
基于TMS320C6713的人脸识别系统设计
南京航空航天大学 姜钰 丁万山
摘要: 为了人脸识别的相关算法能快速运行,选择了TI公司的DSP处理器,另附加键盘模块和PAL制式输出模块,可以脱离PC独立对PAL视频信号进行采集和处理,并独立运行人脸的定位,特征抽取以及人脸的识别。硬件方面,系统采用了存储器切换系统,使得图像数据缓存和读取分别由CPLD和DSP独立且同时执行,缩短了数据的处理周期,保证了系统的实时运行。软件设计包括了:人脸定位、人眼定位、样本存储以及人脸识别。其中样本由DSP自动选取,根据人眼定位和人脸标记方框的大小共同决定,选取一部分大小相等且眼距相同的图片作为训练样本以及待识别样本。在主分量分析过程中,提取出主分量构成特征脸空间,将原样本投影到该空间内一点,再输送到KNN分类器中进行分类。该设备携带方便,功耗低并可通过软件设计将其应用到其他领域,如运动识别、动态跟踪等。
Abstract:
Key words :
为了人脸识别的相关算法能快速运行,选择了TI公司的DSP处理器,另附加键盘模块和PAL制式输出模块,可以脱离PC独立对PAL视频信号进行采集和处理,并独立运行人脸的定位,特征抽取以及人脸的识别。硬件方面,系统采用了存储器切换系统,使得图像数据缓存和读取分别由CPLD和DSP独立且同时执行,缩短了数据的处理周期,保证了系统的实时运行。软件设计包括了:人脸定位、人眼定位、样本存储以及人脸识别。其中样本由DSP自动选取,根据人眼定位和人脸标记方框的大小共同决定,选取一部分大小相等且眼距相同的图片作为训练样本以及待识别样本。在主分量分析过程中,提取出主分量构成特征脸空间,将原样本投影到该空间内一点,再输送到KNN分类器中进行分类。该设备携带方便,功耗低并可通过软件设计将其应用到其他领域,如运动识别、动态跟踪等。
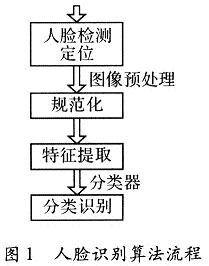
1 人脸检测的算法
人脸检测系统可以分为人脸检测和人脸识别模块,这两大模块又进一步可划分为人脸检测与定位、规范化、特征提取和人脸识别4个模块。其详细结构,如图1所示。
1.1 人脸的定位
通过已获得的样本来判断人脸的位置,选取合适的人脸,截取出做样本是重要的步骤。人脸特征定位与特征提取质量的好坏对于人脸图像识别效果有直接的影响。首先确定人眼的坐标(x1,y1)和(x2,y2),由此可间接得到正方形人脸的左上顶点和右下顶点的坐标,设其分别为(X1,Y1)和(X2,Y2),其详细计算方法如下所示
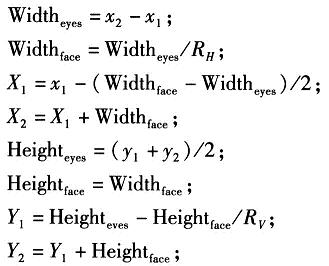
式中,RH和RV均为经验常数,在设计过程中将其分别取值为2.0和3.5。如此可在原图中得到人脸的区域座标,其尺寸随眼距Widtheyes的大小而变化,但是作为PCA的输入,要求输入样本的维数相同,所以必须对图片进行归一化处理。在设计中将所得人脸区域样本均缩放至24×24。此外还需要对图片进行对比度调节和直方图均衡等操作,以提高识别的准确性。
1.2 人脸特征提取
在设计人脸识别分类器时,通常将一幅图片看成一个一维向量。虽然这与传统的将图片看成矩阵形式有差别,但是却能为采用主分量分析(PCA)进行特征脸提取创造有利条件。
特征脸分类的方法是将一幅图像投影到一个特定“脸空间”的一个点。这个“脸空间”由一股互相正交的向量组成。这些向量便是表征各个人脸聚类的重要组成部分。不同人脸的图片在此空间的相差较远,相同人脸的不同图片在此空间上的投影相距较近。因此可以使用PCA的方法为整个人脸识别系统打下基础。
