语义传播模型为:
![]()
其中:n是种差总数,通常,在复合概念中n=1。
例如,当以“支撑软件”为下位概念来计算上位概念“软件”的关联度时,如果“支撑软件”与未知文本之间的关联度为0.03,则可得到“软件”与未知文本之间的关联度为0.015。
2.2 局部激励修正
上述的基础关联度计算模型中没有考虑上下文的因素。事实上,在自然语言中,词作为概念的载体,如果在某个词邻近的上下文中经常出现某个类别的词,则该词属于该类别的可能性也就越大。例如,在一个包含“计算机”、“软件”、“磁盘”等词汇的子模式中,“病毒”代表生物学上病毒含义的概率很小,而在包含“基因”、“生物”、“细菌”等词汇的子模式中,“病毒”代表生物学上病毒含义的概率就比较大。也就是说,在小范围内存在着词义的互相激励,在这里称之为“局部激励”。
下面用局部激励的原则对基础关联度进行修正。将未知文本中的每个子模式对该文本属于某个类别所作的贡献,称为子模式的激励值,第j个子模式Sj的激励值记为u(Sj)。
子模式的激励值与下面二个因素有关:①子模式中与主题概念树上的概念节点相匹配的词的个数,记为w(Sj);②每个匹配成功的概念节点在该子模式中的次数,记为qk(k=1,2,……w(Sj))。
综合上面的二个因素,子模式激励值可表示为:

其中:z为子模式的个数,?姿为可以调整的常系数。式(6)即为最后得到的未知文本与概念节点之间的关联度。用它可进行复合概念的关联度计算,并可通过语义关联度传播模型计算关联度在主题概念树上的传播。最后可得到未知文本与主题概念树各概念节点之间的关联度。
可以看出,在同一篇文本中,通过公式(6)的修正,每个概念节点的基础关联度得到了相同倍数的增强。所以,它并不会影响基础关联度的大小顺序,与原基础关联度存在着一致性。同时,不同的文本,如果信息容量和主题概念树上的每个概念节点的呈现次数相同,而同类概念在文本中出现的上下文位置不同时,由局部激励原则进行的修正能使同类概念聚集度高的文本呈现出更高的基础关联度,即修正后的基础并联度能够反映同类词义互相激励的效果。
2.3 按关联度进行分层次识别
按前述关联度计算模型得到的关联度进行排序。在计算过程中,对每一个未知文本,得到了主题概念树上的每个概念节点与未知文本的关联度。这样,对于M个未知文本来说,它们关于概念节点Ck(主题概念树上的第k个概念节点)的关联度的大小可以进行比较。按关联度大小将它们进行排序,就得到未知文本关于某个概念节点的关联度排名。以此作为识别的标识,按一定的关联度阈值进行提交。
同时,由于在算法中下位概念的呈现对上位概念有贡献,所以与下层概念节点关联度较高的文本,与上层概念也有比较高的关联度。如:“微型机”和“计算机软件”方面的文本将都属于“计算机”类别,但属于计算机类别的文本却不一定属于微型机或者计算机软件类别。对每个层次的概念节点与未知文本的关联度大小进行排序,在同属某个大类的情况下,可得到未知文本属于某个小类的关联度排名。
3 结束语
本文提出了一种利用概念网络进行语义扩展的自动文本分类算法。提出了主题概念树的概念,对每个主题,利用主题概念树作为分类的基础。文中给出了基础关联度的计算模型以及对之进行修正的方法。初步的实验结果表明,这种分类方法能够有效地提高与主题概念相关度较高的文本的关联度系数。同时,对于仅有少量关键词出现,却与主概念相关度不高的文本,能够降低其关联度系数。
参考文献
1 Maria N.Theme-based Retrieval of Web News.http://xldb.fc.ul.pt/data/Publications_attach/po25.pdf,2000
2 Rosso P.Text Categorization and Information Retrieval Using WordNet Senses.http://www.fi.muni.cz/gwc2004/proc/110.pdf,2003
3 李莼.基于语义相关和概念相关的自动分类方法研究.计算机工程与应用,2003;(12)
4 高一波.一种基于概念的知识表达体系.计算机信息学报,2004;21(9)
5 解冲锋,李星.基于序列的文本分类算法.软件学报,2002;13(4)
6 庞剑锋,卜东波,白硕.基于向量空间模型的文本自动分类系统的研究与实现.计算机应用研究,2001;18(9)