
文献标识码: A
文章编号: 0258-7998(2013)05-0038-03
在图形处理应用中,图形图像数据的存取带宽直接决定着整个图形处理器的性能[1],因此,对图形图像数据的存取管理非常重要。参考文献[2-3]对目前NVIDIA提出的统一计算设备架构CUDA(Compute Unified Device Architecture)[4]中的存储层次结构做了介绍,但仅局限于从应用层次上进行描述,并未对具体的图形数据存取进行研究。参考文献[5-6]对Neon图形加速器进行了详细的剖析,并从存储架构层次的角度介绍了Neon图形加速器的存储管理系统。Neon图形加速器采用统一存储系统模型,将所有图形数据(如颜色、纹理图像以及显示数据等)进行统一管理。然而,Neon图形加速器不提供对2维图形图像以及3维引擎中的缓冲区对象、显示列表、顶点染色程序的支持。
并构多核图形处理器HMGPU(Heterogeneous Multi-core Graphic Processor Unit)是由西安邮电大学GPU团队自主设计研发的异构多核图形处理器。通过对HMGPU的并行渲染架构以及存储数据进行分析,在参考文献[5-6]的基础上,本文设计并实现了HMGPU存储管理系统,将显示存储区与其他图形存储区划分成两个存储区,分别予以管理。同时,根据不同的图形数据类型,分别进行存储控制,为HMGPU提供了2 021.2 MB/s的存储访问速率。最后采用System Verilog进行行为模型建模,并验证了其功能正确性。
1 HMGPU存储管理系统总体分析
针对HMGPU图形绘制任务并行实时处理的特点,兼顾效率与灵活性的具体需求,HMGPU存储系统采用共享存储模型实现对顶点数组、显示列表、纹理贴图、用户加载程序/数据、2D图形图像等相关图形数据的管理。其中显示列表和顶点数组的数据一般不具有纹理贴图、用户加载程序以及2D图形图像数据的大片连续性。为了充分利用存储空间,本存储管理系统采用固定分区和分页式分区两种方式进行存储管理;并利用片上存储高性能的特性,将所有的管理控制信息存储于片上存储,用硬件管理方式实现存储管理系统,减少了图形图像数据的存取延迟,满足HMGPU峰值为289.98 Mpixel/s像素填充率的性能要求。
2 HMGPU存储管理系统设计
2.1 HMGPU存储管理顶层设计
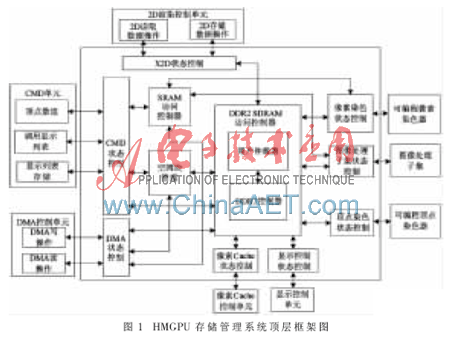
HMGPU存储系统采用共享存储结构,存储空间主要划分成独立的染色程序区、2D图形/图像区、3D纹理贴图区、用户区4大块。在图形渲染过程中,渲染管线各部件以并发的方式访问共享存储。因此为了各个部件正确访问存储,对存储内部的读写操作采用互斥的方式来实现。同时,为了保证存储管理对各渲染部件的实时响应,为每一个存储访问部件设定独立的控制单元,当满足突发传输条件时,向存储管理仲裁部件发送访问请求,由仲裁器仲裁,将存储访问权授予本次存储访问优先级最高的渲染部件。HMGPU存储管理系统的顶层框架设计如图1所示。
2.2 用户区空闲块的管理
在HMGPU中,对用户区存储空间的管理采用分页式管理机制实现,整个存储空间以页为单位进行分配和回收,每一存储页表示一个存储块。空闲区域由1 KB的空闲页组成,并采用链表的方式进行连接,对空闲区域的管理实质上就是对空闲链表进行管理。空闲区域链表具体结构如图2所示。对存储空间的分配操作是:假设需要分配N页存储空间,按照链表的遍历方式,从空闲链表表头分配N页存储空间实现空间分配。类似的,对于空间回收,则将需要回收的空间链接至空闲链表的表尾从而实现空间回收。

2.3 分页式数据对象管理
由于缓冲区对象与显示列表数据的大小不定,在本存储管理设计中采用分页式存储空间进行数据管理。
对于缓冲区对象以及显示列表的管理,在片上SRAM中设定固定的8个块用以存储缓冲区对象的索引信息,设定256个块用以存储显示列表索引信息。对于缓冲区对象以及显示列表的存储,则首先从空闲区获取存储空间,并将数据存储至分配的链表中,将分配的存储首地址、尾地址、数据大小以及对应的参数信息根据标识号存储至对应的索引块片上SRAM中。当对缓冲区对象或显示列表进行调用时,首先根据标识号从对应的索引块中获取存储首地址、数据大小等参数信息,并根据偏移地址按照链表的遍历方式从指定的地址开始返回被调用的数据信息,以此完成缓冲区对象与显示列表的管理。
2.4 纹理对象与2D图形图像索引块管理
纹理作为绘制更逼近真实场景的渲染数据信息之一,具有大片、连续等特征,其存储空间一般都要求具有连续性。在HMGPU中,纹理采用固定分区形式进行连续存储,纹理空间最多支持6幅纹理图像,每一幅纹理共提供12层mipmap映射。对于每一幅纹理,在SRAM中均设有独立且固定的索引块。当接收到纹理创建请求时,首先根据纹理名字以及mipmap层次从片上SRAM中获取该纹理数据的物理存储地址,并将纹理数据存储于指定的存储空间,最后将对应参数信息存储于SRAM中以备后续访问纹理使用。当需要进行纹理访问时,类似于纹理的创建过程,首先从片上SRAM中获取该纹理对应的mipmap层的存储首地址,并将其与偏移地址相加,获取实际需要读取的纹理数据,最后返回给用户端即完成纹理的访问。