第一步,采集到N个样本用作训练集X,求出样本平均值m,如式(1)所示

其中,xi∈样本训练集X=(x1,x2,…,xN)。
第二步,求出散布矩阵S,如式(2)所示
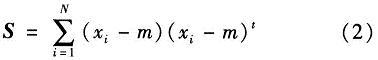
根据PCA的基本原理,必须求出散布矩阵的特征值λi和对应的特征向量ei。其中,ei便是主分量,且其对应的特征值的大小代表它包含信息的多少。所以需要将特征值从大到小依次排列λ1,λ2,…。如图2所示,左边是由λ1对应的特征向量重建的人脸图像,基本能分辨出人脸的轮廓,右边是由λ100对应的特征向量重建的图像,看起来更像是噪声,如果将其应用到系统中,对识别是不利的。

假设取出p个值,λ1,λ2,…,λp可以确定出脸空间E=(e1,e2,…,eP),在此脸空间上,训练样本X中,每个元素投影到该空间的点可以由式(3)得到
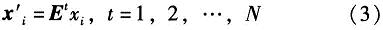
由上式得到的是将原向量经过PCA降维后的p维向量,下一步便是将其输入KNN分类器进行分类。
1.3 KNN分类器的构建
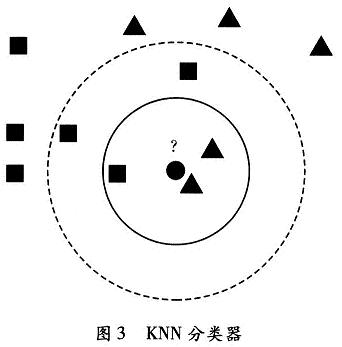
KNN的实现分训练和识别两步。训练时,把每类样本降维后的结果作为KNN的输入。K近邻算法将一个测试点x分类为与它最接近的K个近邻中出现最多的那个类别,从测试样本点开始生长,不断扩大区域,直到包含进K个训练样本点为止,并且把测试样本点的类别归为这最近K个训练样本点中出现频率最大的类别。如图3所示,圆圈表示待识别数据所处的位置,选择K值为3时,选中实线圆中的3个数据,识别结果为三角形代表的类;选择K值为5时,选中虚线圆中的5个数据,识别结果为正方形代表的类。所以选取恰当的K值对分类的结果有很大影响。如果K值选取过大时,可能能较正确地分类,但是同时牺牲了性能,提高了计算复杂度。如果K值选取过小,则大大降低了计算复杂度,但是可能会影响分类的准确性。
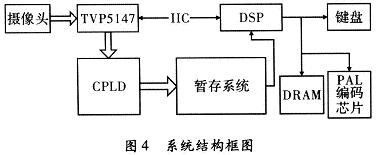
2 系统硬件设计
系统设计时选用TMS320C6713,这是TI公司生产的C6000系列的浮点处理器,其采用了VLIW体系结构,指令运行的等效周期数较低,运行速度较快。图像的采集采用了PAL制式输出的普通摄像头加上TI公司生产的图像编码芯片TVP5147,该芯片支持多种制式,多种接口输入,并可以输出YUV格式的视频数据,同时提供行同步信号和垂直同步信号等。数据暂存使用CPLD和SRAM实现。设计系统构成,如图4所示。
2.1 TVP5147芯片
系统上电时,TMS320C6713首先对TVP5147初始化,其通过I2C总线实现,DSP自带I2C总线控制器。芯片I2C地址是由芯片引脚I2CA的电平控制的,如该引脚接高电平,则I2C写地址为0xB8,否则为OxBB。
假如系统初始化为从Y[9..O]端口输出10位的YUV混合视频数据,则可知道其输出符合以下时序,如图5所示。
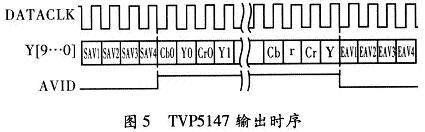
图中第一行为DATACLK信号,其为TVP5147芯片提供的数据时钟信号,第二行为数据Y[9…0],当每一行图像开始之前,会有4个SAV信号,同样,结束之后也有4个EAV信号,如图5所示,数据是YCbCr格式,每个像素点的数据为4个数据组成,一次为Cb,Y,Cr,Y。而由图5中可以看出AVID信号为高电平时,表明当前的数据为有效数据。这为CPLD采集有效数据提供了参考信号。同时TVP5147芯片还输出FID信号,该信号为奇偶场指示信号。
