
文献标识码: A
文章编号: 0258-7998(2014)01-0016-04
FPGA作为未来数字电路系统的三大基石之一,是目前硬件设计方法的研究热点。与传统的电路设计方法相比,FPGA具有功能强、周期短、投资小、开发工具智能化等特点。随着电子工艺的不断改进,新一代的FPGA甚至集成了CPU和DSP内核,在一片FPGA上进行软硬件协同设计,为实现片上可编程系统(SoPC)提供了强大的硬件支持,这使得FPGA成为许多高性能应用的最佳选择。FPGA产品的应用领域已经从相对较窄的通信基础设备领域迅速扩张到消费电子、汽车电子、工业控制、测试测量等领域。
一般来讲,要在FPGA设计中实现较高的性能,除了要求设计者精通HDL语言,还需熟知FPGA的内部结构,具备足够的数字电路知识。这种方法直接面向硬件,抽象层次较低,抬高了FPGA开发的准入门槛,还严重降低了FPGA的开发效率。
OpenCL作为跨平台的开发语言,为上述问题提供了一套可选择的解决方案。OpenCL在传统的C语言基础上进行了扩展,具备较高的抽象层次和可移植性,开发者即使不了解硬件电路和设备的底层细节,也可以开发出高性能的FPGA应用程序。这种开发方法可以减少硬件开发时间,把更多的时间用于算法优化,提高FPGA的开发效率。
目前,绝大部分OpenCL开发都是基于CPU和GPU。由于FPGA与GPU/CPU结构上的差异,OpenCL在GPU/CPU上的开发方法并不完全适用于FPGA,FPGA的OpenCL设计方法学尚存在较大的改进空间。针对以上问题,本文以矩阵乘法和QR分解为例,根据FPGA的特点制定并实现了多种优化方案,分析了各种优化方案的优缺点及适用情况,为后续FPGA的OpenCL开发提供参考。
1 相关工作
自2008年苹果开发者大会(WWDC)提出OpenCL以来,已有不少的机构和学者进行OpenCL的开发研究,并取得了显著的成果,目前大部分的OpenCL研究都是基于GPU平台。参考文献[1]就矩阵乘法分别在多核CPU、AMD GPU、NVIDIA GPU上进行了实现和优化,并对比了各平台的性能。
2013年,Altera和Xilinx两大FPGA主流厂商相继推出了针对FPGA的OpenCL开发套件,但目前相关研究成果较少,只能在IEEE平台上搜索到寥寥几篇论文。参考文献[2-4]中介绍了在FPGA上进行OpenCL开发的原理及相关工具。参考文献[5]使用OpenCL在Altera的FPGA上实现了一个文档筛选算法,与CPU、GPU相比分别取得了5.5、5.25的加速比,但没有针对FPGA做深入的优化工作,也未详细分析如何提升FPGA运算性能。参考文献[6]分别在CPU、GPU和FPGA 3个平台上实现了不规则图像和视频的压缩算法,FPGA平台与多核CPU、GPU相比分别达到了3、114的加速比。作者只是简单地将GPU上的应用移植到了FPGA上,而未做进一步的优化。参考文献[7]对多核CPU、GPU、FPGA平台在性能、设计理论、平台体系结构等方面进行了对比,分别用CUDA、OpenCL、VHDL 3种开发语言在多种平台下实现了Quantum Monte Carto程序。通过对比发现,OpenCL可以很方便地在多核CPU、GPU和FPGA之间进行移植。
目前介绍在FPGA上进行OpenCL开发的相关文献还非常稀少,大多数文献都只是针对FPGA的OpenCL开发进行理论介绍,即使有少数几篇进行了实际应用开发,也仅仅停留在实现阶段,并没有针对FPGA的硬件结构详细分析其OpenCL优化方法,这正是本文的研究重点。
2 算法研究
目前基于FPGA的OpenCL开发都是移植了GPU上的应用,例如图像处理、视频压缩/解压缩等。然而通信、雷达、汽车电子、工业控制才是FPGA的传统领域,尤其在通信领域中FPGA应用更为广泛。但当前还没有相关文献把OpenCL开发方法用于通信领域。
矩阵运算是通信领域中的基础运算,尤其是矩阵乘法和QR分解,是工程应用中最常见的矩阵运算,在信号检测与估计、数字信号处理等领域中应用广泛。因此,本文以矩阵乘法和QR分解为例,对FPGA的OpenCL实现及优化进行相关研究。



initial Q=E, R=A
barrier
for(int j=0; j<=Width-2; j++)
{
initial H
barrier
calculate the
generate H
barrier
compute Q = Q *
barrier
compute R = H * R
barrier
}
由于Householder变换法的特性,本文只将部分优化手段应用于QR分解。主要探索item复制和向量化两种方法的性能。本例中的QR分解内部具有较多的数据同步点,且item之间的数据依赖性非常强,即逻辑控制较多,因而向量化和item复制并不是QR分解的理想优化手段。
4 结果分析
测试数据采用随机函数生成,并将FPGA的运算结果与C函数的运算结果相比较,判断结果是否正确。本文采用多种优化方法实现矩阵乘法,实验结果如表1所示。

对于数据存取优化(如表1所示),通过设置合适的workgroup大小,减少item重复存取数据的次数,即可有效地提高性能。
对于循环展开优化,运行时间与循环展开次数是呈反比的。循环展开实质就是采用空间换取时间,展开次数越多,逻辑面积越大,执行时间则越短。
对于向量化1、2、4、8次,可以看出其运行时间基本是与向量化次数呈反比的。向量化复制了kernel的运算单元,使得item可以同时存取并处理多个数据,提高了kernel性能。然而,向量化16次的性能更差,这主要是受到了硬件资源限制。DDR带宽和FPGA逻辑资源都已超出DE4的最高峰值,造成了性能的急剧下降。
