
可提高设计性能的HDL编程风格与技巧
2008-07-28
作者:Philippe Garraul
通过熟悉器件架构,选择合适的硬件平台和硅片特性,并借助配置恰当且性能优良的实现工具,设计人员就能获得较高的设计性能。不过,在提高设计性能的众多方法中最容易被忽视的也许就是为目标器件编写高效的HDL代码。本文所讨论的编程风格与技巧可提高设计性能。
使用复位对性能的影响
很少有哪种系统级的选择能够像复位选择那样对性能、面积和功率产生如此重要的影响。一些系统架构师规定必须使用系统全局异步复位" title="异步复位">异步复位。采用赛灵思" title="赛灵思">赛灵思的FPGA架构,复位的使用和类型将对代码性能产生重要影响。
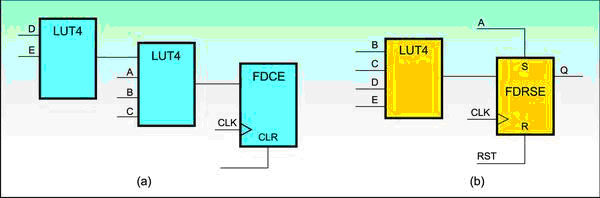
图a:综合工具" title="综合工具">综合工具选用2个LUT。图b:更灵活的LUT接口。
在目前所有的赛灵思FPGA架构中,查找表(LUT)单元就像逻辑、ROM/RAM或移位寄存器" title="移位寄存器">移位寄存器(SRL或移位寄存器LUT)那样是可配置的。综合工具可以根据RTL代码推断出采用某一种结构。不过,为了将LUT用作移位寄存器,代码中不能描述复位功能,因为SRL本身没有复位功能。这也意味着具有复位功能的移位寄存器代码不能获得最佳实现(移位寄存器之间需要多个触发器和相关路径),而没有复位功能的代码则可以获得快速而紧凑的实现结果(使用SRL)。
这两种情况对面积和功率的影响更明显一些,但对性能的影响不很明显。一般而言,采用触发器生成的移位寄存器不会成为设计中的关键路径,因为寄存器之间的时序路径通常没有足够的长度成为设计中最长的路径。而资源(触发器和布线)的额外消耗会对其它设计部分的布局和布线选择产生负面影响,因而可能导致更长的布线路径。
专用乘法器" title="乘法器">乘法器和RAM模块
乘法器通常用于DSP设计。但由于赛灵思的FPGA架构中包含有乘法专用资源,因此在许多设计中都有乘法器的应用。这些乘法器除了执行乘法操作外,还提供其它功能。同样地,实际上不管哪种应用,每个FPGA设计都会用到大小不一的RAM。
赛灵思FPGA包含几个RAM模块,在设计中可以用作RAM、ROM、大型LUT甚至通用逻辑。使用乘法器和RAM资源可获得更加紧凑、具有更高性能的设计,不过复位选择对性能既有正面的,也有负面的影响,具体取决于使用的复位类型。RAM和乘法器模块只包含同步复位,因此如果这些功能的代码用异步复位编写,那么这些模块中的寄存器就无法使用了。这对性能的影响是非常严重的。例如,Virtex-4器件的全管线式乘法器采用异步复位设计时,频率最高只能达到200MHz,而将代码改成同步复位后,性能可提高两倍以上,频率可达500MHz。
要从两个方面看待与RAM有关的问题。与乘法器类似,Virtex-4块RAM具有可选的输出寄存器,使用它们可以减少RAM的时钟到输出时间,提高整体设计速度。但这些寄存器只提供同步复位,不提供异步复位,因此当代码中的寄存器采用异步复位描述时就无法使用这些寄存器。
第二个问题来自RAM被用作LUT或通用逻辑时。有时基于面积和性能方面的考虑,将配置为ROM或通用逻辑的多个LUT压缩进单个块RAM是非常有益的。这可通过人工设定结构,或以自动方式将部分逻辑设计映射到未用的RAM存储区来实现。因为块RAM具有同步复位功能,因此当使用同步复位(或没有复位)时,无需改变已经定义好的设计功能就可实现通用逻辑的映射。但当采用异步复位描述时,这就不可能实现。
通用逻辑
异步复位对通用逻辑结构也会产生影响。由于所有的赛灵思FPGA通用寄存器都具有将复位/置位编程为异步或同步的能力,因此设计人员可能认为使用异步复位没什么不妥。但这种假设通常是错误的。如果没有使用异步复位,那么置位/复位逻辑就可以被置为同步逻辑。这样一来,就可释放额外的资源用于逻辑优化。
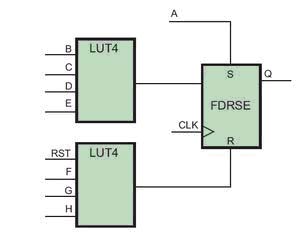
图d:选用同步复位。
为了更好地理解异步复位如何影响优化结果,我们来看看以下一些不够理想的代码例子:
VHDL例子#1
process (CLK, RST)
begin
if (RST = '1') then
Q <= '0';
elsif (CLK'event and CLK = '1') then
Q <= A or (B and C and D and E);
end if;
end process;
Verilog例子#1
always @(posedge CLK, posedge RST)
if (RESET)
Q <= 1'b0;
else