2D引擎中所需存储于DDR2 SDRAM中的图像包括源图像、目标图像、掩码图像、2D图形等4类图像。对于2D图形图像存储与读取,则根据2D引擎所发送的图形图像索引信息进行对应的物理地址映射,并进行数据的存储或者读取。
2.5 顶点染色器与像素染色器染色程序索引块
在HMGPU系统中,顶点染色器VS(Vertex Shader)以及像素染色器PS(Pixel Shader)均是可编程的。为了节省片上存储空间,依据Cache与主存之间的存储层次性原理,将大小固定的VS与PS染色程序存储于DDR2中,备后续固定程序加载使用。以VS程序加载为例,在存储中预定两块固定存储空间,并按照乒乓方式进行染色程序的存储与读取,即每次存储与读取加载程序的存储块都是交替进行的,灵活而高效地实现染色程序的加载。
3 设计验证和综合
对所完成的HMGPU存储管理系统的硬件电路进行具体设计,在Synopsys公司的VCS环境下进行了充分的功能仿真,并在DC环境下进行逻辑综合,电路工作频率达到167 MHz。同时,采用System Verilog语言,使用总线功能模型验证方法构建层次化的验证环境,搭建自动化的验证平台,通过固定测试和随机测试对各功能点进行测试。测试平台如图3所示。

测试平台由输入单元、输出单元以及输出响应构成,其中输入单元采用总线功能模型验证的方法产生不同的测试激励,按照接口时序的要求将测试命令送到参考模型和待测试设计DUV(Design Under Verification)中;输出单元比较参考模型输出信号和DUV输出信号,若结果不一致则打印错误报告同时结束仿真。
本文根据HMGPU的具体应用需求,将存储区划分成显示存储区与其他图形图像数据区两部分。对于每一类数据,分别设定独立控制模块完成对该类数据的管理,并提供存储系统的并发访问,有效地实现了异构多核图形处理器的存储管理系统。
整个系统采用Verilog语言实现其电路设计,并对电路进行了功能验证与DC综合以及FPGA验证。结果表明,HMGPU存储管理系统电路工作正常,且硬件电路具有良好的扩展性,实用性强,能够满足HMGPU存储带宽需求。本设计已经应用于自主研发的HMGPU中,协同其他部件完成图形的渲染。
参考文献
[1] COPE B,PETER Y K,LUK W.Using reconfigurable logic to optimise GPU memory accesses[C].Design,Automation and Test in Europe,DATE′08.Munich,2008:44-49.
[2] 马安国,成玉,唐遇星,等.GPU异构系统中的存储层次和负载均衡策略研究[J].国防科技大学学报,2009,31(5):38-43.
[3] HENRY W,MISELMYRTO P,MARYAM S A,et al.Demystifying GPU microarchitecture through microbenchmarking[C]. Performance Analysis of Systems & Software,IEEE International Symposium on Computing & Processing(Hardware/Software),White Plains,NY,March 2010:235-246.
[4] NVIDIA Corporation.NVIDIA CUDA compute unified device architecture reference manual[EB/OL].(2008-06-xx)[2013-01-15].http://www.cs.ucla.edu/~palsberg/course/cs239/papers/CudaReferenceManual_2.0.pdf.1-247.
[5] MCCORMACK J,MCNAMARA R,GIANOS C,et al.Implementing neon:a 256-bit graphics accelerator[J].Micro IEEE,1999,19(2):58-69.
[6] MCCORMACK J,MCNAMARA R,GIANOS C,et al.Neon: A single-chip 3D workstation graphics accelerator,research report 98/1[C].HWWS′98 Proceedings of the ACM SIGGRAPH/EUROGRAPHICS Workshop on Graphics Hardware. ACM,New York,NY,USA,1998:123-132.