随着item复制次数的增加,性能有所提高,这也是使用空间换取时间的方法。但是其性能并不像向量化那样呈线性增长,这是因为item复制是将整个kernel功能单元进行复制,除了需要较多的逻辑资源外,全局带宽的需求也成倍增长,导致全局带宽超过DDR的最大带宽,使得性能增长曲线是非线性的。
组合优化同时使用向量化和item复制,可最大限度地发挥这两种方法的优点,实现性能提升,但效果还不够显著,这也是受到了DDR带宽的限制。
矩阵乘法是典型的大数据运算,有着大量的数据存取操作,内部控制逻辑较少,这类运算需要较大的全局带宽和较强的浮点运算能力。从表1中可以看到性能提升的瓶颈在于全局带宽,如何解决这一问题是优化的重点。可以使用以下两种方法降低kernel所需的全局带宽:(1)进行数据存取优化,减少kernel的重复存取操作,减少单个item实际使用的带宽;(2)向量化,提高全局带宽的有效利用率。从表1中也可以看出,这两种方法确实取得了非常好的效果。另外,还可以通过提升硬件的全局带宽来满足kernel对带宽的需求。
在QR分解中,主要采用了向量化和item复制两种方法,如表2所示。
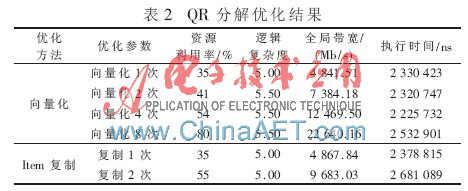
由表2可见,不管是向量化还是item复制,性能均没有得到有效的提升,甚至有一定的恶化,其中item复制带来的性能恶化更严重,这主要是因为QR分解的逻辑复杂度较大。在QR分解中,数据量并不大,所需的全局带宽较小,除了向量化8次外,其余的优化所需的全局带宽均没有超过DE4的限制。但是其中的运算过程较为复杂,可以看到其逻辑复杂度为5.5左右,限制了kernel性能的提高。
对于此类逻辑复杂度较大的应用,上述几种优化手段均不能得到非常好的效果。此时应以算法优化为主,以降低kernel内部的逻辑复杂度。
本文以矩阵乘法和QR分解为例,在FPGA上分别进行了实现和优化,比较分析了各种优化方法的优缺点及适用范围。目前,FPGA的OpenCL开发刚刚兴起,还有诸多不足,从实验中也可以看出,许多优化方法都受到了FPGA结构、算法并行性等多方面的限制,还需要从设计方法、FPGA结构优化、算法优化等多个方面进一步探讨如何更合理地运用OpenCL开发FPGA。这有赖于FPGA厂商进一步完善工具和开发流程,也有赖于广大科研工作者、应用工程师的配合和努力。
参考文献
[1] SEO S,JO G,LEE J.Performance tuning of matrix multiplication in OpenCL on different GPUs and CPUs[C].High Performance Computing,Networking,Storage and Analysis,2012:396-405.
[2] CZAJKOWSKI T S.Form OpenCL to high-performance hardware on FPGAs[C].Field Programmable Logic and Applications(FPL),2012 22nd International Conference,2012:531-534.
[3] Ma Sen,Huang Miaoqing,ANDREWS D.Developing application-specific multiprocessor platforms on FPGAs[C].Reconfigurable Computing and FPGAs(ReConFig),2012 International Conference,2012:1-6.
[4] ECONOMAKOS G.ESL as a Gateway from OpenCL to FPGAs:basic ideas and methodology evaluation[C]. Informatics(PCI),2012 16th Panhellenic Conference,2012:80-85.
[5] CHEN D,SINGH D.Invited paper:using OpenCL to evaluate the efficiency of CPUS, GPUS and FPGAS for information filtering[C].Field Programmable Logic and Applications(FPL),2012 22nd International Conference,2012:5-12.
[6] CHEN D,SINGH D.Fractal video compression in OpenCL:an evaluation of CPUs,GPUs,and FPGAs as acceleration platforms[C].Design Automation Conference(ASP-DAC),2013 18th Asia and South Pacific,2013:297-304.
[7] WEBER R.Comparing hardware accelerators in scientific applications:a case study[J].Parallel and Distributed Systems,IEEE Transactions,2011,22(1):58-68.
[8] 张贤达.矩阵分析与应用[M].北京:清华大学出版社,2004.
[9] 李刚强,田斌,易克初.FPGA设计中关键问题的研究[J].电子技术应用,2003,29(6):68-71.
[10] 张国礼,王建业,肖宇.浮点矩阵相乘IP核并行改进的设计与实现[J].电子技术应用,2012,38(2):43-46.