Q <= A | (B & C & D & E);
为实现这些代码,综合工具只能为数据路径选择两个LUT,因为总共有5个信号与实现上述逻辑功能相关。上述代码的一种可能性的实现方案如图a所示。
不过,如果采用同样的代码重新编写同步复位,则能进一步减少面积、提高性能,获得如下修正过的代码。
VHDL 例子#2
process (CLK)
begin
if (CLK'event and CLK = '1') then
if (RST = '1') then
Q <= '0';
else
Q <= A or (B and C and D and E);
end if;
end if;
end process;
Verilog 例子#2
always @(posedge CLK)
if (RESET)
Q <= 1'b0;
else
Q <= A | (B&C&D&E);
如今的综合工具在实现这种功能时具有了更大的灵活性。上述代码的一种可能性的实现方案如图b所示。
在该实现中,综合工具能够确定无论何时只要A是有效高电平,则Q总是逻辑1。其中寄存器与复位/置位一起被配置为同步操作,因此可以将置位功能自由地用作同步数据路径的一部分。这样可以减少实现该功能所必需的逻辑数量,并能减少来自前面例子的D和E信号的数据路径延时。如果代码能以更利于实现的方式编写,那么逻辑部分还可以转移到复位侧。
以下是对这些例子的补充:
VHDL例子#3
process (CLK, RST)
begin
if (RST = '1') then
Q <= '0';
elsif (CLK'event and CLK = '1') then
Q <= (F or G or H) and (A or (B and C
and D and E));
end if;
end process;
Verilog 例子#3
always @(posedge CLK, posedge RST)
if (RESET)
Q <= 1'b0;
else
Q <= (F|G|H) & (A | (B&C&D&E));
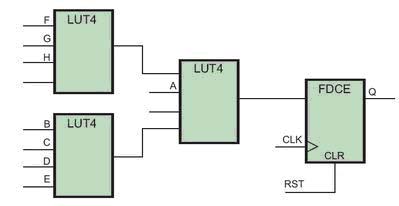
现在总共有8个信号与逻辑功能相关,因此实现该功能至少需要3个LUT。以上代码的一种可能性的实现方案如图c所示。
如果采用同样的代码编写同步复位,则有:
VHDL例子#4
process (CLK)
begin
if (CLK'event and CLK = '1') then
if (RST = '1') then
Q <= '0';
else
Q <= (F or G or H) and (A or (B and C
and D and E));
end if;
end if;
end process;
Verilog 例子#4
always @(posedge CLK)
if (RESET)
Q <= 1'b0;
else
Q <= (F|G|H) & (A | (B&C&D&E));
以上代码的一种可能性的实现方案如图d所示。其结果不仅是能够使用更少的LUT实现同样的逻辑功能,而且能够实现更快的设计,因为减少了实际创建该功能的每个信号的逻辑级数。
虽然这些例子非常简单,但它们能够很好地阐明我们的观点,即异步复位如何将所有的同步数据信号加载到寄存器的输入端,从而导致可能更多的逻辑级数以及不够完善的实现结果。一般而言,扇入逻辑功能的信号越多,同步复位/置位在减少逻辑资源或提高设计性能方面越有效。
用加法器链代替加法器树
许多信号处理算法都是对输入的采样数据流进行某种算术运算,然后将这种算术运算的所有输出进行累加。加法树结构一般是用来实现并行结构(如FPGA)中的这种累加运算。
加法器树概念的一个难点在于其数量会经常变化。加法器的数量取决于加法器树的输入信号数量。加法器树中的输入越多,需要的加法器数量也越多,需要的逻辑资源和功耗也就越多。树越大意味着树的最后一级加法器也越大,因而会进一步降低系统性能。
为了减少功耗,保持较高的系统性能,加法器树应作为专门的硅资源加以实现。但在硅片中放置大量固定尺寸的加法器树元件并不很有效,因为当加法超过一定数量时必须使用逻辑资源,甚至采用更大的FPGA,因而会增加器件的成本。
采用DSP48系列专用硅片组的Virtex-4系列器件则采用不同的方法实现累加。它采用链状加法器代替加法器树进行增量式累加运算。这种方法有别于任何现有的FPGA,是提升器件性能、降低DSP算法所需功耗的关键,因为逻辑与互连功能被完全集成进专用硅片中。
采用管线形式的DSP48模块频率可达500MHz,而与加法器数量无关。如图5所示,级联端口以及48位分辨率的加法器/累加器完全能够胜任目前的采样值计算,并完成迄今为止所有计算采样值的累加。