2.2 CPLD读写SRAM
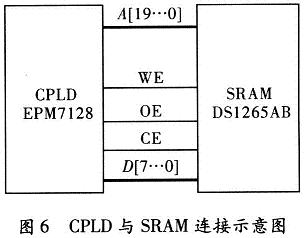
存储器选择了DS1265AB,它是SRAM存储器,具有存储速度快的优点,并能够在系统掉电时保存数据10年。DS1265具有1 MB的容量,20根地址线,8根数据线,另有WE,OE,CE信号输入端。
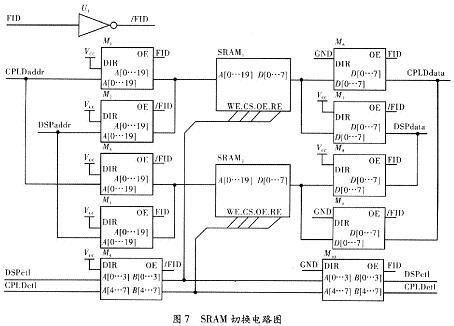
CPLD选用EPM7128具有价格便宜、计数频率高等优点。将存储器SRAM接到CPLD的IO引脚上,配合时序便能达到对SRAM读写的要求,原理图,如图6所示。
编写CPLD程序使得输出时序满足SRAM的存储要求,当然对于设计的具体要求,利用两片SRAM分别存储奇偶场的数据,SRAM的切换是由奇偶场信号FID控制多片74HC245实现的,详细过程,如图7所示。当FID处于高电平时,此时M1和M4使能,此时CPLD将地址信号CPLDaddr输入SRAM1中,DSP将地址信号DSPaddr输入至SRAM2中,同时M6和M8使能,由图中可以看出,此时CPLD正向SRAM1写入数据,而DSP正从SRAM2中读取数据,同时M10使能,CPLD的信号CPLDctl控制SRAM1的读写,而DSP的信号DSPctl控制SRAM2的读写,当FID转为低电平时,正好将SRAM1和SRAM2实现了交换。以这种方式构建的系统,能同时将视频的两场数据同时记录下来,实现了CPLD和DSP的有机结合。至此CPLD的任务就是将有效的图像数据存储到对应的SRAM中,当TVP5147芯片AVID引脚上升沿时,置地址为初始值00h,即从首地址依次往后写入。每一个数据时钟信号DATACLK上升沿时将TVP5147输出的Y[9…2]存储到当前地址单元,Y0和Y1位舍弃,因为所选择的SRAM数据位为8位,当放弃Y0和Y1位后,降低了图像数据的精度,但对识别效果的影响却很小,然后随着DATACLK每次上升沿的来临,CPLD将地址单元加1,这样实现每一场数据的写入。当切换至另一场数据时,执行的过程相同,只是存储的对象被74HC245强制更改,如此循环,便可将每场数据记录下来。
2.3 图像输出系统的设计
系统设计时为了减轻负担,采用电视监控的方法,将小型电视机通过TI公司的视频编码芯片THS8135连接至DSP总线,将得到的YUV数据通过THS8135直接输出至电视AV的视频接收端,并且通过DSP可以将一些信息显示到电视屏幕上,这样使得识别的过程更加人性化。
3 系统软件设计
系统硬件调试成功后,需要提供一定的软件算法等,以实现软件和硬件的结合,在此设计中,SRAM是扩展在DSP处理器EMIF上的,DSP处理器通过读信号的触发将有效奇偶场数据分别存储为两个一维数组,以供处理。
3.1 DSP的图像预处理
TVP5147芯片输出的图像数据并非RGB格式,而是以YUV格式输出的。需要通过DSP处理器转换成RGB格式,才能进行图像的预处理,转换公式如式(4)所示
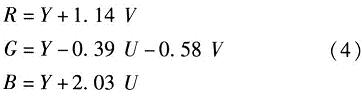
DSP将图像数据读入内存空间,然后对其进行运算,将得到的RGB分别放到对应的存储单元,并算出灰度值Gray,运算公式如式(5)所示
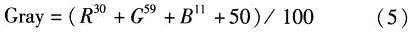