为了充分利用RTL中的Virtex-4加法器链结构,只需简单地用加法器链描述替代加法器树描述。这种将将直接型滤波器转换成转置型或脉动型滤波器的过程在XtremeDSP设计用户指南中有详细介绍。
一旦转换完成后,你会发现算法的运行速度要比应用所需的快得多。在这种情况下,可以使用合并或多信道技术进一步减少器件使用率和功耗。这两种技术都可以采用更小的器件实现设计,或者使用空余资源增加设计功能。
多信道技术可以将非常快的运算单元作用于多个采样速率很慢的输入流(信道)上。这种技术对硅片效率的提高幅度几乎等于信道数量。多信道滤波器可以看作是时间复接的单信道滤波器。例如,在一个典型的多信道滤波环境中,对多个输入信道中的每个信道都使用独立的数字滤波器进行滤波。为了充分发挥Virtex-4 DSP48模块的性能优势,只需为单滤波器提供8倍的时钟,设计人员即可使用一个单数字滤波器完成对所有8个输入信道的滤波,而所需的FPGA资源数量几乎可以减少8倍。
提高块RAM性能
在选用存储器单元时,影响性能的因素有:使用专用模块还是分布式模块;RAM;使用输出管线寄存器;不使用异步复位。此外,还有两个不大为人所知的因素,即HDL编程风格和综合工具设置,这些也会极大地影响存储器性能。
HDL编程风格
当选用双端口模块存储器时,很可能两个端口同时访问同一存储器单元。当两个端口同时向相同存储器单元写入不同的值时就会产生冲突,此时存储器单元的内容是无法得到保证的。不过,当一个端口在读,同时另一个端口在写相同地址时又会发生什么情况呢?这要取决于目标器件。最新的Virtex和Spartan系列器件有三种可编程操作模式可以控制写操作进行时存储器的输出。有关这三种操作模式的详细信息请参阅器件的用户指南。
图5:链状加法器能提供可预测的性能。
需要注意的是,不同模式会影响存储器的输出行为,也会影响存储器的性能。如同下面所举的例子,编程风格决定了存储器工作在何种工作模式下:
//先写或透明模式(transparent mode)
always @(posedge clk) begin
if(we) begin
do <= data;
mem[address] <= data;
end else
do <= mem[address];
end
//先读或写前读模式
always @(posedge clk) begin
if (we)
mem[address] <= data;
do <= mem[address];
end
//不变模式
always @(posedge clk)
if (we)
mem[address] <= data;
else
do <= mem[address];
end
增加管线级数
另外一种提高性能的方法是重新构建由多级逻辑组成的长数据路径,将它们分解成多个时钟周期进行处理。这种方法允许使用更快的时钟周期,并可提高数据吞吐量,其代价是时延和管线管理开销逻辑。因为FPGA中的寄存器非常多,因此额外的寄存器和开销逻辑一般不成问题。
由于数据目前处于多周期路径上,因此设计人员必须采用特殊方法才能解决额外的时延问题。下面的例子采用在32x32乘法器输出端增加5级寄存器的编程风格。综合工具将把这些寄存器以管线形式关联到Virtex-4 DSP48模块中可用的寄存器,从而极大地提高了数据吞吐量。
// 带有4个DSP48模块的32x32乘法器
always @(posedge clk) begin
prod[0] <= a * b;
for (i=1; i<=PIPE-1; i=i+1)
prod[i] <= prod[i-1];
end
代码中的嵌套
代码中尽量不要设置太多的嵌套,例如嵌套的if和case语句。若在某条if语句中有太多的if语句,则不利于实现综合优化。如果遵循以下指导原则,代码的可读性会更强。当在HDL中描述“for-loops”语句时,最好在数据路径中放置至少一个寄存器,特别是有算术或其它逻辑多的操作时。在编译时,综合工具会解开环路。如果没有这些同步单元,它会级联环路每次反复时创建的逻辑,从而导致组合路径过长,降低设计性能。
本文小结
综合、布局和布线算法中的最新发展可使我们更直接地从特殊器件中获得最佳性能。综合工具可以选用复杂的算术和存储器描述并映射到专门的硬件模块上。它们也能执行再定时、逻辑和寄存器复制等优化操作。布局布线工具可以在时序约束的基础上重建网表,执行以时序为主导的封装和布局,从而减少布局布线拥塞。
不过,目前的工具在提高性能方面只能做到这么多。如果需要更高性能的设计,最有效的方法莫过于更好地理解目标器件、综合工具,并采用本文提供的编码指南。