将最后得到的灰度值存放到对应的数组当中。每张图片由两场图片构成,所以完整的图片分辨率为720×576。但是对于系统本身无需对其每一个像素都进行转换,所以截取其中320×240进行存储,这样每场的分辨率为320×120,大大降低了由YUV到灰度图像预处理和脸部定位的时间,提高了系统的性能。
3.2 人脸判别流程
将得到的320×240的图片经过人脸的检测后,将截取人脸的部分作为人脸样本。设计时,人脸的所有样本都将在显示器上显示出来,降低了人脸错误检测的可能,一定程度上提高系统的准确性。
人脸的样本分辨率为24×24,作为576维的一维向量输入至PCA。图8(a)为计算PCA投影矩阵的流程图,图8(b)为KNN分类器的工作流程图,其中训练样本经过PCA投影后的数值,不需要在每次识别中重新计算,可以作为初始化时的计算,也可存储于掉电非易失介质中,如Flash存储器中,可以提高设备的运行效率,降低运算量。
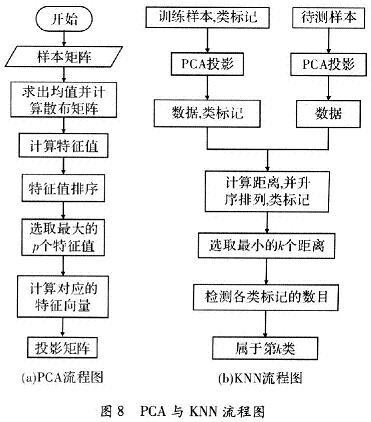
如图8所示,KNN分类器可以判断最接近的分类,但是并不能拒绝分类,于是产生了任何人的脸都将被分到内置样本集的一类中。这样的分类方式是不可取的,所以必须加入是否拒绝的判定,流程图如图9所示。
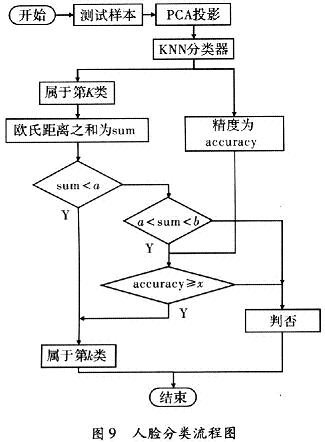
如流程图中显示,当样本点经过PCA降维后,输送至KNN分类器进行分类,所得到的结果一定可以判定为第K类,此时不能急于定论,先求出待测点与K类标号的样本点的欧氏距离之和sum。定义两个阈值a和b,如果sum<a值则判定为第一类;如果sum>b值则判定为拒绝类;如果sum介于a和b值之间,则引入精度控制量accuracy,计算出sum与a的差值,如若小于精度控制量accuracy,则判定为第K类,否则拒绝分类。由这样的过程,间接解决了样本错分和无法判否的问题。
4 试验结果
该实验中,选定a的值为12 400,b的值为16 200,这两个值的确定需要进行大量的实验,从中找出规律。x的值的大小直接影响识别的效果,文中分别选取x=4和x=5进行了测试。
(1)x=4时:程序在测试可识别库中的分属12个人的36幅人脸图像时,正确识别出其中的33幅,其余3幅图像均被判否,0个判错。程序在测试不可识别库中的分属3个人的33幅人脸图像时,22幅图像被成功判否,11幅被误判;
(2)x=5时:程序在测试可识别库中的分属12个人的36幅人脸图像时,正确识别出其中的25幅,其余ll幅图像均被判否,O幅判错。程序在测试不可识别库中的分属3个人的33幅人脸图像时,28幅图像被成功判否,5幅被误判。
分析上面的实验数据可知,x=4时,可识别库的识别率为91.6%,不可识别库的判否率为66.7%。x=5时,可识别库的识别率为69.4-%,不可识别库的判否率为84.8%。因此,应用于不同的场合时,应选择不同的x值,当要求尽可能拒绝外来人脸时,可选x值为5,当要求尽量识别已知人脸时,可选x值为4。
5 结束语
此人脸识别系统的构建,充分考虑了其推广性,未采用USB摄像头作为图像采集设备,而以通用视频标准的模拟摄像头取而代之,因此用户在摄像头选择的时候,可以更加自由。同时该设备支持多种接口输入,除了普通的R-jack口之外,还提供了Svideo,YPbPr和RGB等输入方式。该设备的识别精度可达90%以上,基本满足了识别要求。系统实时性好、携带方便,可以通过程序的修改推广到动态图像跟踪、运动检测等领域。
此内容为AET网站原创,未经授权禁止转载。